Google Cloud Compute Options
📌 Updated June 2026: This post has been updated to reflect major Google Cloud compute changes including Cloud Functions rebranding to Cloud Run functions (Aug 2024), Cloud Run worker pools (GA 2026), GPU support on Cloud Run, GKE Autopilot as default mode, new Axion-based machine types, and App Engine legacy runtime deprecations.
Compute Engine
- provides Infrastructure as a Service (IaaS) in the Google Cloud
- offers scalable, high performance virtual machines (VMs) on Google’s infrastructure.
- provides full control/flexibility on the choice of OS, resources like CPU and memory
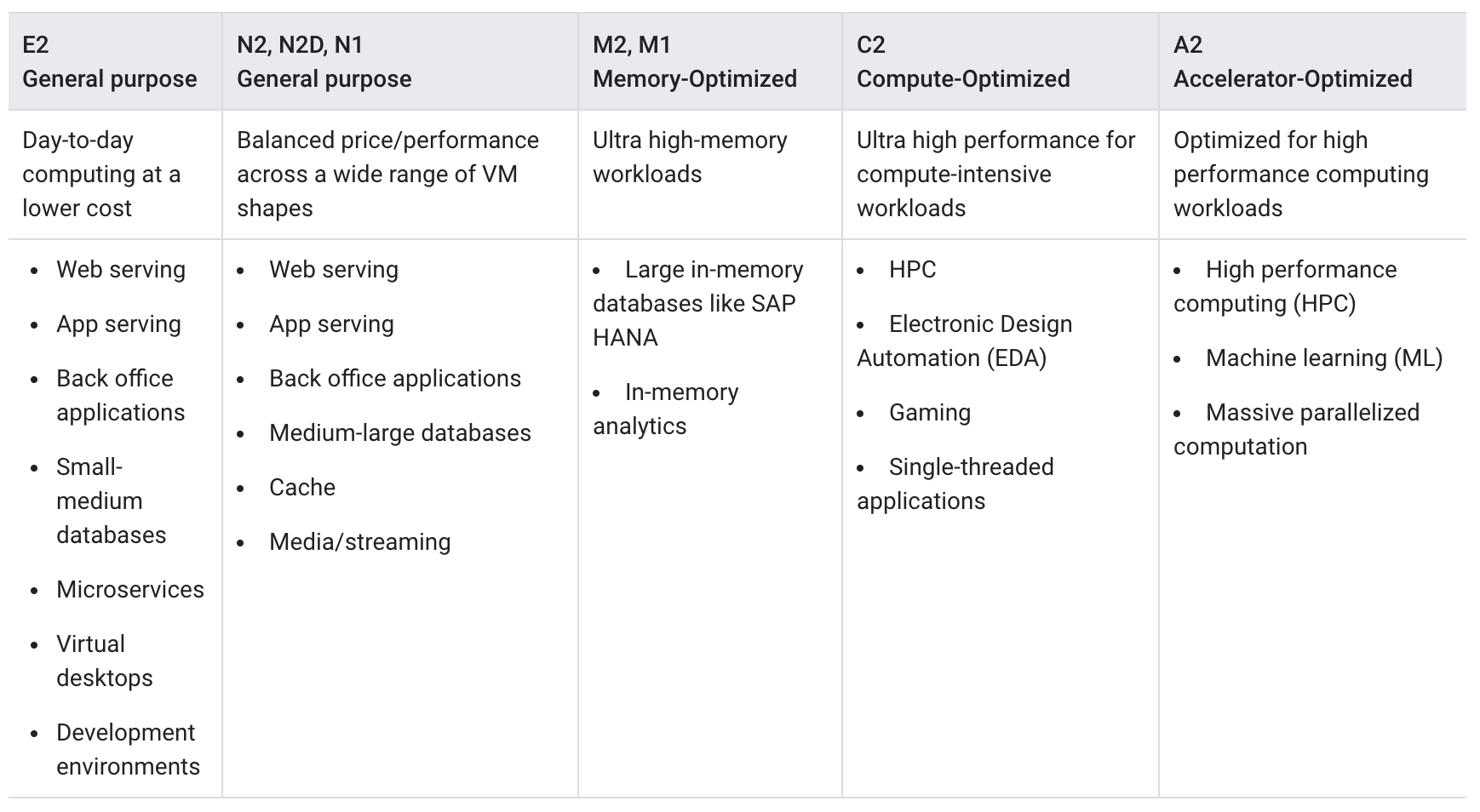
- supports a wide range of machine families:
- General-purpose: E2, N2, N2D, N4, N4A (Axion/Arm-based), C4, C4A (Axion/Arm-based), C4D
- Compute-optimized: C2, C2D, H3
- Memory-optimized: M1, M2, M3
- Accelerator-optimized: A2, A3, G2 (with NVIDIA GPUs)
- New (2024-2026):
- Google Axion Processors – custom Arm-based processors powering C4A and N4A instances, delivering up to 65% better price-performance and 60% greater energy efficiency than comparable x86 systems
- C4 VMs – latest Intel-based general-purpose VMs with Google Titanium system offload
- C4D VMs – AMD-based with confidential computing support, up to 384 vCPUs and 3TB DDR5 memory
- N4A VMs – most cost-effective N-series VM, up to 2x better price-performance than comparable x86 VMs (GA 2025)
- Usage patterns
- lift and shift migrations of existing systems
- existing VM images to move to the cloud
- need low-level access to or fine-grained control of the operating system, network, and other operational characteristics
- require custom kernel or arbitrary OS
- software that can’t be easily containerized
- using a third party licensed software
- AI/ML training workloads requiring GPU accelerators
- Usage anti-patterns
- containerized applications – Choose GKE or Cloud Run
- stateless event-driven applications – Choose Cloud Run functions
- simple web applications – Choose App Engine or Cloud Run
App Engine
- is a platform as a service (PaaS) for developing and hosting web applications.
- helps build highly scalable web and mobile backend applications on a fully managed serverless platform
- developers can focus on writing code without having to manage the underlying infrastructure.
- offers two environments:
- Standard environment – applications run in a sandbox, supports specific runtimes, faster scaling including scale to zero
- Flexible environment – applications run in Docker containers on Compute Engine VMs, supports any runtime
- Runtime Updates (2024-2026):
- Legacy runtimes (Python 2.7, Java 8, Go 1.11, PHP 5.5) reached end of support on January 30, 2024 – existing apps continue to run but re-deployment may be blocked
- Go 1.11 and PHP 5.5 runtimes deprecated on January 31, 2026
- Migration to second-generation runtimes is recommended
- Latest supported runtimes include Python 3.12+, Java 21+, Node.js 20+, Go 1.22+, PHP 8.3+, Ruby 3.3+
- Usage patterns
- Rapidly developing CRUD-heavy applications
- HTTP/S based applications
- Deploying complex APIs
- Applications needing automatic scaling without container management
- Usage anti-patterns
- Stateful applications requiring lots of in-memory states to meet the performance or functional requirements
- Systems that require protocols other than HTTP
- Applications requiring container-level customization – Choose Cloud Run
- Note: For new projects, Google recommends evaluating Cloud Run as a more flexible alternative to App Engine, with an official migration guide available.
Google Kubernetes Engine – GKE
- provides a managed environment for deploying, managing, and scaling containerized applications using Google infrastructure.
- available in two modes:
- Autopilot (recommended, default since 2023) – fully managed, Google configures and manages nodes, node pools, and in-cluster policy. Pay per pod resource requests.
- Standard – user manages nodes and node configuration. More flexibility but more operational overhead.
- GKE Updates (2024-2026):
- Autopilot is now default mode for new cluster creation (30% of active GKE clusters used Autopilot in 2024)
- Autopilot compute classes now available for Standard clusters – turn on Autopilot per-workload basis (KubeCon EU 2026)
- GKE Enterprise (formerly Anthos) – enterprise tier for governing, managing, and operating workloads at scale across hybrid/multi-cloud
- AI/ML workload support – 66% of organizations rely on Kubernetes for generative AI apps and agents (2026)
- Multi-agent AI workflows surged 327% in early 2026
- Usage patterns
- containerized applications or those that can be easily containerized
- Hybrid or multi-cloud environments (with GKE Enterprise)
- Systems leveraging stateful and stateless services
- Strong CI/CD Pipelines
- AI/ML workloads requiring GPU orchestration at scale
- Microservices architectures requiring service mesh
- Usage anti-patterns
- non-containerized applications – Choose Compute Engine or App Engine
- applications requiring very low-level access to the underlying hardware like custom kernel, networking, etc. – Choose Compute Engine
- stateless event-driven applications – Choose Cloud Run functions
- simple stateless containerized apps not requiring Kubernetes features – Choose Cloud Run
Cloud Run
- is a fully managed application platform for running code, functions, or containers on Google’s highly scalable infrastructure.
- allows developers to build applications in any programming language and deploy them in seconds.
- abstracts away all infrastructure management allowing users to focus on building applications.
- is built from Knative.
- Three resource types (2024-2026):
- Services – responds to HTTP requests using stateless instances that autoscale (including scale to zero). Also handles events and functions.
- Jobs – executes parallelizable tasks manually or on a schedule that run to completion.
- Worker Pools (GA 2026) – handles always-on background workloads such as pull-based workloads (e.g., Kafka consumers, Pub/Sub pull queues, RabbitMQ consumers). Does NOT have a load-balanced endpoint or autoscale automatically.
- Key Features (2024-2026):
- GPU support – on-demand access to NVIDIA L4 GPUs for AI inference workloads, instances start in 5 seconds and scale to zero
- Cloud Run functions – Cloud Functions rebranded and merged into Cloud Run (August 2024), same event-driven model with Cloud Run’s configurability
- Sidecars – multi-container deployments with independent sidecar containers alongside main container
- Always-on CPU allocation – CPU available even between requests for background processing
- Volume mounts – Cloud Storage, NFS, in-memory, CIFS/SMB, and Ephemeral Disk support
- Manual scaling option – override automatic scaling for predictable workloads
- WebSocket and gRPC support – full support for real-time communication
- Source-based deployment – deploy directly from source code without building containers
- AI/ML workloads – run LLM inference (Ollama, Gemma), AI agents (ADK, A2A), and MCP servers
- Usage patterns
- Stateless services that are easily containerized
- Event-driven applications and systems
- Applications that require custom system and language dependencies
- AI inference workloads (with GPU support)
- Background processing (worker pools for Kafka consumers, message queues)
- Batch processing (jobs with parallelism)
- Websites, APIs, and microservices
- Usage anti-patterns
- Applications requiring persistent VMs with custom kernels – Choose Compute Engine
- Complex container orchestration requiring Kubernetes features – Choose GKE
- Applications requiring strict low-level infrastructure control
Cloud Run Functions (formerly Cloud Functions)
⚠️ Rebranding Notice (August 2024): Google Cloud Functions has been renamed to Cloud Run functions and merged under the Cloud Run platform. The event-driven programming model remains the same, but functions now run on Cloud Run infrastructure with its full configurability. The
gcloud functions CLI and APIs continue to work.
- offers scalable pay-as-you-go Functions as a Service (FaaS) to run code with zero server management.
- provides a serverless execution environment for building and connecting Cloud services.
- provides serverless compute for event-driven apps.
- developers can focus on writing code without having to manage the underlying infrastructure.
- Two generations:
- Cloud Run functions (formerly 2nd gen / Cloud Functions 2nd gen) – runs on Cloud Run infrastructure, supports longer timeouts (up to 60 min), larger instances (up to 32 GB RAM, 8 vCPUs), concurrency, traffic splitting, and Direct VPC egress
- Cloud Run functions (1st gen) (formerly Cloud Functions 1st gen) – original version with limited event triggers and configurability, limited to 9 min timeout and 8 GB RAM
- Usage patterns
- ephemeral and event-driven applications and functions
- fully managed environment
- pay only for what you use
- quick data transformations (ETL)
- Webhooks and lightweight APIs
- Responding to Cloud Storage, Pub/Sub, Firestore, or Firebase events
- Usage anti-patterns
- continuous stateful application – Choose Compute Engine, App Engine, or GKE
- long-running background processing – Choose Cloud Run worker pools
- applications requiring multiple containers or sidecars – Choose Cloud Run services
Google Cloud Compute Options Comparison
| Feature | Compute Engine | GKE | App Engine | Cloud Run | Cloud Run Functions |
|---|---|---|---|---|---|
| Type | IaaS | CaaS (Container) | PaaS | Serverless Containers | FaaS |
| Abstraction Level | VMs | Containers/Pods | Application | Container/Source | Function |
| Scaling | Autoscaler (MIGs) | Pod/Node Autoscaler | Automatic | Automatic (0 to N) | Automatic (0 to N) |
| Scale to Zero | No | No (pods stay) | Yes (Standard) | Yes | Yes |
| GPU Support | Yes | Yes | No | Yes (NVIDIA L4) | No |
| Max Timeout | Unlimited | Unlimited | 60 min | 60 min (services) | 60 min (2nd gen) |
| Pricing | Per VM (sec) | Per node + mgmt fee | Per instance-hour | Per request/instance | Per invocation + time |

Google Cloud Compute Options Decision Tree
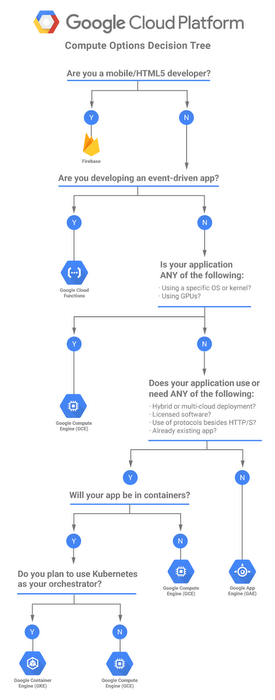
Key Decision Criteria
- Need full VM control? → Compute Engine
- Containerized app needing Kubernetes features (service mesh, complex networking, stateful sets)? → GKE
- Simple containerized app, HTTP-driven? → Cloud Run (services)
- Background pull-based processing (Kafka, queues)? → Cloud Run (worker pools)
- Batch/parallel tasks running to completion? → Cloud Run (jobs)
- Event-driven single-purpose functions? → Cloud Run functions
- Quick PaaS web app without container knowledge? → App Engine
- AI inference with serverless GPU? → Cloud Run with GPU
- AI training at scale with GPU orchestration? → GKE or Compute Engine
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your organization is developing a new application. This application responds to events created by already running applications. The business goal for the new application is to scale to handle spikes in the flow of incoming events while minimizing administrative work for the team. Which Google Cloud product or feature should you choose?
- Cloud Run
- Cloud Run for Anthos (Note: Cloud Run for Anthos has been deprecated and archived. It is now referred to as Knative serving on GKE.)
- App Engine standard environment
- Compute Engine
- A company wants to build an application that stores images in a Cloud Storage bucket and wants to generate thumbnails as well as resize the images. They want to use managed service which will help them scale automatically from zero to scale and back to zero. Which GCP service satisfies the requirement?
- Google Compute Engine
- Google Kubernetes Engine
- Google App Engine
- Cloud Run functions (formerly Cloud Functions)
- A startup needs to deploy a containerized machine learning inference model that requires GPU access, should scale to zero when not in use, and needs to start serving requests within seconds. Which compute option is most suitable?
- Compute Engine with GPU attached
- GKE with GPU node pool
- Cloud Run with GPU (NVIDIA L4)
- App Engine flexible environment
- Your team has a Kafka consumer application that needs to continuously process messages from a topic. The application does not serve HTTP requests. You want to use a serverless managed platform. Which Cloud Run resource type should you use?
- Cloud Run service
- Cloud Run job
- Cloud Run worker pool
- Cloud Run functions
- A company is running multiple microservices across on-premises data centers and Google Cloud. They need a consistent container orchestration platform with centralized policy management across all environments. Which solution should they use?
- Cloud Run
- App Engine flexible
- GKE Enterprise (formerly Anthos)
- Compute Engine managed instance groups
- You are designing a new serverless application that processes files uploaded to Cloud Storage. The processing takes about 30 seconds per file and you want minimal operational overhead. Which option is most appropriate?
- Compute Engine with a cron job
- Cloud Run functions triggered by Cloud Storage event
- GKE CronJob
- App Engine Standard with task queue
- Your team needs to run a data migration script that processes 10,000 records in parallel and should complete execution. The script does not need to serve HTTP traffic. Which Cloud Run resource type is best suited?
- Cloud Run service with always-on CPU
- Cloud Run job with parallelism
- Cloud Run worker pool
- Cloud Run functions
- A company wants to use Google’s custom Arm-based processors for their web servers to optimize cost and energy efficiency. Which instance family should they choose?
- N2 instances
- C2 instances
- C4A instances (Google Axion)
- E2 instances