Cloud Bigtable is a fast, fully-managed, highly scalable NoSQL database service. It is designed for the collection and retention of data from 1TB to hundreds of PB.
BigQuery is a fully managed, durable, petabyte scale, serverless, highly scalable, and cost-effective multi-cloud data warehouse.
supports a standard SQL dialect
automatically replicates data and keeps a seven-day history of changes, allowing easy restoration and comparison of data from different times
supports federated data and can process external data sources in GCS for Parquet and ORC open-source file formats, transactional databases (Bigtable, Cloud SQL), or spreadsheets in Drive without moving the data.
Data model consists of Datasets, tables
BigQuery performance can be improved using Partitioned tables and Clustered tables.
BigQuery encrypts all data at rest and supports encryption in transit.
BigQuery Data Transfer Service automates data movement into BigQuery on a scheduled, managed basis
Best Practices
Control projection, avoid select *
Estimate costs as queries are billed according to the number of bytes read and the cost can be estimated using --dry-run feature
Use the maximum bytes billed setting to limit query costs.
Use clustering and partitioning to reduce the amount of data scanned.
Avoid repeatedly transforming data via SQL queries. Materialize the query results in stages.
Use streaming inserts only if the data must be immediately available as streaming data is charged.
Prune partitioned queries, use the _PARTITIONTIME pseudo column to filter the partitions.
Denormalize data whenever possible using nested and repeated fields.
Avoid external data sources, if query performance is a top priority
Avoid using Javascript user-defined functions
Optimize Join patterns. Start with the largest table.
Use the expiration settings to remove unneeded tables and partitions
Keep the data in BigQuery to take advantage of the long-term storage cost benefits rather than exporting to other storage options.
Bigtable is a fully managed, scalable, wide-column NoSQL database service with up to 99.999% availability.
ideal for applications that need very high throughput and scalability for key/value data, where each value is max. of 10 MB.
supports high read and write throughput at low latency and provides consistent sub-10ms latency – handles millions of requests/second
is a sparsely populated table that can scale to billions of rows and thousands of columns,
supports storage of terabytes or even petabytes of data
is not a relational database. It does not support SQL queries, joins, or multi-row transactions.
handles upgrades and restarts transparently, and it automatically maintains high data durability.
scales linearly in direct proportion to the number of nodes in the cluster
stores data in tables, which is composed of rows, each of which typically describes a single entity, and columns, which contain individual values for each row.
Each table has only one index, the row key. There are no secondary indices. Each row key must be unique.
Single-cluster Bigtable instances provide strong consistency.
Multi-cluster instances, by default, provide eventual consistency but can be configured to provide read-over-write consistency or strong consistency, depending on the workload and app profile settings
Cloud Dataflow is a managed, serverless service for unified stream and batch data processing requirements
provides Horizontal autoscaling to automatically choose the appropriate number of worker instances required to run the job.
is based on Apache Beam, an open-source, unified model for defining both batch and streaming-data parallel-processing pipelines.
supports Windowing which enables grouping operations over unbounded collections by dividing the collection into windows of finite collections according to the timestamps of the individual elements.
supports drain feature to deploy incompatible updates
Cloud Dataproc is a managed Spark and Hadoop service to take advantage of open-source data tools for batch processing, querying, streaming, and machine learning.
helps to create clusters quickly, manage them easily, and save money by turning clusters on and off as needed.
helps reduce time on time and money spent on administration and lets you focus on your jobs and your data.
has built-in integration with other GCP services, such as BigQuery, Cloud Storage, Bigtable, Cloud Logging, and Monitoring
support preemptible instances that have lower compute prices to reduce costs further.
also supports HBase, Flink, Hive WebHcat, Druid, Jupyter, Presto, Solr, Zepplin, Ranger, Zookeeper, and much more.
supports connectors for BigQuery, Bigtable, Cloud Storage
can be configured for High Availability by specifying the number of master instances in the cluster
All nodes in a High Availability cluster reside in the same zone. If there is a failure that impacts all nodes in a zone, the failure will not be mitigated.
supports cluster scaling by increasing or decreasing the number of primary or secondary worker nodes (horizontal scaling)
supports Autoscaling provides a mechanism for automating cluster resource management and enables cluster autoscaling.
supports initialization actions in executables or scripts that will run on all nodes in the cluster immediately after the cluster is set up
Cloud Dataprep
Cloud Dataprep by Trifacta is an intelligent data service for visually exploring, cleaning, and preparing structured and unstructured data for analysis, reporting, and machine learning.
is fully managed, serverless, and scales on-demand with no infrastructure to deploy or manage
provides easy data preparation with clicks and no code.
automatically identifies data anomalies & helps take fast corrective action
automatically detects schemas, data types, possible joins, and anomalies such as missing values, outliers, and duplicates
uses Dataflow or BigQuery under the hood, enabling unstructured or structured datasets processing of any size with the ease of clicks, not code
Datalab
Cloud Datalab is a powerful interactive tool created to explore, analyze, transform and visualize data and build machine learning models using familiar languages, such as Python and SQL, interactively.
runs on Google Compute Engine and connects to multiple cloud services easily so you can focus on your data science tasks.
is built on Jupyter (formerly IPython)
enables analysis of the data on Google BigQuery, Cloud Machine Learning Engine, Google Compute Engine, and Google Cloud Storage using Python, SQL, and JavaScript (for BigQuery user-defined functions).
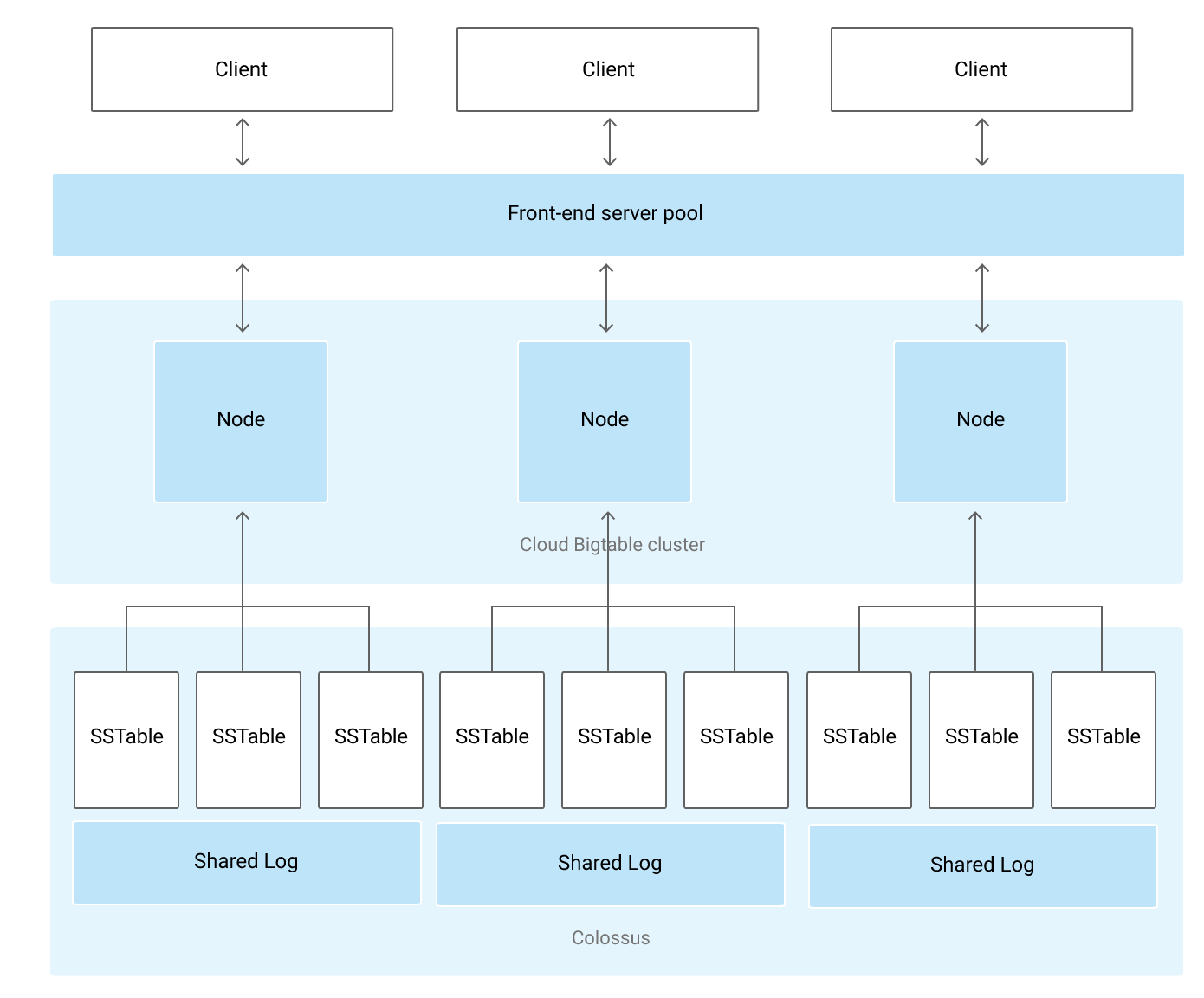
Clusters handle the requests sent to a single Bigtable instance
Each cluster belongs to a single Bigtable instance, and an instance can have up to 4 clusters
Each cluster is located in a single-zone
Bigtable instances with only 1 cluster do not use replication
An Instances with multiple clusters replicate the data, which
improves data availability and durability
improves scalability by routing different types of traffic to different clusters
provides failover capability, if another cluster becomes unavailable
If multiple clusters within an instance, Bigtable automatically starts replicating the data by keeping separate copies of the data in each of the clusters’ zones and synchronizing updates between the copies
Nodes
Each cluster in an instance has 1 or more nodes, which are the compute resources that Bigtable uses to manage the data.
Each node in the cluster handles a subset of the requests to the cluster
All client requests go through a front-end server before they are sent to a Bigtable node.
Bigtable separates the Compute from the Storage. Data is never stored in nodes themselves; each node has pointers to a set of tablets that are stored on Colossus. This helps as
Rebalancing tablets from one node to another is very fast, as the actual data is not copied. Only pointers for each node are updated
Recovery from the failure of a Bigtable node is very fast as only the metadata needs to be migrated to the replacement node.
When a Bigtable node fails, no data is lost.
A Bigtable cluster can be scaled by adding nodes which would increase
the number of simultaneous requests that the cluster can handle
the maximum throughput of the cluster.
Each node is responsible for:
Keeping track of specific tablets on disk.
Handling incoming reads and writes for its tablets.
Performing maintenance tasks on its tablets, such as periodic compactions
Bigtable nodes are also referred to as tablet servers
Tables
Bigtable stores data in massively scalable tables, each of which is a sorted key/value map.
A Table belongs to an instance and not to the cluster or node.
A Bigtable table is sharded into blocks of contiguous rows, called tablets, to help balance the workload of queries.
Bigtable splits all of the data in a table into separate tablets.
Tablets are stored on the disk, separate from the nodes but in the same zone as the nodes.
Each tablet is associated with a specific Bigtable node.
Tablets are stored in SSTable format which provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings.
In addition to the SSTable files, all writes are stored in Colossus’s shared log as soon as they are acknowledged by Bigtable, providing increased durability.
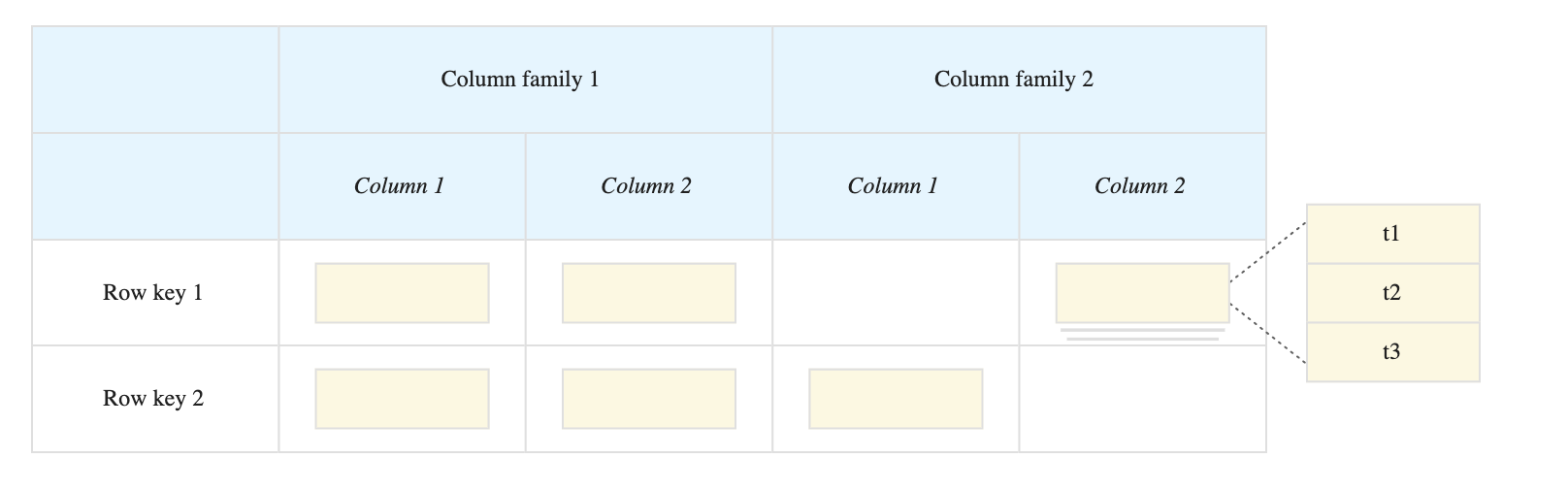
Bigtable Storage Model
Bigtable stores data in tables, each of which is a sorted key/value map.
A Table is composed of rows, each of which typically describes a single entity, and columns, which contain individual values for each row.
Each row is indexed by a single row key, and columns that are related to one another are typically grouped together into a column family.
Each column is identified by a combination of the column family and a column qualifier, which is a unique name within the column family.
Each row/column intersection can contain multiple cells.
Each cell contains a unique timestamped version of the data for that row and column.
Storing multiple cells in a column provides a record of how the stored data for that row and column has changed over time.
Bigtable tables are sparse; if a column is not used in a particular row, it does not take up any space.
Bigtable Schema Design
Bigtable schema is a blueprint or model of a table that includes Row Keys, Column Families, and Columns
Bigtable is a key/value store, not a relational store. It does not support joins, and transactions are supported only within a single row.
Each table has only one index, the row key. There are no secondary indices. Each row key must be unique.
Rows are sorted lexicographically by row key, from the lowest to the highest byte string. Row keys are sorted in big-endian byte order, the binary equivalent of alphabetical order.
Column families are not stored in any specific order.
Columns are grouped by column family and sorted in lexicographic order within the column family.
Intersection of a row and column can contain multiple timestamped cells. Each cell contains a unique, timestamped version of the data for that row and column.
All operations are atomic at the row level. This means that an operation affects either an entire row or none of the row.
Bigtable tables are sparse. A column doesn’t take up any space in a row that doesn’t use the column.
Bigtable Replication
Bigtable Replication helps increase the availability and durability of the data by copying it across multiple zones in a region or multiple regions.
Replication helps isolate workloads by routing different types of requests to different clusters using application profiles.
Bigtable replication can be implemented by
creating a new instance with more than 1 cluster or
adding clusters to an existing instance.
Bigtable synchronizes the data between the clusters, creating a separate, independent copy of the data in each zone with the instance cluster.
Replicated clusters in different regions typically have higher replication latency than replicated clusters in the same region.
Bigtable replicates any changes to the data automatically, including all of the following types of changes:
Updates to the data in existing tables
New and deleted tables
Added and removed column families
Changes to a column family’s garbage collection policy
Bigtable treats each cluster in the instance as a primary cluster, so reads and writes can be performed in each cluster.
Application profiles can be created so that the requests from different types of applications are routed to different clusters.
Consistency Model
Eventual Consistency
Replication for Bigtable is eventually consistent, by default.
Read-your-writes Consistency
Bigtable can also provide read-your-writes consistency when replication is enabled, which ensures that an application will never read data that is older than its most recent writes.
To gain read-your-writes consistency for a group of applications, each application in the group must use an app profile that is configured for single-cluster routing, and all of the app profiles must route requests to the same cluster.
You can use the instance’s additional clusters at the same time for other purposes.
Strong Consistency
For some replication use cases, Bigtable can also provide strong consistency, which ensures that all of the applications see the data in the same state.
To gain strong consistency, you use the single-cluster routing app-profile configuration for read-your-writes consistency, but you must not use the instance’s additional clusters unless you need to failover to a different cluster.
Use cases
Isolate real-time serving applications from batch reads
Improve availability
Provide near-real-time backup
Ensure your data has a global presence
Bigtable Best Practices
Store datasets with similar schemas in the same table, rather than in separate tables as in SQL.
Bigtable has a limit of 1,000 tables per instance
Creating many small tables is a Bigtable anti-pattern.
Put related columns in the same column family
Create up to about 100 column families per table. A higher number would lead to performance degradation.
Choose short but meaningful names for your column families
Put columns that have different data retention needs in different column families to limit storage cost.
Create as many columns as you need in the table. Bigtable tables are sparse, and there is no space penalty for a column that is not used in a row
Don’t store more than 100 MB of data in a single row as a higher number would impact performance
Don’t store more than 10 MB of data in a single cell.
Design the row key based on the queries used to retrieve the data
Following queries provide the most efficient performance
Row key
Row key prefix
Range of rows defined by starting and ending row keys
Other types of queries trigger a full table scan, which is much less efficient.
Store multiple delimited values in each row key. Multiple identifiers can be included in the row key.
Use human-readable string values in your row keys whenever possible. Makes it easier to use the Key Visualizer tool.
Row keys anti-pattern
Row keys that start with a timestamp, as it causes sequential writes to a single node
Row keys that cause related data to not be grouped together, which would degrade the read performance
Sequential numeric IDs
Frequently updated identifiers
Hashed values as hashing a row key removes the ability to take advantage of Bigtable’s natural sorting order, making it impossible to store rows in a way that are optimal for querying
Values expressed as raw bytes rather than human-readable strings
Domain names, instead use the reverse domain name as the row key as related data can be clubbed.
Bigtable Load Balancing
Each Bigtable zone is managed by a primary process, which balances workload and data volume within clusters.
This process redistributes the data between nodes as needed as it
splits busier/larger tablets in half and
merges less-accessed/smaller tablets together
Bigtable automatically manages all of the splitting, merging, and rebalancing, saving users the effort of manually administering the tablets
Bigtable write performance can be improved by distributed writes as evenly as possible across nodes with proper row key design.
Bigtable Consistency
Single-cluster instances provide strong consistency.
Multi-cluster instances, by default, provide eventual consistency but can be configured to provide read-over-write consistency or strong consistency, depending on the workload and app profile settings
All data stored within Google Cloud, including the data in Bigtable tables, is encrypted at rest using Google’s default encryption.
Bigtable supports using customer-managed encryption keys (CMEK) for data encryption.
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your company processes high volumes of IoT data that are time-stamped. The total data volume can be several petabytes. The data needs to be written and changed at a high speed. You want to use the most performant storage option for your data. Which product should you use?
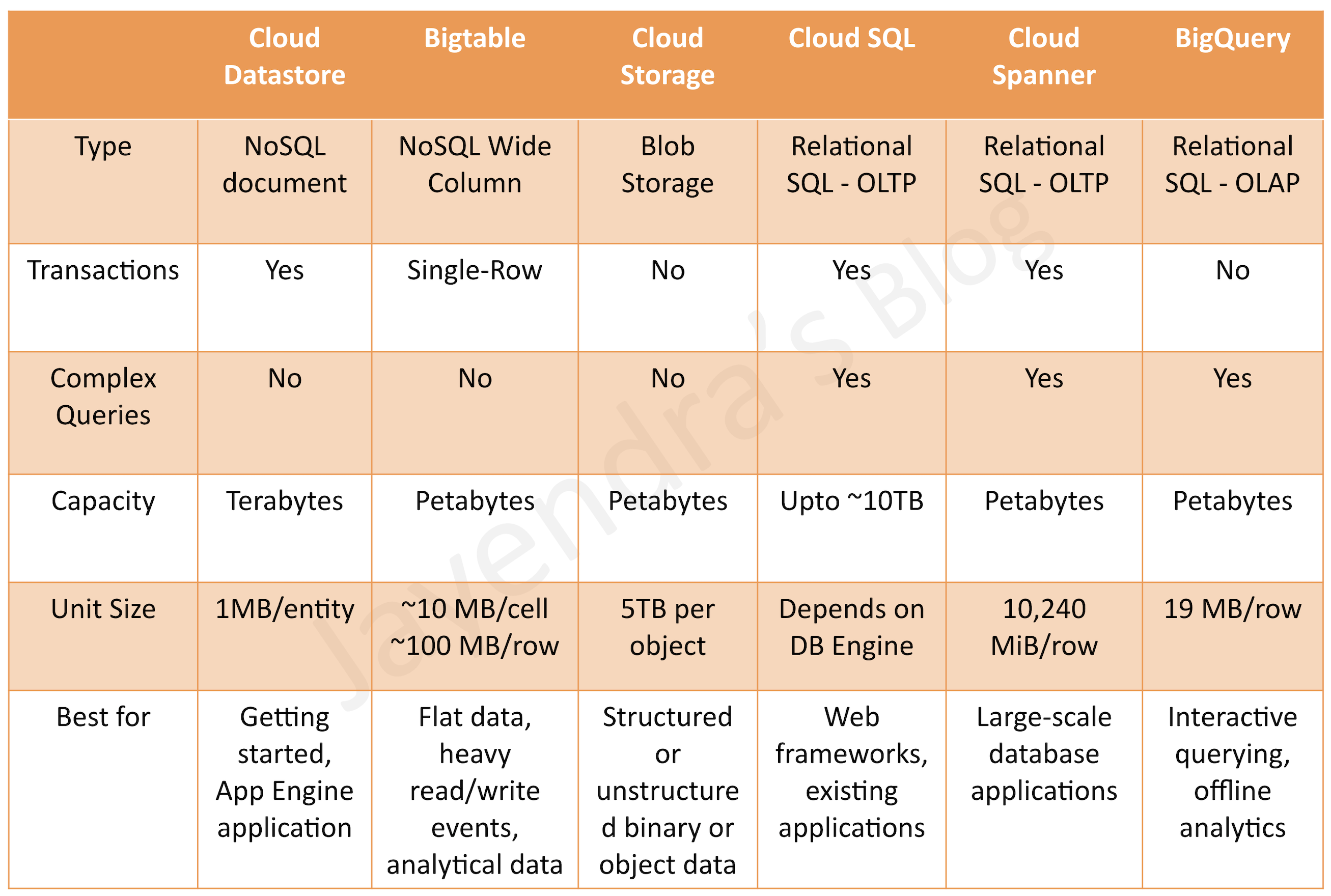
Cloud Datastore
Cloud Storage
Cloud Bigtable
BigQuery
You want to optimize the performance of an accurate, real-time, weather-charting application. The data comes from 50,000 sensors sending 10 readings a second, in the format of a timestamp and sensor reading. Where should you store the data?
Google BigQuery
Google Cloud SQL
Google Cloud Bigtable
Google Cloud Storage
Your team is working on designing an IoT solution. There are thousands of devices that need to send periodic time series data for
processing. Which services should be used to ingest and store the data?
Bigtable provides a scalable, fully managed, non-relational NoSQL wide-column analytical big data database service suitable for both low-latency single-point lookups and precalculated analytics.
supports large quantities (>1 TB) of semi-structured or structured data (vs Datastore)
supports high throughput or rapidly changing data (vs BigQuery)
managed, but needs provisioning of nodes and can be expensive (vs Datastore and BigQuery)
does not support transactions or strong relational semantics (vs Datastore)
does not support SQL queries (vs BigQuery and Datastore)
Not Transactional and does not support ACID
provides eventual consistency
ideal for time-series or natural semantic ordering data
can run asynchronous batch or real-time processing on the data
can run machine learning algorithms on the data
provides petabytes of capacity with a maximum unit size of 10 MB per cell and 100 MB per row.
Usage Patterns
Low-latency read/write access
High-throughput data processing
Time series support
Anti Patterns
Not an ideal storage option for future analysis – Use BigQuery instead
Not an ideal storage option for transactional data – Use relational database or Datastore
Common Use cases
IoT, finance, adtech
Personalization, recommendations
Monitoring
Geospatial datasets
Graphs
Consider using Cloud Bigtable, if you need high-performance datastore to perform analytics on a large number of structured objects
Cloud Storage provides durable and highly available object storage.
fully managed, simple administration, cost-effective, and scalable service that does not require capacity management
supports unstructured data storage like binary or raw objects
provides high performance, internet-scale
supports data encryption at rest and in transit
Consider using Cloud Storage, if you need to store immutable blobs larger than 10 MB, such as large images or movies. This storage service provides petabytes of capacity with a maximum unit size of 5 TB per object.
offers MySQL, PostgreSQL, MSSQL databases as a service
manages OS & Software installation, patches and updates, backups and configuring replications, failover however needs to select and provision machines (vs Cloud Spanner)
single region only – although it now supports cross-region read replicas (vs Cloud Spanner)
Scaling
provides vertical scalability (Max. storage of 10TB)
storage can be increased without incurring any downtime
provides an option to increase the storage automatically
storage CANNOT be decreased
supports Horizontal scaling for read-only using read replicas (vs Cloud Spanner)
performance is linked to the disk size
Security
data is encrypted when stored in database tables, temporary files, and backups.
external connections can be encrypted by using SSL, or by using the Cloud SQL Proxy.
High Availability
fault-tolerance across zones can be achieved by configuring the instance for high availability by adding a failover replica
failover is automatic
can be created from primary instance only
replication from the primary instance to failover replica is semi-synchronous.
failover replica must be in the same region as the primary instance, but in a different zone
only one instance for every primary instance allowed
supports managed backups and backups are created on primary instance only
supports automatic replication
Backups
Automated backups can be configured and are stored for 7 days
Manual backups (snapshots) can be created and are not deleted automatically
Point-in-time recovery
requires binary logging enabled.
every update to the database is written to an independent log, which involves a small reduction in write performance.
performance of the read operations is unaffected by binary logging, regardless of the size of the binary log files.
Usage Patterns
direct lift and shift for MySQL, PostgreSQL, MSSQL database only
relational database service with strong consistency
OLTP workloads
Anti Patterns
need data storage more than 10TB, use Cloud Spanner
need global availability with low latency, use Cloud Spanner
not a direct replacement for Oracle use installation on GCE
Common Use cases
Websites, blogs, and content management systems (CMS)
Business intelligence (BI) applications
ERP, CRM, and eCommerce applications
Geospatial applications
Consider using Cloud SQL for full relational SQL support for OTLP and lift and shift of MySQL, PostgreSQL databases
provides fully managed, no-ops, OLAP, enterprise data warehouse (EDW) with SQL and fast ad-hoc queries.
provides high capacity, data warehousing analytics solution
ideal for big data exploration and processing
not ideal for operational or transactional databases
provides SQL interface
A scalable, fully managed
Usage Patterns
OLAP workloads up to petabyte-scale
Big data exploration and processing
Reporting via business intelligence (BI) tools
Anti Patterns
Not an ideal storage option for transactional data or OLTP – Use Cloud SQL or Cloud Spanner instead
Low-latency read/write access – Use Bigtable instead
Common Use cases
Analytical reporting on large data
Data science and advanced analyses
Big data processing using SQL
Memorystore
provides scalable, secure, and highly available in-memory service for Redis and Memcached.
fully managed as provisioning, replication, failover, and patching are all automated, which drastically reduces the time spent doing DevOps.
provides 100% compatibility with open source Redis and Memcached
is protected from the internet using VPC networks and private IP and comes with IAM integration
Usage Patterns
Lift and shift migration of applications
Low latency data caching and retrieval
Anti Patterns
Relational or NoSQL database
Analytics solution
Common Use cases
User session management
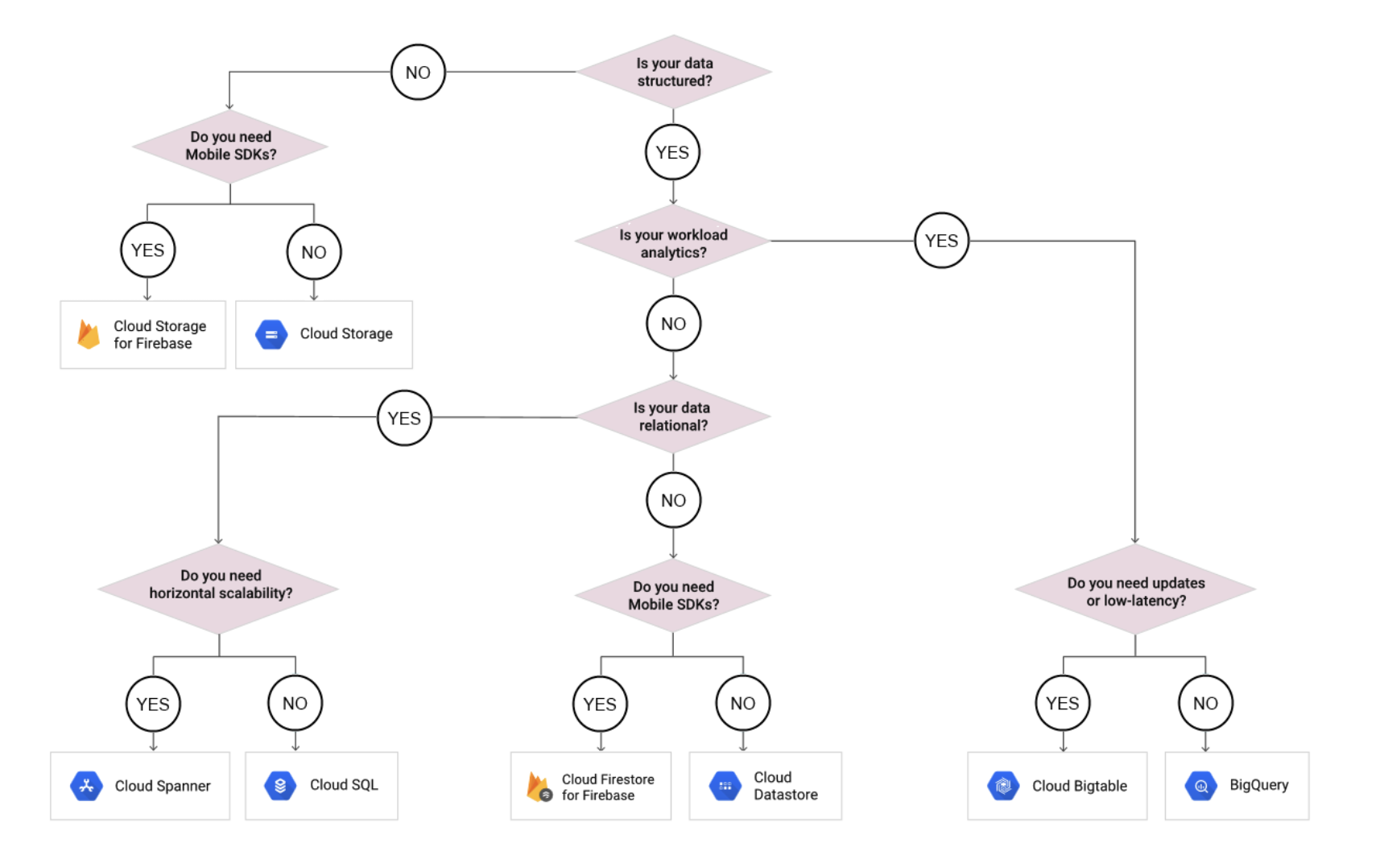
GCP Storage Options Decision Tree
GCP Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your application is hosted across multiple regions and consists of both relational database data and static images. Your database has over 10 TB of data. You want to use a single storage repository for each data type across all regions. Which two products would you choose for this task? (Choose two)
Cloud Bigtable
Cloud Spanner
Cloud SQL
Cloud Storage
You are building an application that stores relational data from users. Users across the globe will use this application. Your CTO is concerned about the scaling requirements because the size of the user base is unknown. You need to implement a database solution that can scale with your user growth with minimum configuration changes. Which storage solution should you use?
Cloud SQL
Cloud Spanner
Cloud Firestore
Cloud Datastore
Your company processes high volumes of IoT data that are time-stamped. The total data volume can be several petabytes. The data needs to be written and changed at a high speed. You want to use the most performant storage option for your data. Which product should you use?
Cloud Datastore
Cloud Storage
Cloud Bigtable
BigQuery
Your App Engine application needs to store stateful data in a proper storage service. Your data is non-relational database data. You do not expect the database size to grow beyond 10 GB and you need to have the ability to scale down to zero to avoid unnecessary costs. Which storage service should you use?
Cloud Bigtable
Cloud Dataproc
Cloud SQL
Cloud Datastore
A financial organization wishes to develop a global application to store transactions happening from different part of the world. The storage system must provide low latency transaction support and horizontal scaling. Which GCP service is appropriate for this use case?
Bigtable
Datastore
Cloud Storage
Cloud Spanner
You work for a mid-sized enterprise that needs to move its operational system transaction data from an on-premises database to GCP. The database is about 20 TB in size. Which database should you choose?