AWS ElastiCache Redis (Valkey) vs Memcached – When to Use Which
📅 Published June 2026: Covers Valkey 9.0 (full-text search, durability), Valkey 8.2 (vector search), ElastiCache Serverless pricing, Redis OSS Extended Support, and updated exam guidance for SAA-C03 and DVA-C02.
Overview
Amazon ElastiCache is a fully managed, in-memory caching service that supports three engines: Valkey, Redis OSS, and Memcached. While all three serve as high-performance key-value stores, they differ significantly in features, architecture, and use cases. This guide provides a comprehensive comparison to help you choose the right engine for your workload.
Engine Overview
Valkey (Recommended for New Workloads)
- Valkey is an open-source, high-performance key-value datastore stewarded by the Linux Foundation.
- Created in March 2024 as a community-driven fork of Redis OSS 7.2 after Redis Inc. changed its licensing to a non-open-source model.
- Backed by 40+ companies including AWS, Google, Microsoft, Oracle, and Ericsson.
- Drop-in replacement for Redis OSS — fully compatible with existing Redis clients and commands.
- AWS actively recommends Valkey for all new workloads due to:
- 33% lower Serverless pricing and 20% lower node-based pricing compared to Redis OSS/Memcached.
- Active open-source development with rapid innovation (Bloom filters, vector search, full-text search, durability).
- BSD license — no copyleft restrictions.
- Supports all Redis OSS features plus: vector search (8.2+), Bloom filters (8.1+), full-text search (9.0+), durability via Multi-AZ transactional log (9.0+), and hash field expiration (9.0+).
Redis OSS (Maintenance Track)
- Redis OSS 7.2 is the last fully open-source version of Redis supported on ElastiCache.
- As of March 2025, Redis 8.0 is licensed under AGPLv3 — a copyleft license that many organizations cannot use.
- ElastiCache versions 4 and 5 for Redis OSS reached end of standard support on January 31, 2026. Extended Support available (at 80-160% premium) through January 31, 2029.
- Redis OSS 6 reaches End of Life on January 31, 2027.
- AWS recommends migrating existing Redis OSS workloads to Valkey — zero-downtime, in-place upgrades are supported.
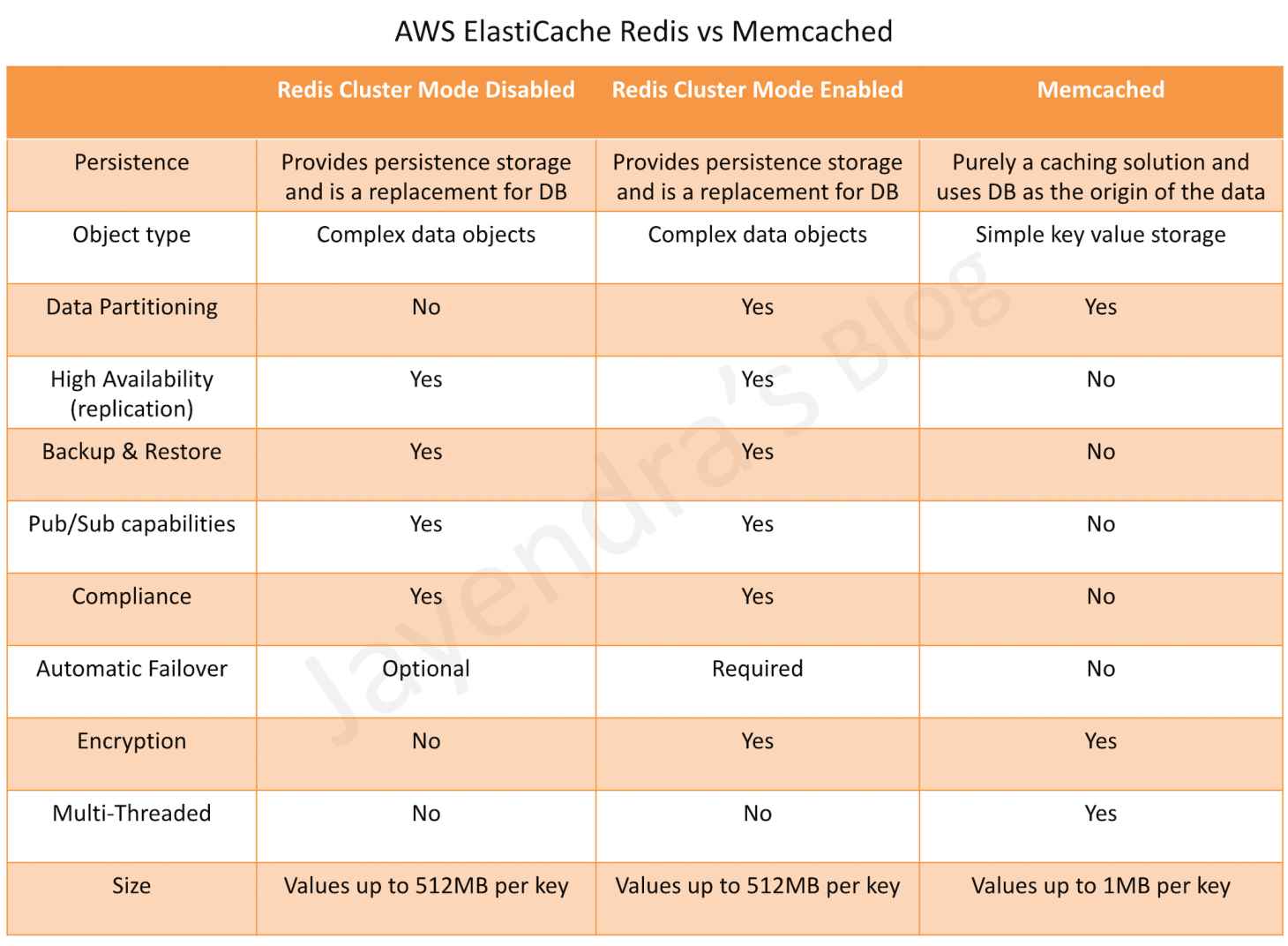
- Supports complex data types (strings, hashes, lists, sets, sorted sets, bitmaps, HyperLogLog, geospatial, streams), persistence, replication, Pub/Sub, Lua scripting, and cluster mode.
Memcached
- Memcached is a fully open-source (BSD licensed), high-performance, distributed memory object caching system.
- Designed for simplicity — pure key-value caching with a multi-threaded architecture.
- Ideal for simple caching use cases where advanced data structures, persistence, and replication are not needed.
- Supports only simple data types (strings and objects up to 1 MB).
- Multi-threaded — can utilize multiple CPU cores on a single node, unlike Valkey/Redis which are single-threaded (with I/O multithreading in Valkey).
- No replication, no automatic failover, no persistence (node-based), no Pub/Sub.
- Supports horizontal scaling by adding/removing nodes from the cluster.
Detailed Comparison Table
| Feature |
Valkey / Redis OSS |
Memcached |
| Data Types |
Complex — strings, hashes, lists, sets, sorted sets, bitmaps, HyperLogLog, geospatial, streams, Bloom filters (Valkey 8.1+) |
Simple — strings and objects only |
| Persistence |
Yes — RDB snapshots + AOF. Valkey 9.0 adds durability via Multi-AZ transactional log |
No — data lost on node restart (node-based) |
| Replication |
Yes — up to 5 read replicas per shard |
No |
| Multi-AZ with Automatic Failover |
Yes — automatic failover to read replica |
No — requires application-level redundancy |
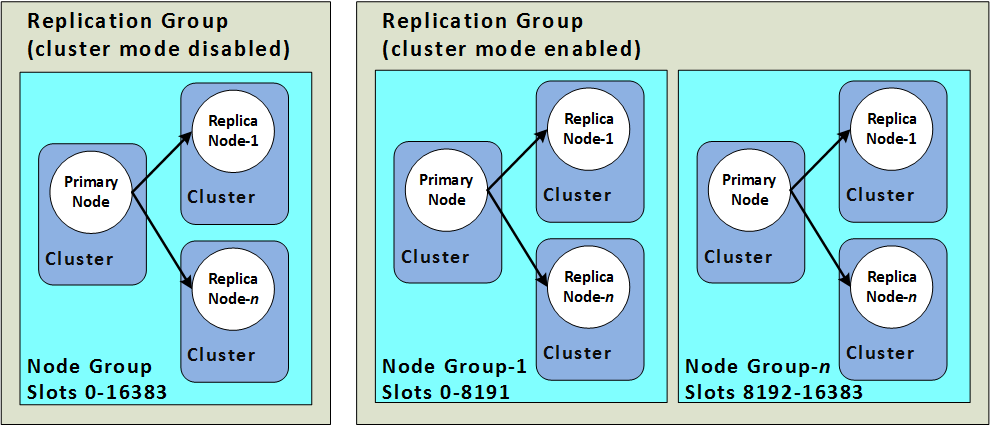
| Clustering / Data Partitioning |
Yes — cluster mode with up to 500 shards |
Yes — client-side sharding across nodes |
| Pub/Sub |
Yes — including Sharded Pub/Sub (7.2+) |
No |
| Lua Scripting |
Yes — Lua scripts and Functions (7.2+) |
No |
| Backup & Restore |
Yes — automated daily snapshots + manual snapshots |
Serverless only (not available for node-based clusters) |
| Encryption at Rest |
Yes (4.0.10+) |
No |
| Encryption in Transit (TLS) |
Yes (4.0.10+) |
Yes (1.6.12+) |
| Compliance (HIPAA, FedRAMP, PCI DSS) |
Yes |
Yes (1.6.12+ for HIPAA/FedRAMP) |
| Multi-threaded |
No (single-threaded with I/O multithreading in Valkey) |
Yes — utilizes multiple CPU cores |
| Geospatial Indexing |
Yes (4.0.10+, polygon queries in Valkey 9.0) |
No |
| Vector Search |
Yes (Valkey 8.2+) — microsecond latency, 95%+ recall |
No |
| Full-Text Search |
Yes (Valkey 9.0+) — hybrid text + vector search |
No |
| Sorted Sets / Leaderboards |
Yes |
No |
| Data Tiering (SSD) |
Yes (6.2+ with r6gd nodes) — 5x more storage, 60%+ cost savings |
No |
| Global Datastore (Cross-Region) |
Yes — fully managed cross-region replication |
No |
| Authentication |
AUTH token + RBAC (Role-Based Access Control, 6.0+) |
SASL authentication |
| Max Item Size |
512 MB per key |
1 MB per item (default) |
ElastiCache Serverless
ElastiCache Serverless (GA November 2023) eliminates infrastructure management for all three engines. It automatically scales compute, memory, and network to match demand with no nodes to provision or manage.
| Feature |
Serverless for Valkey |
Serverless for Redis OSS |
Serverless for Memcached |
| Availability SLA |
99.99% |
99.99% |
99.99% |
| Multi-AZ |
Yes (default) |
Yes (default) |
Yes (default) |
| Backup & Restore |
Yes |
Yes |
Yes |
| Minimum Data Storage |
100 MB (90% lower) |
1 GB |
1 GB |
| Max Throughput |
5 million RPS (Valkey 8.0+) |
5 million RPS |
5 million RPS |
| Zero Downtime Maintenance |
Yes |
Yes |
Yes |
| IPv6 / Dual-Stack |
Yes |
Yes |
Yes |
| Create Time |
< 1 minute |
< 1 minute |
< 1 minute |
Key Serverless Benefit: Memcached Serverless now includes backup & restore, which is NOT available for node-based Memcached clusters. This resolves one of Memcached’s traditional limitations.
Pricing Comparison (US East – N. Virginia)
ElastiCache Serverless Pricing
| Dimension |
Valkey |
Redis OSS |
Memcached |
| ECPU (per million) |
$0.0023 |
$0.0034 |
$0.0034 |
| Data Storage (per GB-hour) |
$0.084 |
$0.125 |
$0.125 |
| Min Data Metered |
100 MB |
1 GB |
1 GB |
| Savings vs Redis/Memcached |
33% lower |
Baseline |
Baseline |
Node-Based Pricing (On-Demand, cache.r7g.large)
| Dimension |
Valkey |
Redis OSS |
Memcached |
| On-Demand (per hour) |
$0.1402 |
$0.1752 |
$0.218 |
| Savings vs Redis OSS |
20% lower |
Baseline |
— |
| Reserved (1-yr, All Upfront) |
Up to 55% off On-Demand |
Up to 55% off On-Demand |
Up to 55% off On-Demand |
| Extended Support Premium |
N/A |
80% (Yr 1-2), 160% (Yr 3) |
N/A |
Cost Optimization Tips:
- Migrate Redis OSS → Valkey for immediate 20-33% savings with zero-downtime, in-place upgrades.
- Existing Redis OSS Reserved Instances automatically apply to Valkey nodes in the same instance family — you get 20% more value.
- Use Database Savings Plans (1-year commitment) for additional savings on Serverless.
- Use Data Tiering (r6gd nodes) for workloads accessing <20% of data frequently — 60%+ cost savings.
- Backup storage: $0.085 per GiB/month for all engines.
Decision Guide – When to Use Which
Choose Valkey (Recommended Default) When:
- Starting any new caching workload — Valkey is the default recommendation.
- You need complex data structures (sorted sets, lists, hashes, streams).
- You need persistence, backup/restore, or durability for data protection.
- You need high availability with Multi-AZ automatic failover.
- You need Pub/Sub for real-time messaging.
- You need Lua scripting or server-side Functions for atomic operations.
- You need leaderboards, ranking, or rate limiting.
- You need session management with automatic expiration.
- You need geospatial queries (nearby search, distance calculations).
- You need vector similarity search for AI/ML recommendations (Valkey 8.2+).
- You need full-text search within your cache layer (Valkey 9.0+).
- You need cross-region replication (Global Datastore).
- You want the lowest cost option (33% cheaper Serverless, 20% cheaper node-based).
Choose Memcached When:
- You need the simplest possible caching model — just key-value GET/SET.
- You need multi-threaded performance on large nodes with multiple cores.
- You need horizontal scaling with simple add/remove node operations.
- You are caching database query results or rendered HTML fragments.
- You don’t need persistence — data can be easily regenerated from the source.
- You don’t need replication or automatic failover (or use Serverless for HA).
- Your objects are simple strings/blobs and you don’t need complex data operations.
- You have an existing Memcached application and don’t want to change client code.
Common Use Case Mapping
| Use Case |
Recommended Engine |
Why |
| Session store |
Valkey |
Persistence + TTL + replication prevent session loss |
| Gaming leaderboard |
Valkey |
Sorted sets with O(log N) ranking operations |
| Real-time chat / messaging |
Valkey |
Pub/Sub + Lists for message queues |
| AI recommendation engine |
Valkey 8.2+ |
Native vector search with microsecond latency |
| Database query caching |
Valkey or Memcached |
Both work; Valkey preferred for persistence |
| Simple object caching (HTML, API responses) |
Memcached |
Simple key-value with multi-threaded throughput |
| Rate limiting |
Valkey |
Atomic INCR with TTL expiration |
| Geospatial (nearby stores, riders) |
Valkey |
GEOADD, GEORADIUS, polygon queries (9.0) |
| Durable cache / primary datastore |
Valkey 9.0 |
Multi-AZ transactional log for zero data loss |
| Large-scale ephemeral caching |
Memcached |
Multi-threaded, simple horizontal scaling |
DAX vs ElastiCache – When to Use Which
DynamoDB Accelerator (DAX) and ElastiCache are both in-memory caching solutions, but they serve different purposes:
| Criteria |
DAX |
ElastiCache |
| Purpose |
Accelerate DynamoDB reads |
General-purpose in-memory cache for any data source |
| Data Source |
DynamoDB only |
Any (RDS, APIs, DynamoDB, files, etc.) |
| Code Changes |
Minimal — drop-in DynamoDB client replacement |
Requires cache-aside logic in application |
| Latency |
Microseconds (single-digit) |
Microseconds to sub-millisecond |
| Write Caching |
Write-through (automatic) |
Application-managed invalidation |
| Best For |
Read-heavy DynamoDB workloads with hot keys |
Aggregated results, computed data, session stores, leaderboards |
Exam Tip: If the question mentions DynamoDB with read-heavy workloads and hot partitions, choose DAX. If the question involves caching from multiple sources, complex data structures, or Pub/Sub, choose ElastiCache.
AWS Certification Exam Relevance
- SAA-C03 (Solutions Architect Associate): Frequently tests ElastiCache engine selection (Redis/Valkey vs Memcached), caching strategies (lazy loading, write-through), Multi-AZ failover, and DAX vs ElastiCache decision making.
- DVA-C02 (Developer Associate): Tests session management with ElastiCache, caching patterns, TTL strategies, and integration with Lambda/API Gateway.
- SAP-C02 (Solutions Architect Professional): Tests Global Datastore for cross-region caching, data tiering, and advanced caching architectures.
- Key Exam Themes:
- Memcached = simple, multi-threaded, no persistence, no replication.
- Redis/Valkey = complex data types, persistence, replication, Multi-AZ, Pub/Sub, backup/restore.
- DAX = DynamoDB-specific, microsecond reads, drop-in replacement, no code changes.
- ElastiCache Serverless = no capacity planning, auto-scaling, pay-per-use.
- Valkey = recommended for new workloads, lower cost, open-source.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A company is building a gaming application that needs a real-time leaderboard with millions of players. The leaderboard must support efficient ranking, score updates, and range queries. Which ElastiCache solution should a solutions architect recommend?
- ElastiCache for Memcached with client-side sorting
- ElastiCache for Valkey using Sorted Sets
- ElastiCache for Memcached with application-layer ranking
- ElastiCache for Redis OSS with simple key-value pairs
Show Answer
Answer: b. – Valkey/Redis Sorted Sets provide O(log N) ranking operations with ZADD, ZRANK, and ZRANGE commands, making them ideal for leaderboards. Memcached does not support sorted sets.
- A startup wants to deploy an in-memory cache with the lowest possible cost and no infrastructure management. They have unpredictable traffic patterns and their average dataset is 500 MB. Which option provides the MOST cost-effective solution?
- ElastiCache Serverless for Redis OSS
- ElastiCache node-based cluster for Valkey with reserved instances
- ElastiCache Serverless for Valkey
- ElastiCache Serverless for Memcached
Show Answer
Answer: c. – ElastiCache Serverless for Valkey offers 33% lower pricing than Redis OSS and Memcached Serverless, with a minimum metered storage of only 100 MB (vs 1 GB for others). For unpredictable traffic, Serverless auto-scales without overprovisioning.
- A company has a DynamoDB table experiencing hot partition reads. Read latency must be reduced to microseconds. Which caching solution requires the LEAST application code changes?
- ElastiCache for Valkey with cache-aside pattern
- ElastiCache for Memcached with lazy loading
- DynamoDB Accelerator (DAX)
- ElastiCache for Valkey with write-through caching
Show Answer
Answer: c. – DAX is a drop-in replacement for the DynamoDB client — it requires minimal code changes (just change the endpoint). ElastiCache requires implementing cache-aside or write-through logic in the application.
- A solutions architect needs to choose a caching engine for a web application. The requirements are: multi-threaded performance, simple key-value caching of database query results, no need for persistence, and the ability to horizontally scale by adding nodes. Which engine is MOST appropriate?
- ElastiCache for Valkey in cluster mode
- ElastiCache for Memcached
- ElastiCache for Redis OSS with read replicas
- DynamoDB Accelerator (DAX)
Show Answer
Answer: b. – Memcached matches all stated requirements: multi-threaded, simple key-value, no persistence needed, and horizontal scaling by adding/removing nodes. While Valkey could work, it adds complexity that isn’t needed here.
- A company is migrating from ElastiCache for Redis OSS version 5. They received an Extended Support notification with 80% premium charges. What is the MOST cost-effective long-term migration path?
- Pay for Extended Support to avoid migration effort
- Upgrade to Redis OSS 7.2
- Migrate to ElastiCache for Valkey using in-place upgrade
- Move to Amazon MemoryDB for Redis
Show Answer
Answer: c. – Migrating to Valkey provides 20% lower node-based pricing (or 33% lower Serverless), active development, and avoids Extended Support premiums (80-160%). In-place upgrades from Redis OSS to Valkey are zero-downtime.
- A development team needs an in-memory caching solution that supports: persistence for disaster recovery, Multi-AZ failover for high availability, encryption at rest and in transit for compliance, and Pub/Sub for real-time notifications. Which combination of ElastiCache features meets ALL requirements? (Select TWO)
- ElastiCache for Memcached with SASL authentication
- ElastiCache for Valkey with Multi-AZ enabled
- ElastiCache for Valkey with encryption at rest and in-transit enabled
- ElastiCache for Memcached with TLS encryption
- ElastiCache for Memcached with backup enabled
Show Answer
Answer: b, c – Only Valkey/Redis OSS supports persistence, Multi-AZ automatic failover, encryption at rest, AND Pub/Sub together. Memcached lacks persistence (node-based), replication, failover, encryption at rest, and Pub/Sub.
- An e-commerce application requires a cache that can serve as a durable primary datastore with microsecond read latency and zero data loss during failures. Which ElastiCache option should a solutions architect recommend?
- ElastiCache for Redis OSS 7.2 with AOF persistence
- ElastiCache for Valkey 8.0 with daily backups
- ElastiCache for Valkey 9.0 with synchronous durability
- ElastiCache for Memcached Serverless
Show Answer
Answer: c. – Valkey 9.0 introduces durability via a Multi-AZ transactional log with synchronous writes designed for zero data loss. Traditional RDB/AOF persistence can lose recent writes during failures.
Related Posts
References