S3 Best Practices
Performance
Multiple Concurrent PUTs/GETs
- S3 scales to support very high request rates. S3 automatically partitions the buckets as needed to support higher request rates.
- S3 can achieve at least 3,500 PUT/COPY/POST/DELETE and 5,500 GET/HEAD requests per second per partitioned prefix in a bucket.
- There are no limits to the number of prefixes in a bucket, so throughput can be scaled horizontally by parallelizing reads or writes across different prefixes.
- Random prefix key naming is NO LONGER required for performance optimization.
- Since July 2018, S3 automatically handles internal partitioning to support high request rates.
- Logical or sequential naming patterns can be used without any performance implications.
- S3 dynamically optimizes performance in response to sustained high request rates.
- If a workload experiences sudden bursts above the per-prefix limit, S3 will return HTTP 503 (Slow Down) responses temporarily while it repartitions. Gradually ramping up request rates (prefix-level warm-up) helps avoid throttling for new prefixes.
S3 Express One Zone (High-Performance Storage)
- S3 Express One Zone is a high-performance storage class (launched Nov 2023) purpose-built for latency-sensitive applications.
- Delivers consistent single-digit millisecond first-byte read and write latency — up to 10x faster than S3 Standard.
- Reduces request costs by up to 50% compared to S3 Standard.
- Scales to process millions of requests per minute.
- Uses directory buckets stored in a single Availability Zone.
- Ideal for ML model training, interactive analytics, media content creation, and high-frequency trading.
- AWS announced up to 85% price reductions for S3 Express One Zone in April 2025.
Transfer Acceleration
- S3 Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between the client and an S3 bucket.
- Transfer Acceleration takes advantage of CloudFront’s globally distributed edge locations. As the data arrives at an edge location, data is routed to S3 over an optimized network path.
- Use the S3 Transfer Acceleration Speed Comparison tool to determine if it would benefit your use case.
GET-intensive Workloads
- CloudFront can be used for performance optimization and can help by
- distributing content with low latency and high data transfer rate.
- caching the content and thereby reducing the number of direct requests to S3
- providing multiple endpoints (Edge locations) for data availability
CloudFront RTMP distributions were deprecated on December 31, 2020. Use CloudFront Web distributions with HTTP-based streaming (HLS, DASH) for media delivery.- To fast data transport over long distances between a client and an S3 bucket, use S3 Transfer Acceleration. Transfer Acceleration uses the globally distributed edge locations in CloudFront to accelerate data transport over geographical distances.
PUTs/GETs for Large Objects
- AWS allows Parallelizing the PUTs/GETs request to improve the upload and download performance as well as the ability to recover in case it fails
- For PUTs, Multipart upload can help improve the uploads by
- performing multiple uploads at the same time and maximizing network bandwidth utilization
- quick recovery from failures, as only the part that failed to upload needs to be re-uploaded
- ability to pause and resume uploads
- begin an upload before the Object size is known
- Recommended for objects larger than 100 MB; required for objects larger than 5 GB
- For GETs, the Range HTTP header (byte-range fetches) can help improve the downloads by
- allowing the object to be retrieved in parts instead of the whole object
- quick recovery from failures, as only the part that failed to download needs to be retried
- higher aggregate throughput by downloading parts in parallel
List Operations
- Object key names are stored lexicographically in S3 indexes, making it hard to sort and manipulate the contents of LIST
- S3 maintains a single lexicographically sorted list of indexes
- Build and maintain Secondary Index outside of S3 for e.g. DynamoDB or RDS to store, index and query objects metadata rather than performing operations on S3
- Use S3 Inventory reports (daily or weekly) as an alternative to LIST API calls for large buckets — more efficient and cost-effective for auditing or analytics workloads.
Security
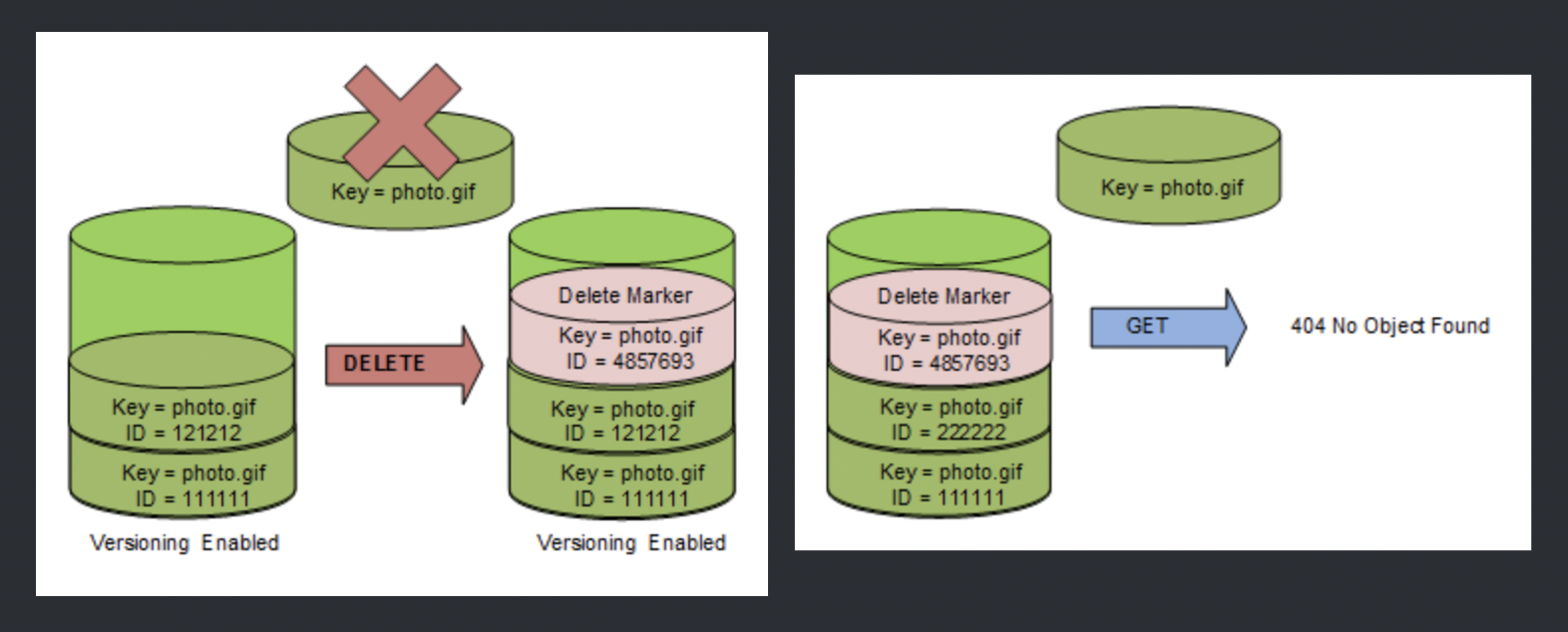
- Use Versioning
- can be used to protect from unintended overwrites and deletions
- allows the ability to retrieve and restore deleted objects or rollback to previous versions
- Enable additional security by configuring a bucket to enable MFA (Multi-Factor Authentication) Delete
- Versioning does not prevent Bucket deletion and must be backed up as if accidentally or maliciously deleted the data is lost
- Use S3 Object Lock for WORM (Write Once Read Many) protection
- Prevents objects from being deleted or overwritten for a fixed period or indefinitely
- Supports Governance mode (can be overridden with special permissions) and Compliance mode (cannot be overridden by anyone, including root)
- Requires versioning to be enabled
- Helps meet regulatory requirements (SEC, FINRA, CFTC)
- Use Same Region Replication or Cross Region Replication feature to backup data to a different bucket or region
- When using VPC with S3, use VPC S3 endpoints as
- are horizontally scaled, redundant, and highly available VPC components
- help establish a private connection between VPC and S3 and the traffic never leaves the Amazon network
- Support both Gateway endpoints (free, for S3 and DynamoDB) and Interface endpoints (PrivateLink, for cross-region or on-premises access)
S3 Security Defaults (Since 2023)
- Default Encryption: Since January 5, 2023, all new objects are automatically encrypted with SSE-S3 (AES-256) at no additional cost. You can override with SSE-KMS or SSE-C.
- Block Public Access: Since April 2023, S3 Block Public Access is enabled by default and ACLs are disabled for all new buckets.
- SSE-C Disabled by Default: New general purpose buckets automatically disable server-side encryption with customer-provided keys (SSE-C) as a security best practice.
- Use S3 Access Grants for scalable, fine-grained access control — maps S3 permissions to corporate identities via IAM Identity Center.
Refer blog post @ S3 Security Best Practices
Cost
- Optimize S3 storage cost by selecting an appropriate storage class for objects:
- S3 Standard — frequently accessed data
- S3 Intelligent-Tiering — data with unknown or changing access patterns (automatically moves objects between Frequent, Infrequent, Archive Instant, Archive, and Deep Archive access tiers)
- S3 Standard-IA — infrequent access, rapid retrieval needed
- S3 One Zone-IA — infrequent access, non-critical data
- S3 Glacier Instant Retrieval — archive data needing millisecond access
- S3 Glacier Flexible Retrieval — archive with minutes to hours retrieval
- S3 Glacier Deep Archive — lowest cost, 12-48 hour retrieval
- S3 Express One Zone — highest performance, single-digit ms latency
- Configure appropriate Lifecycle Management rules to automatically transition objects to lower-cost storage classes and expire them when no longer needed.
- Use S3 Intelligent-Tiering as the default storage class for data with unpredictable access patterns — no retrieval charges, automatic optimization.
- Use S3 Storage Lens to get organization-wide visibility into storage usage and activity trends, identify cost optimization opportunities, and apply data protection best practices.
- Use S3 Storage Class Analysis to identify the optimal lifecycle policy for transitioning data to the right storage class.
Data Integrity
- Use Conditional Writes (launched August 2024) to prevent overwriting existing objects
- Supports
If-None-Match header to check for object existence before creating
- Supports
If-Match header to check ETag before updating
- Eliminates the need for external locking mechanisms (e.g., DynamoDB) for multi-writer applications
- Can be enforced at the bucket level using bucket policies (November 2024)
- Use S3 Object Lock for immutable data protection (compliance, ransomware protection)
- Enable S3 Versioning to preserve every version of every object
- Use additional checksums (CRC32, CRC32C, SHA-1, SHA-256) for end-to-end data integrity validation during uploads
Tracking and Monitoring
- Use S3 Event Notifications with Amazon EventBridge for advanced event-driven architectures
- Supports filtering by object size, key name patterns, metadata, and event time
- Can route events to over 20+ AWS service targets
- More flexible than legacy S3 Event Notifications (which only support SNS, SQS, and Lambda)
- Use CloudTrail for API-level logging — captures all S3 API calls for auditing and compliance
- Use S3 Server Access Logging for detailed access records (object-level access patterns)
- Use CloudWatch to monitor S3 buckets, tracking metrics such as object counts, bytes stored, request counts, and latency
- Use S3 Storage Lens for organization-wide visibility across all accounts and buckets with actionable recommendations
S3 Monitoring and Auditing Best Practices
Refer blog post @ S3 Monitoring and Auditing Best Practices
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A media company produces new video files on-premises every day with a total size of around 100GB after compression. All files have a size of 1-2 GB and need to be uploaded to Amazon S3 every night in a fixed time window between 3am and 5am. Current upload takes almost 3 hours, although less than half of the available bandwidth is used. What step(s) would ensure that the file uploads are able to complete in the allotted time window?
- Increase your network bandwidth to provide faster throughput to S3
- Upload the files in parallel to S3 using multipart upload
- Pack all files into a single archive, upload it to S3, then extract the files in AWS
- Use AWS Import/Export to transfer the video files
- You are designing a web application that stores static assets in an Amazon Simple Storage Service (S3) bucket. You expect this bucket to immediately receive over 150 PUT requests per second. What should you do to ensure optimal performance?
- Use multi-part upload.
- Add a random prefix to the key names.
- Amazon S3 will automatically manage performance at this scale. (Since July 2018, S3 automatically partitions for high request rates. 150 PUT/s is well within the 3,500 PUT/s per prefix limit. Random prefixes are no longer needed.)
- Use a predictable naming scheme, such as sequential numbers or date time sequences, in the key names
- You have an application running on an Amazon Elastic Compute Cloud instance, that uploads 5 GB video objects to Amazon Simple Storage Service (S3). Video uploads are taking longer than expected, resulting in poor application performance. Which method will help improve performance of your application?
- Enable enhanced networking
- Use Amazon S3 multipart upload
- Leveraging Amazon CloudFront, use the HTTP POST method to reduce latency.
- Use Amazon Elastic Block Store Provisioned IOPs and use an Amazon EBS-optimized instance
- Which of the following methods gives you protection against accidental loss of data stored in Amazon S3? (Choose 2)
- Set bucket policies to restrict deletes, and also enable versioning
- By default, versioning is enabled on a new bucket so you don’t have to worry about it (Not enabled by default)
- Build a secondary index of your keys to protect the data (improves performance only)
- Back up your bucket to a bucket owned by another AWS account for redundancy
- A startup company hired you to help them build a mobile application that will ultimately store billions of image and videos in Amazon S3. The company is lean on funding, and wants to minimize operational costs, however, they have an aggressive marketing plan, and expect to double their current installation base every six months. Due to the nature of their business, they are expecting sudden and large increases to traffic to and from S3, and need to ensure that it can handle the performance needs of their application. What other information must you gather from this customer in order to determine whether S3 is the right option?
- You must know how many customers that company has today, because this is critical in understanding what their customer base will be in two years. (No. of customers do not matter)
- You must find out total number of requests per second at peak usage.
- You must know the size of the individual objects being written to S3 in order to properly design the key namespace. (Size does not relate to the key namespace design but the count does)
- In order to build the key namespace correctly, you must understand the total amount of storage needs for each S3 bucket. (S3 provided unlimited storage the key namespace design would depend on the number)
- A document storage company is deploying their application to AWS and changing their business model to support both free tier and premium tier users. The premium tier users will be allowed to store up to 200GB of data and free tier customers will be allowed to store only 5GB. The customer expects that billions of files will be stored. All users need to be alerted when approaching 75 percent quota utilization and again at 90 percent quota use. To support the free tier and premium tier users, how should they architect their application?
- The company should utilize an amazon simple workflow service activity worker that updates the users data counter in amazon dynamo DB. The activity worker will use simple email service to send an email if the counter increases above the appropriate thresholds.
- The company should deploy an amazon relational data base service relational database with a store objects table that has a row for each stored object along with size of each object. The upload server will query the aggregate consumption of the user in questions (by first determining the files store by the user, and then querying the stored objects table for respective file sizes) and send an email via Amazon Simple Email Service if the thresholds are breached. (Good Approach to use RDS but with so many objects might not be a good option)
- The company should write both the content length and the username of the files owner as S3 metadata for the object. They should then create a file watcher to iterate over each object and aggregate the size for each user and send a notification via Amazon Simple Queue Service to an emailing service if the storage threshold is exceeded. (List operations on S3 not feasible)
- The company should create two separated amazon simple storage service buckets one for data storage for free tier users and another for data storage for premium tier users. An amazon simple workflow service activity worker will query all objects for a given user based on the bucket the data is stored in and aggregate storage. The activity worker will notify the user via Amazon Simple Notification Service when necessary (List operations on S3 not feasible as well as SNS does not address email requirement)
- Your company host a social media website for storing and sharing documents. the web application allow users to upload large files while resuming and pausing the upload as needed. Currently, files are uploaded to your php front end backed by Elastic Load Balancing and an autoscaling fleet of amazon elastic compute cloud (EC2) instances that scale upon average of bytes received (NetworkIn) After a file has been uploaded. it is copied to amazon simple storage service(S3). Amazon Ec2 instances use an AWS Identity and Access Management (AMI) role that allows Amazon s3 uploads. Over the last six months, your user base and scale have increased significantly, forcing you to increase the auto scaling groups Max parameter a few times. Your CFO is concerned about the rising costs and has asked you to adjust the architecture where needed to better optimize costs. Which architecture change could you introduce to reduce cost and still keep your web application secure and scalable?
- Replace the Autoscaling launch Configuration to include c3.8xlarge instances; those instances can potentially yield a network throughput of 10gbps. (no info of current size and might increase cost)
- Re-architect your ingest pattern, have the app authenticate against your identity provider as a broker fetching temporary AWS credentials from AWS Secure token service (GetFederation Token). Securely pass the credentials and s3 endpoint/prefix to your app. Implement client-side logic to directly upload the file to amazon s3 using the given credentials and S3 Prefix. (will not provide the ability to handle pause and restarts)
- Re-architect your ingest pattern, and move your web application instances into a VPC public subnet. Attach a public IP address for each EC2 instance (using the auto scaling launch configuration settings). Use Amazon Route 53 round robin records set and http health check to DNS load balance the app request this approach will significantly reduce the cost by bypassing elastic load balancing. (ELB is not the bottleneck)
- Re-architect your ingest pattern, have the app authenticate against your identity provider as a broker fetching temporary AWS credentials from AWS Secure token service (GetFederation Token). Securely pass the credentials and s3 endpoint/prefix to your app. Implement client-side logic that used the S3 multipart upload API to directly upload the file to Amazon s3 using the given credentials and s3 Prefix. (multipart allows one to start uploading directly to S3 before the actual size is known or complete data is downloaded)
- If an application is storing hourly log files from thousands of instances from a high traffic web site, which naming scheme would give optimal performance on S3?
- Sequential
- instanceID_log-HH-DD-MM-YYYY
- instanceID_log-YYYY-MM-DD-HH
- HH-DD-MM-YYYY-log_instanceID (HH will give some randomness to start with instead of instanceId where the first characters would be i-)
- YYYY-MM-DD-HH-log_instanceID
📝 Note: Since July 2018, S3 no longer requires random prefixes for performance. S3 automatically partitions based on request patterns. However, this exam question may still appear as it tests understanding of the historical key naming optimization concept.
- A company wants to ensure that objects uploaded to their S3 bucket are never accidentally overwritten by concurrent writes from multiple application instances. Which S3 feature should they use? [Added 2024]
- S3 Versioning
- S3 Object Lock in Governance mode
- S3 Conditional Writes with If-None-Match header (Conditional writes (Aug 2024) allow checking object existence before creating, preventing accidental overwrites without external locking)
- S3 Bucket Policy with deny overwrite
- A company stores millions of objects in S3 with unpredictable access patterns. Some objects are accessed frequently for a few weeks, then rarely accessed again. Which storage class provides the most cost-effective solution without operational overhead? [Added 2024]
- S3 Standard with lifecycle policy to S3 Standard-IA
- S3 Intelligent-Tiering (Automatically moves objects between frequent, infrequent, and archive access tiers based on access patterns with no retrieval charges and no operational overhead)
- S3 One Zone-IA
- S3 Standard with manual storage class changes
- An application requires single-digit millisecond latency for read and write operations on objects stored in S3. The application processes millions of transactions per minute. Which S3 storage option provides the best performance? [Added 2024]
- S3 Standard with CloudFront caching
- S3 Standard with Transfer Acceleration
- S3 Express One Zone (Delivers consistent single-digit millisecond latency, up to 10x faster than S3 Standard, and supports millions of requests per minute. Uses directory buckets in a single AZ.)
- S3 Standard with provisioned capacity
References