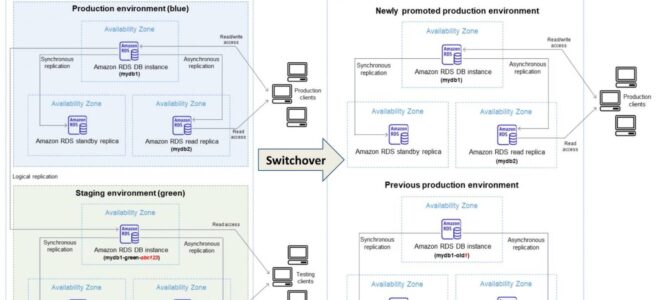
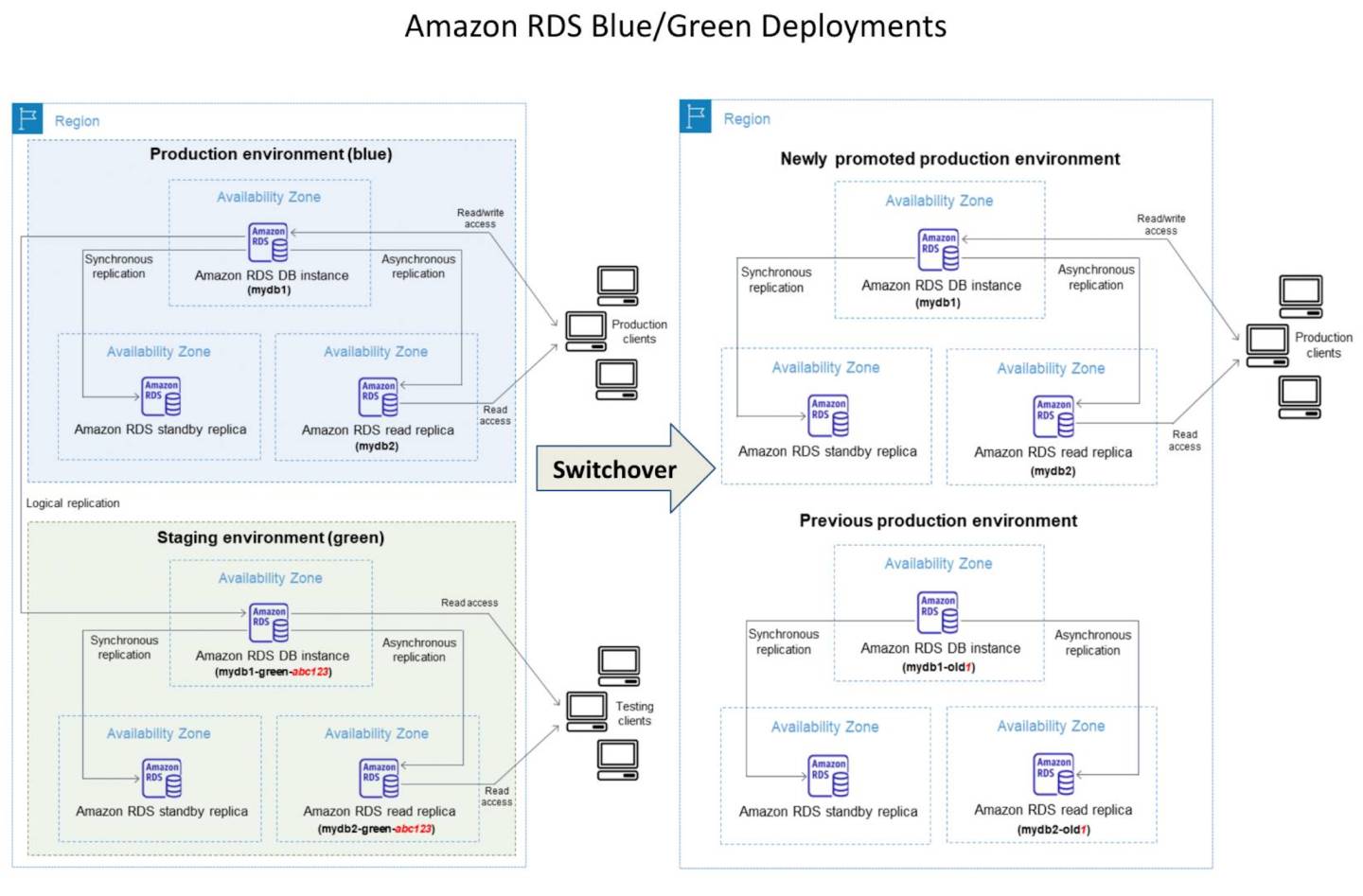
Amazon RDS Blue/Green Deployments help make and test database changes before implementing them in a production environment.
RDS Blue/Green Deployment has the blue environment as the current production environment and the green environment as the staging environment.
RDS Blue/Green Deployment creates a staging or green environment that exactly copies the production environment.
Green environment is a copy of the topology of the production environment and includes the features used by the DB instance including the Multi-AZ deployment, read replicas, the storage configuration, DB snapshots, automated backups, Performance Insights, and Enhanced Monitoring.
Green environment or the staging environment always stays in sync with the current production environment using logical replication.
RDS DB instances in the green environment can be changed without affecting production workloads. Changes can include the upgrade of major or minor DB engine versions, upgrade of underlying file system configuration, or change of database parameters in the staging environment.
Changes can be thoroughly tested in the green environment and when ready, the environments can be switched over to promote the green environment to be the new production environment.
Switchover typically takes under a minute with no data loss and no need for application changes.
Blue/Green Deployments are currently supported only for RDS for MariaDB, MySQL, and PostgreSQL.
RDS Blue/Green Deployments Benefits
Easily create a production-ready staging environment.
Automatically replicate database changes from the production environment to the staging environment.
Test database changes in a safe staging environment without affecting the production environment.
Stay current with database patches and system updates.
Implement and test newer database features.
Switch over your staging environment to be the new production environment without changes to your application.
Safely switch over through the use of built-in switchover guardrails.
Eliminate data loss during switchover.
Switch over quickly, typically under a minute depending on your workload.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
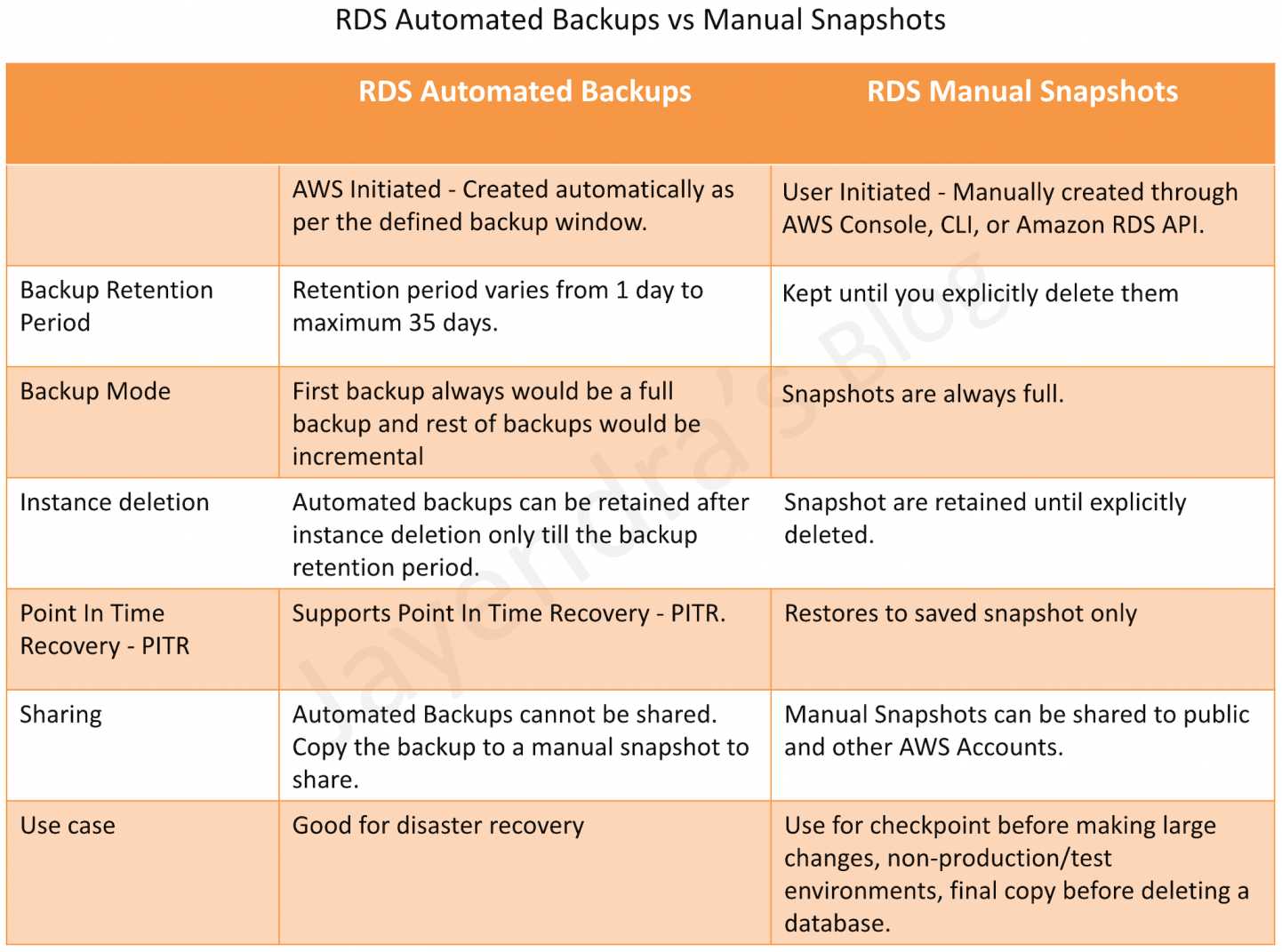
Amazon RDS Automated Backups are AWS Initiated. Backups are created automatically as per the defined backup window. Backups are also created when a read replica is created.
Amazon RDS DB snapshots are manual, user-initiated backups that enable a DB instance backup to be restored to that specific state at any time.
Instance Deletion & Backup Retention Period
Amazon RDS Backups can be configured with a retention period varying from 1 day to a maximum of 35 days.
RDS Automated Backups are deleted when the DB instance is deleted. However, RDS can now be configured to retain the automated backups on RDS instance deletion. These backups would be retained only till their retention window.
RDS Snapshots don’t expire and RDS keeps all manual DB snapshots until explicitly deleted and aren’t subject to the backup retention period.
Backup Mode
RDS Backups are incremental. The first snapshot of a DB instance contains the data for the full database. Subsequent backups of the same database are incremental, meaning only the data that has changed after your most recent backup is saved.
RDS Snapshots are always full.
Point In Time Recovery – PITR
RDS Automated Backups with transaction logs help support Point In Time Recovery – PITR. You can restore your DB by rewinding it to a specific time you choose.
RDS Snapshots restores to saved snapshot data only. It cannot be used for PITR.
Sharing
RDS Automated Backups cannot be shared. You can copy the automated backup to a manual snapshot to share.
RDS Manual Snapshots can be shared with the public and with other AWS Accounts.
Use case
RDS Backups are Good for disaster recovery
RDS Snapshots can be used for checkpoint before making large changes, non-production/test environments, and final copy before deleting a database.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You receive a frantic call from a new DBA who accidentally dropped a table containing all your customers. Which Amazon RDS feature will allow you to reliably restore your database within 5 minutes of when the mistake was made?
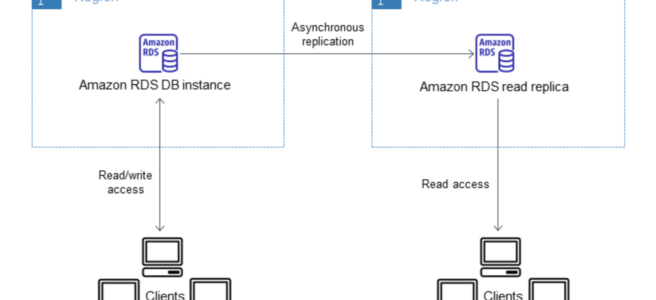
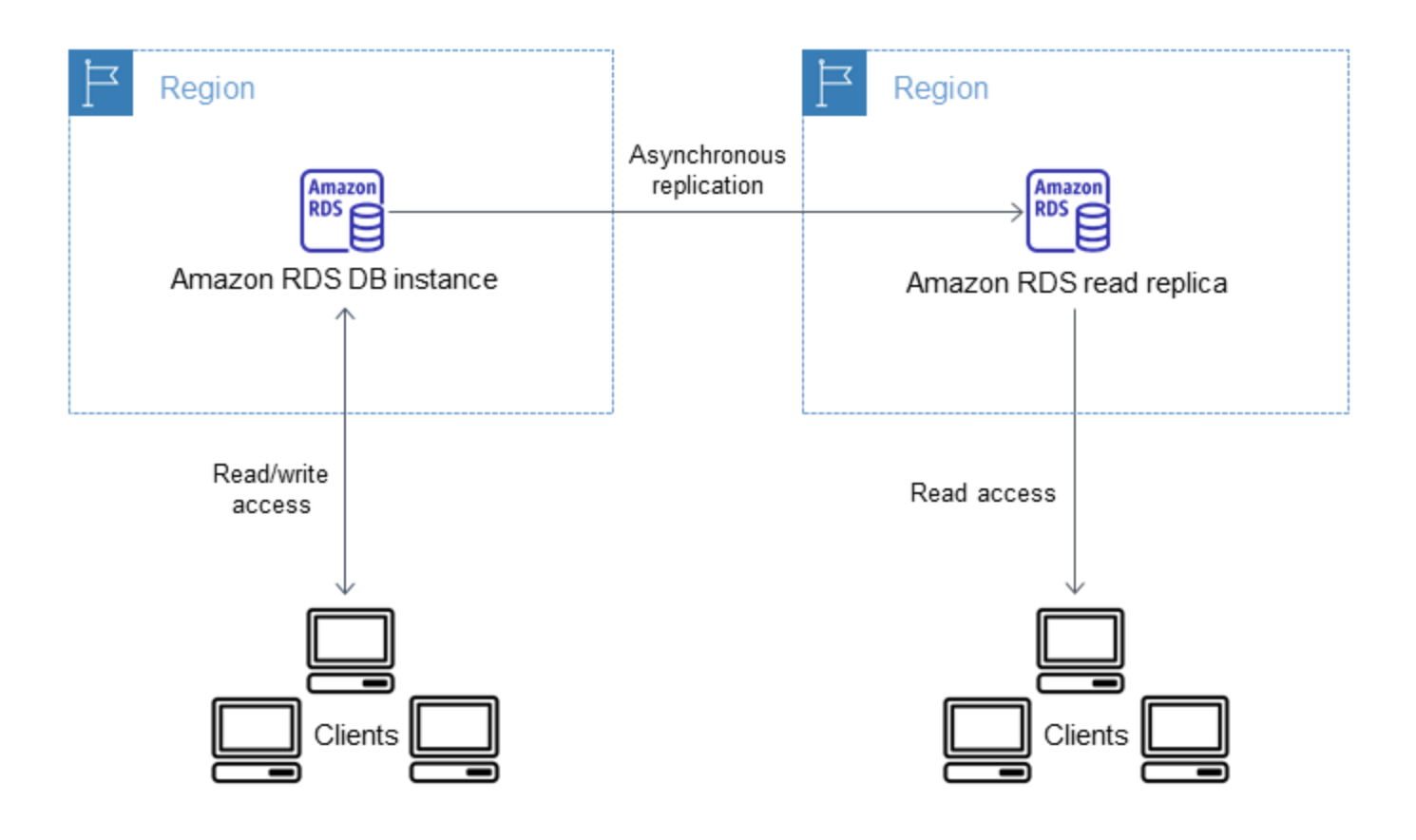
RDS Cross-Region Read Replicas create an asynchronously replicated read-only DB instance in a secondary AWS Region.
Supported for MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server
Cross-Region Read Replicas help to improve
disaster recovery capabilities (reduces RTO and RPO),
scale read operations into a region closer to end users,
migration from a data center in one region to another region
RDS Cross-Region Read Replicas Process
RDS configures the source DB instance as a replication source and setups the specified read replica in the destination AWS Region.
RDS creates an automated DB snapshot of the source DB instance in the source AWS Region.
RDS begins a cross-Region snapshot copy for the initial data transfer.
RDS then uses the copied DB snapshot for the initial data load on the read replica. When the load is complete the DB snapshot copy is deleted.
RDS starts by replicating the changes made to the source instance since the start of the create read replica operation.
RDS Cross-Region Read Replicas Considerations
A source DB instance can have cross-region read replicas in multiple AWS Regions.
Replica lags are higher for Cross-region replicas. This lag time comes from the longer network channels between regional data centers.
RDS can’t guarantee more than five cross-region read replica instances, due to the limit on the number of access control list (ACL) entries for a VPC
Read Replica uses the default DB parameter group and DB option group for the specified DB engine when configured from AWS console.
Read Replica uses the default security group.
Cross-Region RDS read replica can be created from a source RDS DB instance that is not a read replica of another RDS DB instance for Microsoft SQL Server, Oracle, and PostgreSQL DB instances. This limitation doesn’t apply to MariaDB and MySQL DB instances.
Deleting the source for a cross-region read replica will result in
read replica promotion for MariaDB, MySQL, and Oracle DB instances
no read replica promotion for PostgreSQL DB instances and the replication status of the read replica is set to terminated.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your company has HQ in Tokyo and branch offices worldwide and is using logistics software with a multi-regional deployment on AWS in Japan, Europe, and US. The logistic software has a 3-tier architecture and uses MySQL 5.6 for data persistence. Each region has deployed its database. In the HQ region, you run an hourly batch process reading data from every region to compute cross-regional reports that are sent by email to all offices this batch process must be completed as fast as possible to optimize logistics quickly. How do you build the database architecture to meet the requirements?
For each regional deployment, use RDS MySQL with a master in the region and a read replica in the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and send hourly EBS snapshots to the HQ region
For each regional deployment, use RDS MySQL with a master in the region and send hourly RDS snapshots to the HQ region
For each regional deployment, use MySQL on EC2 with a master in the region and use S3 to copy data files hourly to the HQ region
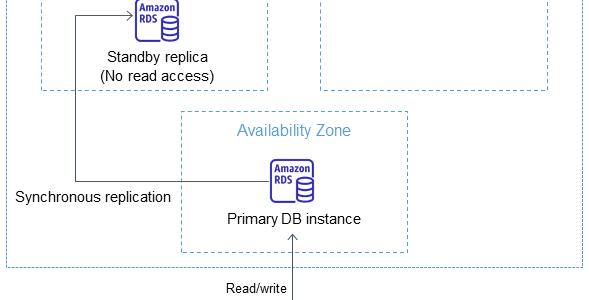
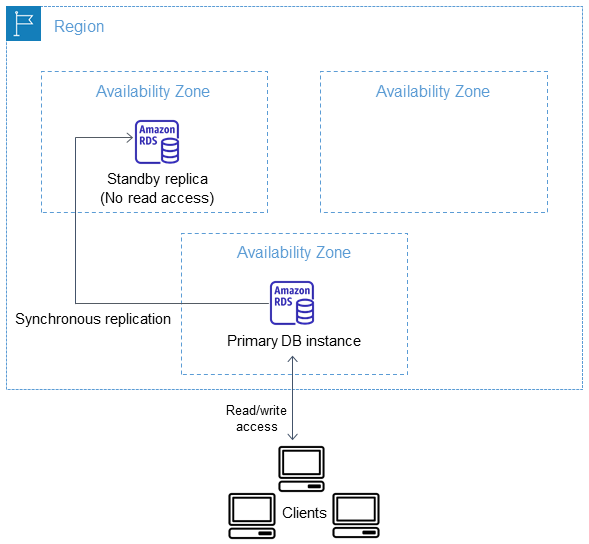
RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different AZ.
RDS performs an automatic failover to the standby, so that database operations can be resumed as soon as the failover is complete.
RDS Multi-AZ deployment maintains the same endpoint for the DB Instance after a failover, so the application can resume database operation without the need for manual administrative intervention.
Multi-AZ is a High Availability feature and NOT a scaling solution for read-only scenarios; a standby replica can’t be used to serve read traffic. To service read-only traffic, use a Read Replica.
Multi-AZ deployments for Oracle, PostgreSQL, MySQL, and MariaDB DB instances use Amazon technology, while SQL Server DB instances use SQL Server Mirroring.
In a Multi-AZ deployment,
RDS automatically provisions and maintains a synchronous standby replica in a different Availability Zone.
Copies of data are stored in different AZs for greater levels of data durability.
Primary DB instance is synchronously replicated across Availability Zones to a standby replica to provide
data redundancy,
eliminate I/O freezes during snapshots and backups
and minimize latency spikes during system backups.
DB instances may have increased write and commit latency compared to a Single AZ deployment, due to the synchronous data replication
Transaction success is returned only if the commit is successful both on the primary and the standby DB
There might be a change in latency if the deployment fails over to the standby replica, although AWS is engineered with low-latency network connectivity between Availability Zones.
When using the BYOL licensing model, a license for both the primary instance and the standby replica is required
For production workloads, it is recommended to use Multi-AZ deployment with Provisioned IOPS and DB instance classes (m1.large and larger), optimized for Provisioned IOPS for fast, consistent performance.
When Single-AZ deployment is modified to a Multi-AZ deployment (for engines other than SQL Server or Amazon Aurora)
RDS takes a snapshot of the primary DB instance from the deployment and restores the snapshot into another Availability Zone.
RDS then sets up synchronous replication between the primary DB instance and the new instance.
This avoids downtime during conversion from Single AZ to Multi-AZ.
An existing Single AZ instance can be converted into a Multi-AZ instance by modifying the DB instance without any downtime.
RDS Multi-AZ Failover Process
In the event of a planned or unplanned outage of the DB instance,
RDS automatically switches to a standby replica in another AZ, if enabled for Multi-AZ.
The time taken for the failover to complete depends on the database activity and other conditions at the time the primary DB instance became unavailable.
Failover times are typically 60-120 secs. However, large transactions or a lengthy recovery process can increase failover time.
Failover mechanism automatically changes the DNS record of the DB instance to point to the standby DB instance.
Multi-AZ switch is seamless to the applications as there is no change in the endpoint URLs but just needs to re-establish any existing connections to the DB instance.
RDS handles failover automatically so that database operations can be resumed as quickly as possible without administrative intervention.
Primary DB instance switches over automatically to the standby replica if any of the following conditions occur:
Primary Availability Zone outage
Loss of network connectivity to primary
Primary DB instance fails
DB instance’s server type is changed
Operating system of the DB instance is undergoing software patching
Compute unit failure on the primary
Storage failure on the primary
A manual failover of the DB instance was initiated using Reboot with failover (also referred to as Forced Failover)
If the Multi-AZ DB instance has failed over, can be determined by
DB event subscriptions can be set up to notify you via email or SMS that a failover has been initiated.
DB events can be viewed via the Amazon RDS console or APIs.
The current state of the Multi-AZ deployment can be viewed via the RDS console and APIs.
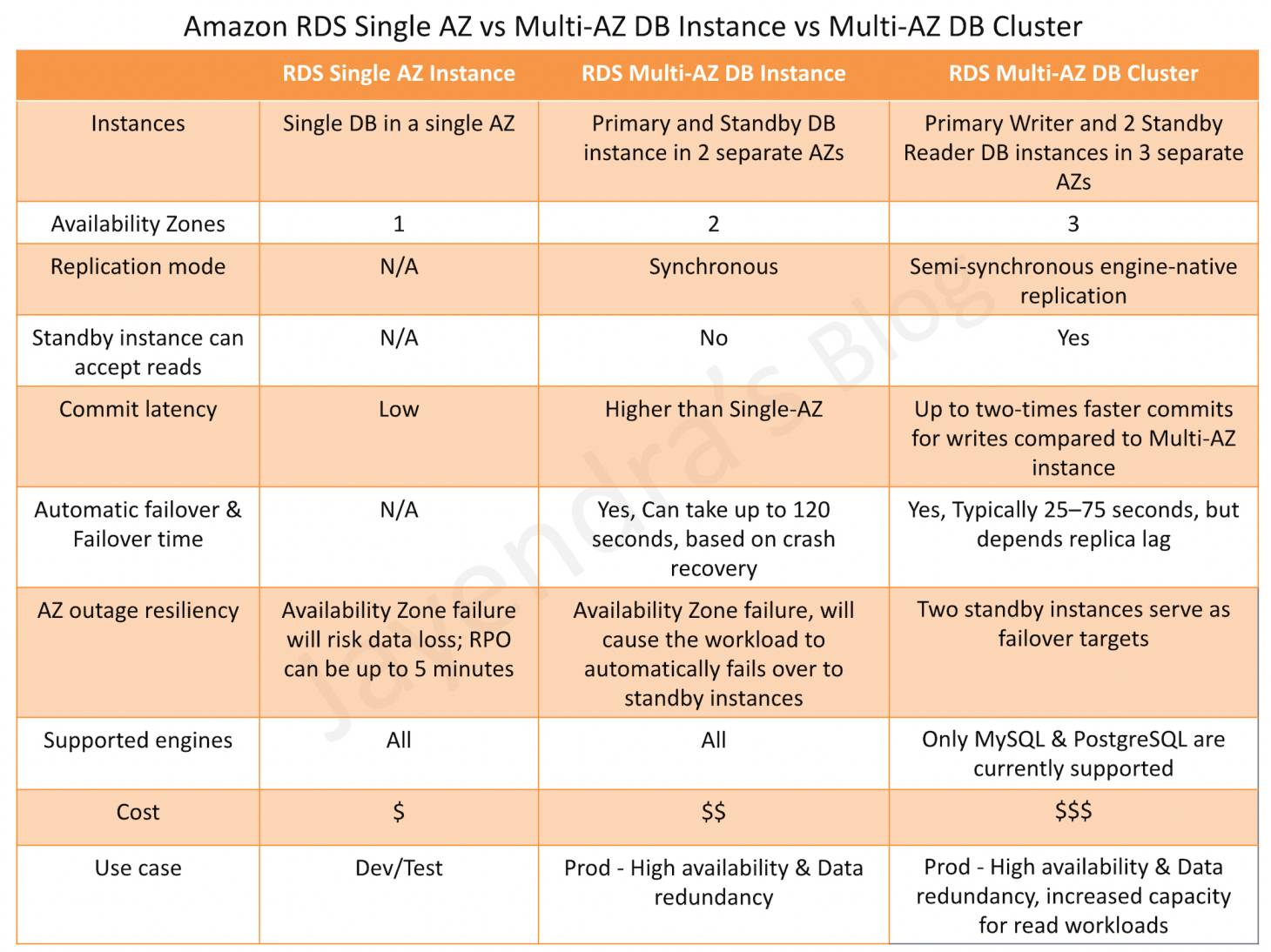
Multi-AZ DB Instance vs Multi-AZ DB Cluster
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
AWS Storage Options Whitepaper with RDS, DynamoDB & Database on EC2 Cont.
Provides a brief summary for the Ideal Use cases, Anti-Patterns and other factors for Amazon RDS, DynamoDB & Databases on EC2 storage options
Amazon RDS
RDS is a web service that provides the capabilities of MySQL, Oracle, MariaDB, Postgres or Microsoft SQL Server relational database as a managed, cloud-based service
RDS eliminates much of the administrative overhead associated with launching, managing, and scaling your own relational database on Amazon EC2 or in another computing environment.
Ideal Usage Patterns
RDS is a great solution for cloud-based fully-managed relational database
RDS is also optimal for new applications with structured data that requires more sophisticated querying and joining capabilities than that provided by Amazon’s NoSQL database offering, DynamoDB.
RDS provides full compatibility with the databases supported and direct access to native database engines, code and librariesand is ideal for existing applications that rely on these databases
Anti-Patterns
Index and query-focused data
If the applications don’t require advanced features such as joins and complex transactions and is more oriented toward indexing and querying data, DynamoDB would be more appropriate for this needs
Numerous BLOBs
If the application makes heavy use of files (audio files, videos, images, etc), it is a better choice to use S3 to store the objects instead of database engines Blob feature and use RDS or DynamoDB only to save the metadata
Automated scalability
RDS provides pushbutton scaling and it only scales up and has limited scale out ability. If fully-automated scaling is needed, DynamoDB may be a better choice.
Complete control
RDS does not provide admin access and does not enable the full feature set of the database engines.
So if the application requires complete, OS-level control of the database server with full root or admin login privileges, a self-managed database on EC2 may be a better match.
Other database platforms
RDS, at this time, provides a MySQL, Oracle, MariaDB, PostgreSQL and SQL Server databases.
If any other database platform (such as IBM DB2, Informix, or Sybase) is needed, it should be deployed on a self-managed database on an EC2 instance by using a relational database AMI, or by installing database software on an EC2 instance.
Performance
RDS Provisioned IOPS, where the IOPS can be specified when the instance is launched and is guaranteed over the life of the instance, provides a high-performance storage option designed to deliver fast, predictable, and consistent performance for I/O intensive transactional database workload
Durability and Availability
RDS leverages Amazon EBS volumes as its data store
RDS provides database backups, for enhanced durability, which are replicated across multiple AZ’s
Automated backups
If enabled, RDS will automatically perform a full daily backup of your data during the specified backup window, and will also capture DB transaction logs
User initiated backups
User can initiate backups at time and they are not deleted unless deleted explicitly by the user
RDS Multi AZ’s feature enhances both the durability and the availability of the database by synchronously replicating the data between a primary RDS DB instance and a standby instance in another Availability Zone, which prevents data loss,
RDS provides a DNS endpoint and in case of an failure on the primary, it automatically fails over to the standby instance
RDS also allows Read replicas for the supported databases, which are replicated asynchronously
Cost Model
RDS offers a tiered pricing structure, based on the size of the database instance, the deployment type (Single-AZ/Multi-AZ), and the AWS region.
Pricing for RDS is based on several factors: the DB instance hours (per hour), the amount of provisioned database storage (per GB-month and per million I/O requests), additional backup storage (per GB-month), and data transfer in/out (per GB per month)
Scalability and Elasticity
RDS resources can be scaled elastically in several dimensions: database storage size, database storage IOPS rate, database instance compute capacity, and the number of read replicas
RDS supports “pushbutton scaling” of both database storage and compute resources. Additional storage can either be added immediately or during the next maintenance cycle
RDS for MySQL also enables you to scale out beyond the capacity of a single database deployment for read-heavy database workloads by creating one or more read replicas.
Multiple RDS instances can also be configured to leverage database partitioning or sharding to spread the workload over multiple DB instances, achieving even greater database scalability and elasticity.
Interfaces
RDS APIs and the AWS Management Console provide a management interface that allows you to create, delete, modify, and terminate RDS DB instances; to create DB snapshots; and to perform point-in-time restores
There is no AWS data API for Amazon RDS.
Once a database is created, RDS provides a DNS endpoint for the database which can be used to connect to the database.
Endpoint does not change over the lifetime of the instance even during the failover in case of Multi-AZ configuration
Amazon DynamoDB
Amazon DynamoDB is a fast, fully-managed NoSQL database service that makes it simple and cost-effective to store and retrieve any amount of data, and serve any level of request traffic.
DynamoDB being a managed service helps offload the administrative burden of operating and scaling a highly-available distributed database cluster.
DynamoDB helps meet the latency and throughput requirements of highly demanding applications by providing extremely fast and predictable performance with seamless throughput and storage scalability.
DynamoDB provides both eventually-consistent reads (by default), and strongly-consistent reads (optional), as well as implicit item-level transactions for item put, update, delete, conditional operations, and increment/decrement.
Amazon DynamoDB handles the data as below :-
DynamoDB stores structured data in tables, indexed by primary key, and allows low-latency read and write access to items.
DynamoDB supports three data types: number, string, and binary, in both scalar and multi-valued sets.
Tables do not have a fixed schema, so each data item can have a different number of attributes.
Primary key can either be a single-attribute hash key or a composite hash-range key.
Local secondary indexes provide additional flexibility for querying against attributes other than the primary key.
Ideal Usage Patterns
DynamoDB is ideal for existing or new applications that need a flexible NoSQL database with low read and write latencies, and the ability to scale storage and throughput up or down as needed without code changes or downtime.
Use cases require a highly available and scalable database because downtime or performance degradation has an immediate negative impact on an organization’s business. for e.g. mobile apps, gaming, digital ad serving, live voting and audience interaction for live events, sensor networks, log ingestion, access control for web-based content, metadata storage for S3 objects, e-commerce shopping carts, and web session management
Anti-Patterns
Structured data with Join and/or Complex Transactions
If the application uses structured data and required joins, complex transactions or other relationship infrastructure provided by traditional database platforms, it is better to use RDS or Database installed on an EC2 instance
Large Blob data
If the application uses large blob data for e.g. media, files, videos etc., it is better to use S3 to store the objects and use DynamoDB to store metadatafor e.g. name, size, content-type etc
Large Objects with Low I/O rate
DynamoDB uses SSD drives and is optimized for workloads with a high I/O rate per GB stored. If the applications stores very large amounts of data that are infrequently accessed, S3 might be a better choice
Prewritten application with databases
For Porting an existing application using databases, RDS or database installed on the EC2 instance would be a better and seamless solution
Performance
SSDs and limited indexing on attributes provides high throughput and low latency and drastically reduces the cost of read and write operations.
Predictable performance can be achieved by defining the provisioned throughput capacity required for a given table.
DynamoDB handles the provisioning of resources to achieve the requested throughput rate, taking away the burden to think about instances, hardware, memory, and other factors that can affect an application’s throughput rate.
Provisioned throughput capacity reservations are elastic and can be increased or decreased on demand.
Durability and Availability
DynamoDB has built-in fault tolerance that automatically and synchronously replicates data across three AZ’s in a region for high availability and to help protect data against individual machine, or even facility failures.
Cost Model
DynamoDB has three pricing components: provisioned throughput capacity (per hour), indexed data storage (per GB per month), data transfer in or out (per GB per month)
Scalability and Elasticity
DynamoDB is both highly-scalable and elastic.
DynamoDB provides unlimited storage capacity, and the service automatically allocates more storage as the demand increases
Data is automatically partitioned and re-partitioned as needed, while the use of SSDs provides predictable low-latency response times at any scale.
DynamoDB is also elastic, in that you can simply “dial-up” or “dial-down” the read and write capacity of a table as your needs change.
Interfaces
DynamoDB provides a low-level REST API, as well as higher-level SDKs in different languages
APIs provide both a management and data interface for Amazon DynamoDB, that enable table management (creating, listing, deleting, and obtaining metadata) and working with attributes (getting, writing, and deleting attributes; query using an index, and full scan).
Databases on EC2
EC2 with EBS volumes allows hosting a self managed relational database
Ready to use, prebuilt AMIs are also available from leading database solutions
Ideal Usage Patterns
Self managed database on EC2 is an ideal scenario for users whose application requires a specific traditional relational database not supported by Amazon RDS for e.g. IBM DB2, Informix, or Sybase
Users or applications that require a maximum level of administrative control and configurability which is not provided by RDS
Anti-Patterns
Index and query-focused data
If the applications don’t require advanced features such as joins and complex transactions and is more oriented toward indexing and querying data, DynamoDB would be more appropriate for this needs
Numerous BLOBs
If the application makes heavy use of files (audio files, videos, images, and so on), it is a better choice to use S3 to store the objects instead of database engines Blob feature and use RDS or DynamoDB only to save the metadata
Automated scalability
Relational databases on EC2 leverages the scalability and elasticity of the underlying AWS platform, but this requires system administrators or DBAs to perform a manual or scripted task. If you need pushbutton scaling or fully-automated scaling, DynamoDB or RDS may be a better choice.
RDS supported database platforms
If the application using RDS supported database engine and all the features are available, RDS would be a better choice instead of self managed relational database on EC2
Performance
Performance depends on the size of the underlying EC2 instance, the number and configuration of the EBS volumes and the database itself
Performance can be increased by scaling up memory and compute resources by choosing a larger Amazon EC2 instance size.
For database storage, it is usually best to use EBS Provisioned IOPS volumes. To scale up I/O performance, the Provisioned IOPS can be increased, the number of EBS volumes changed, or use software RAID 0 (disk striping) across multiple EBS volumes, which will aggregate total IOPS and bandwidth.
Durability & Availability
As the database on EC2 uses EBS as storage, it has the same durability and availability provided by EBS and can be further enhanced by using EBS snapshots or by using third-party database backup utilities (such as Oracle’s RMAN) to store database backups in Amazon S3
Cost Model
Cost for running a database on EC2 instance is mainly determined by the size and the number of EC2 instance running, the size of the EBS volume used for database storage and any third party licensing cost for the database
Scalability & Elasticity
Users of traditional relational database solutions on Amazon EC2 can take advantage of the scalability and elasticity of the underlying AWS platform by creating AMI and spawning multiple instances
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which of the following are use cases for Amazon DynamoDB? Choose 3 answers
Storing BLOB data.
Managing web sessions
Storing JSON documents
Storing metadata for Amazon S3 objects
Running relational joins and complex updates.
Storing large amounts of infrequently accessed data.
A client application requires operating system privileges on a relational database server. What is an appropriate configuration for highly available database architecture?
A standalone Amazon EC2 instance
Amazon RDS in a Multi-AZ configuration
Amazon EC2 instances in a replication configuration utilizing a single Availability Zone
Amazon EC2 instances in a replication configuration utilizing two different Availability Zones
You are developing a new mobile application and are considering storing user preferences in AWS, which would provide a more uniform cross-device experience to users using multiple mobile devices to access the application. The preference data for each user is estimated to be 50KB in size. Additionally 5 million customers are expected to use the application on a regular basis. The solution needs to be cost-effective, highly available, scalable and secure, how would you design a solution to meet the above requirements?
Setup an RDS MySQL instance in 2 availability zones to store the user preference data. Deploy a public facing application on a server in front of the database to manage security and access credentials
Setup a DynamoDB table with an item for each user having the necessary attributes to hold the user preferences. The mobile application will query the user preferences directly from the DynamoDB table. Utilize STS. Web Identity Federation, and DynamoDB Fine Grained Access Control to authenticate and authorize access (DynamoDB provides high availability as it synchronously replicates data across three facilities within an AWS Region and scalability as it is designed to scale its provisioned throughput up or down while still remaining available. Also suitable for storing user preference data)
Setup an RDS MySQL instance with multiple read replicas in 2 availability zones to store the user preference data .The mobile application will query the user preferences from the read replicas. Leverage the MySQL user management and access privilege system to manage security and access credentials.
Store the user preference data in S3 Setup a DynamoDB table with an item for each user and an item attribute pointing to the user’ S3 object. The mobile application will retrieve the S3 URL from DynamoDB and then access the S3 object directly utilize STS, Web identity Federation, and S3 ACLs to authenticate and authorize access.
A customer is running an application in US-West (Northern California) region and wants to setup disaster recovery failover to the Asian Pacific (Singapore) region. The customer is interested in achieving a low Recovery Point Objective (RPO) for an Amazon RDS multi-AZ MySQL database instance. Which approach is best suited to this need?
Synchronous replication
Asynchronous replication
Route53 health checks
Copying of RDS incremental snapshots
You are designing a file -sharing service. This service will have millions of files in it. Revenue for the service will come from fees based on how much storage a user is using. You also want to store metadata on each file, such as title, description and whether the object is public or private. How do you achieve all of these goals in a way that is economical and can scale to millions of users?
Store all files in Amazon Simple Storage Service (53). Create a bucket for each user. Store metadata in the filename of each object, and access it with LIST commands against the S3 API.
Store all files in Amazon 53. Create Amazon DynamoDB tables for the corresponding key -value pairs on the associated metadata, when objects are uploaded.
Create a striped set of 4000 IOPS Elastic Load Balancing volumes to store the data. Use a database running in Amazon Relational Database Service (RDS) to store the metadata.
Create a striped set of 4000 IOPS Elastic Load Balancing volumes to store the data. Create Amazon DynamoDB tables for the corresponding key-value pairs on the associated metadata, when objects are uploaded.
Company ABCD has recently launched an online commerce site for bicycles on AWS. They have a “Product” DynamoDB table that stores details for each bicycle, such as, manufacturer, color, price, quantity and size to display in the online store. Due to customer demand, they want to include an image for each bicycle along with the existing details. Which approach below provides the least impact to provisioned throughput on the “Product” table?
Serialize the image and store it in multiple DynamoDB tables
Create an “Images” DynamoDB table to store the Image with a foreign key constraint to the “Product” table
Add an image data type to the “Product” table to store the images in binary format
Store the images in Amazon S3 and add an S3 URL pointer to the “Product” table item for each image