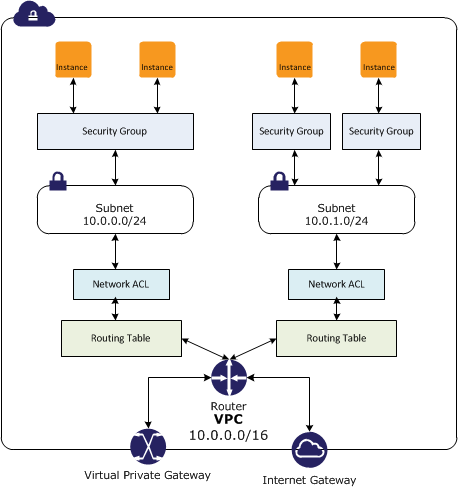
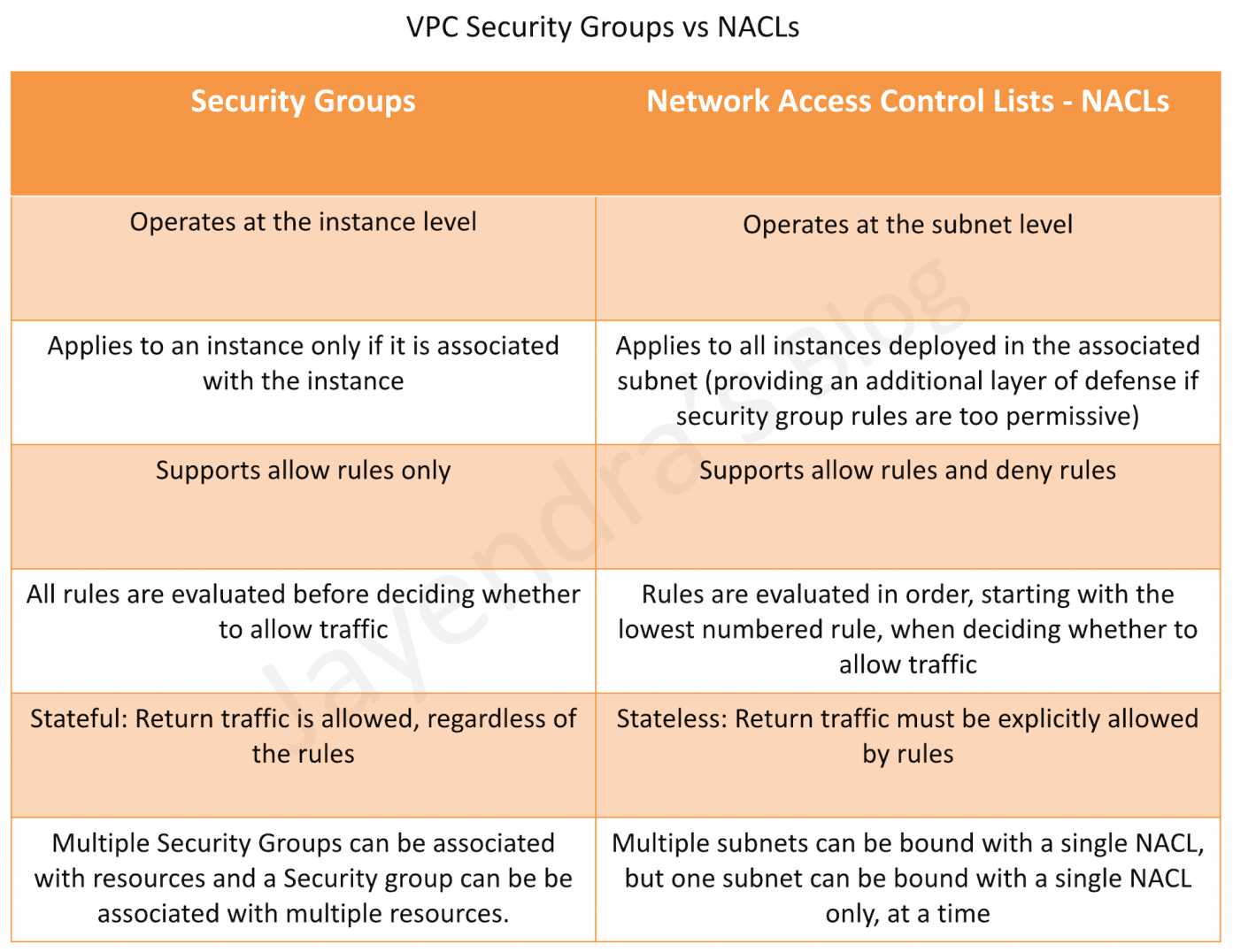
Key factors for Disaster Planning
Recovery Time Objective (RTO) – The time it takes after a disruption to restore a business process to its service level, as defined by the operational level agreement (OLA) for e.g. if the RTO is 1 hour and disaster occurs @ 12:00 p.m (noon), then the DR process should restore the systems to an acceptable service level within an hour i.e. by 1:00 p.m
Recovery Point Objective (RPO) – The acceptable amount of data loss measured in time before the disaster occurs. for e.g., if a disaster occurs at 12:00 p.m (noon) and the RPO is one hour, the system should recover all data that was in the system before 11:00 a.m.
Disaster Recovery Scenarios
- Disaster Recovery scenarios can be implemented with the Primary infrastructure running in your data center in conjunction with the AWS
- Disaster Recovery Scenarios still apply if Primary site is running in AWS using AWS multi region feature.
- Combination and variation of the below is always possible.
Disaster Recovery Scenarios Options
- Backup & Restore (Data backed up and restored)
- Pilot Light (Only Minimal critical functionalities)
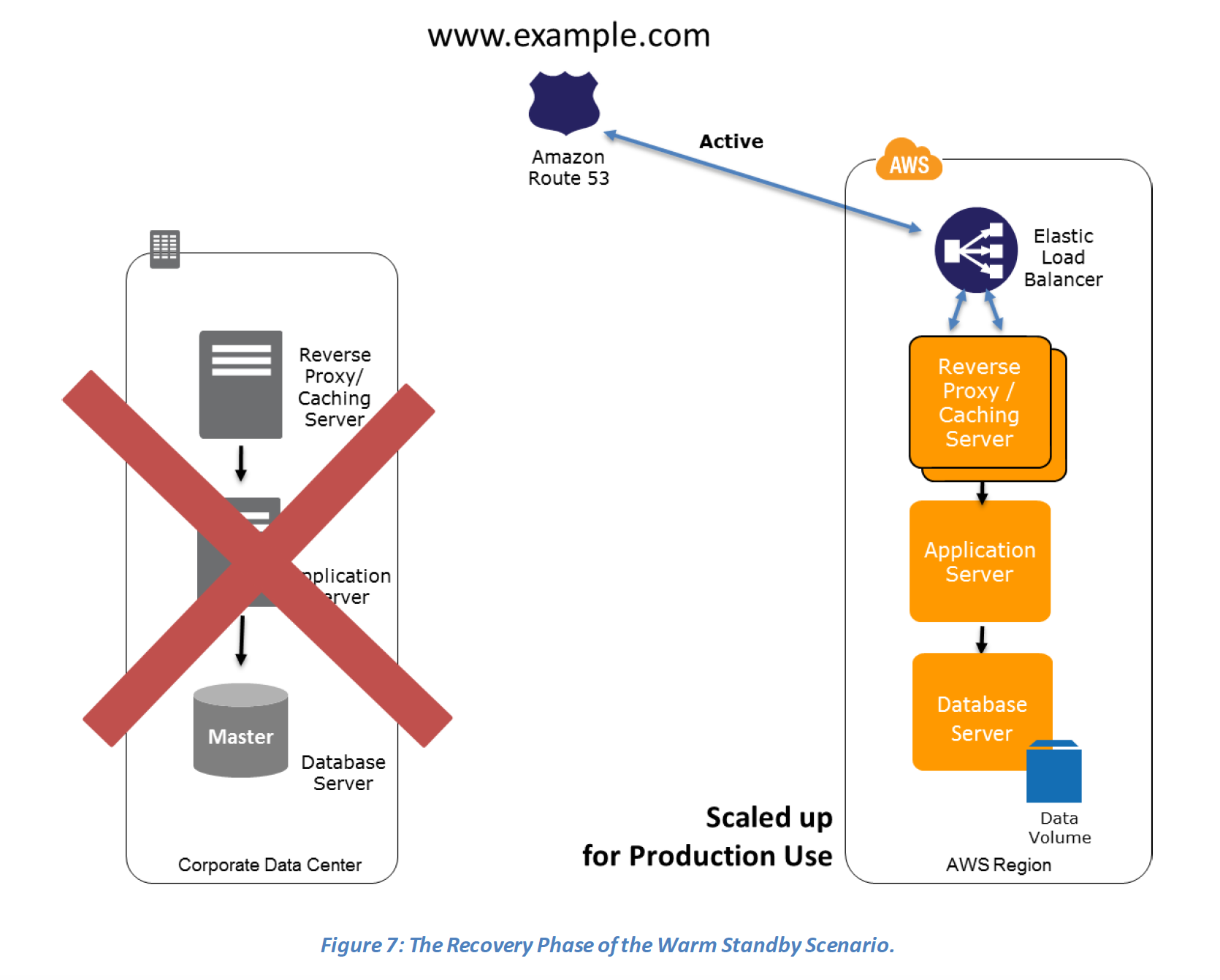
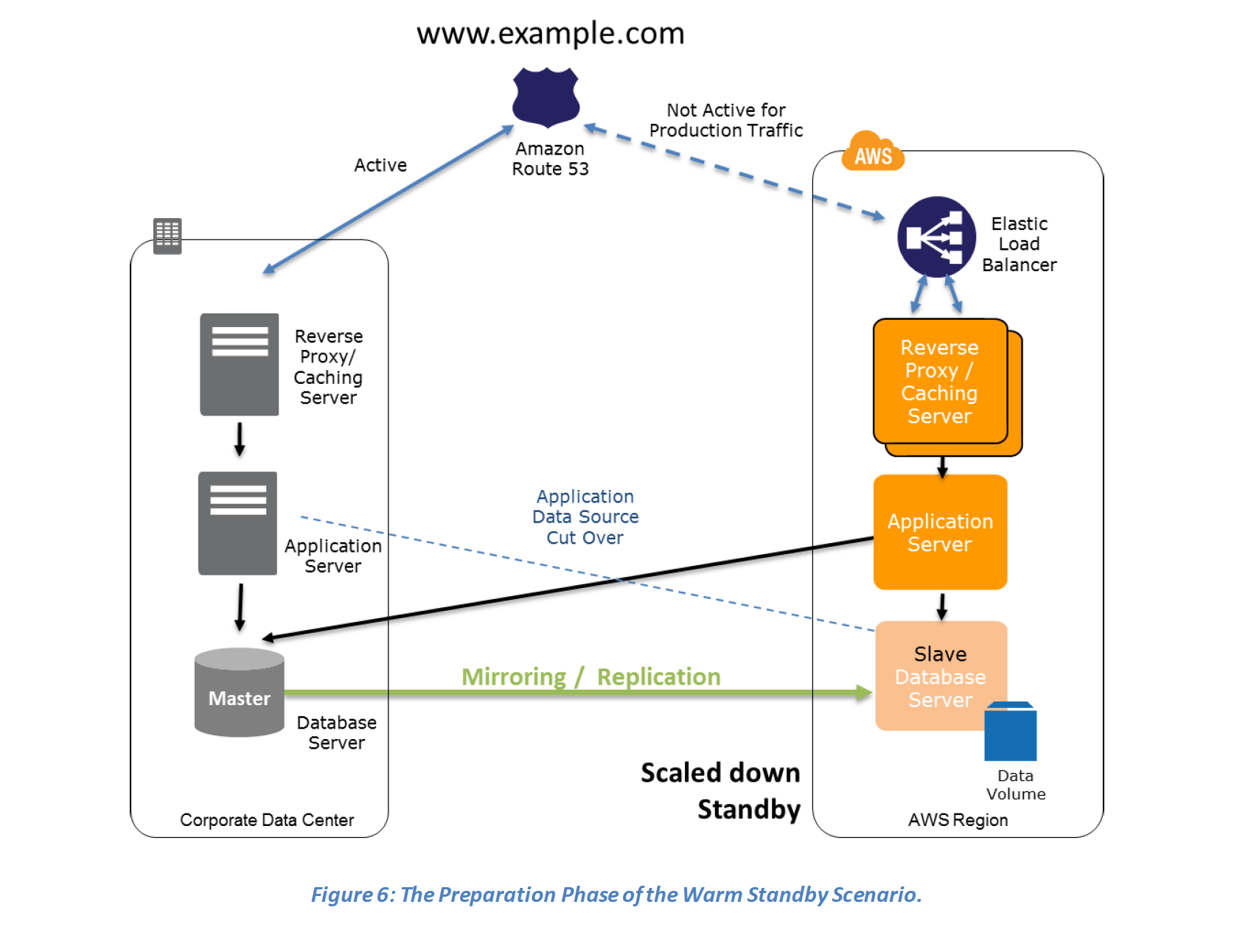
- Warm Standby (Fully Functional Scaled down version)
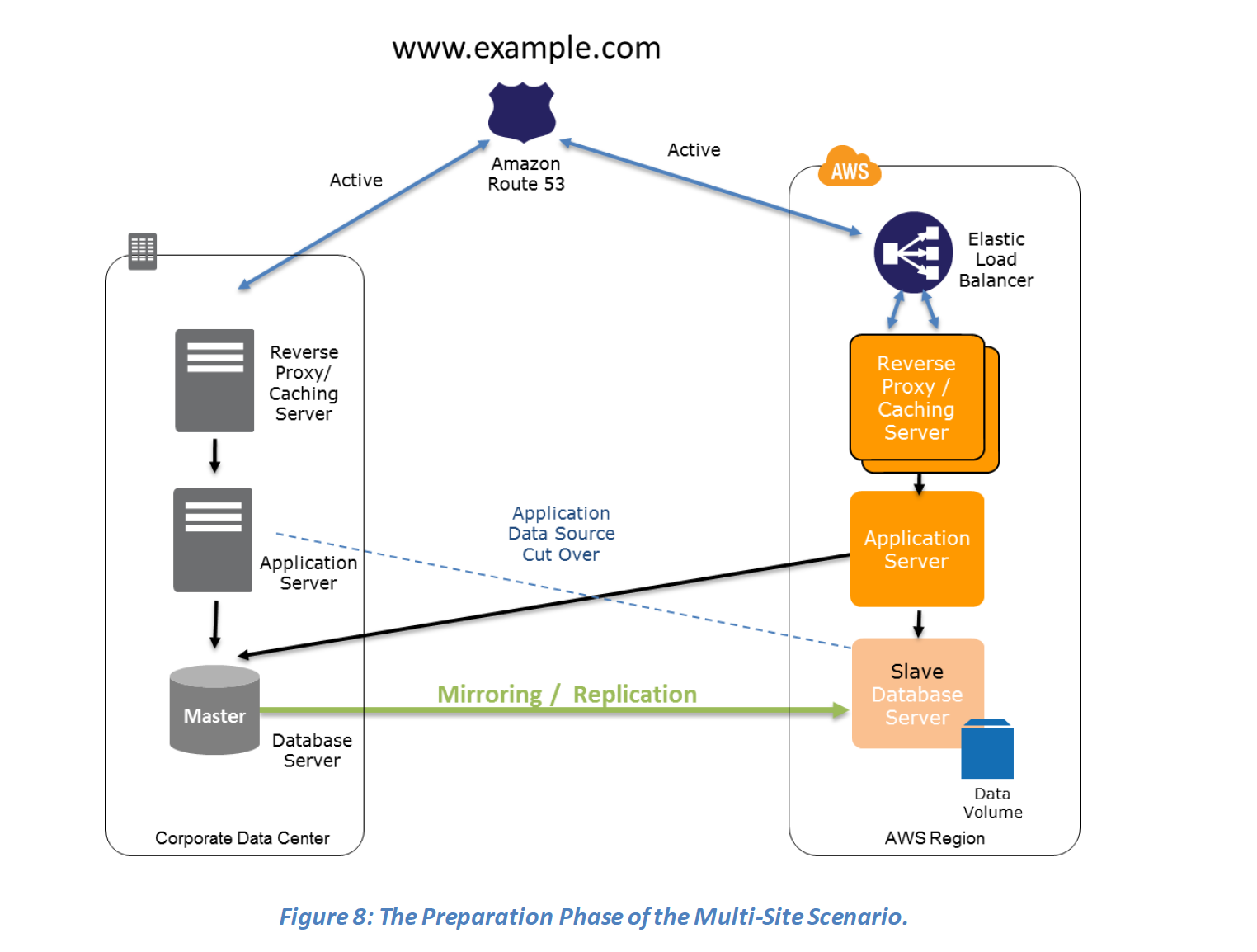
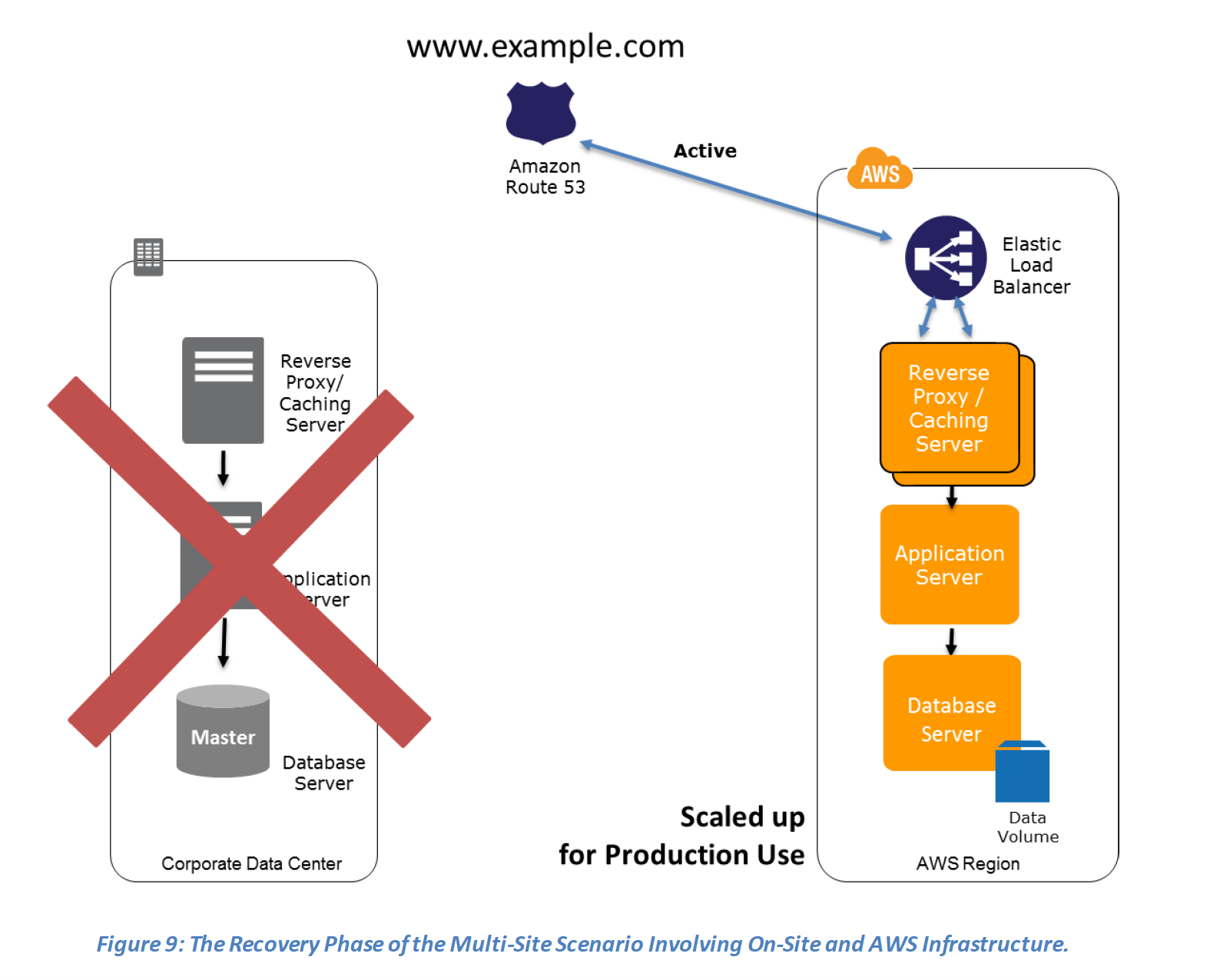
- Multi-Site (Active-Active)
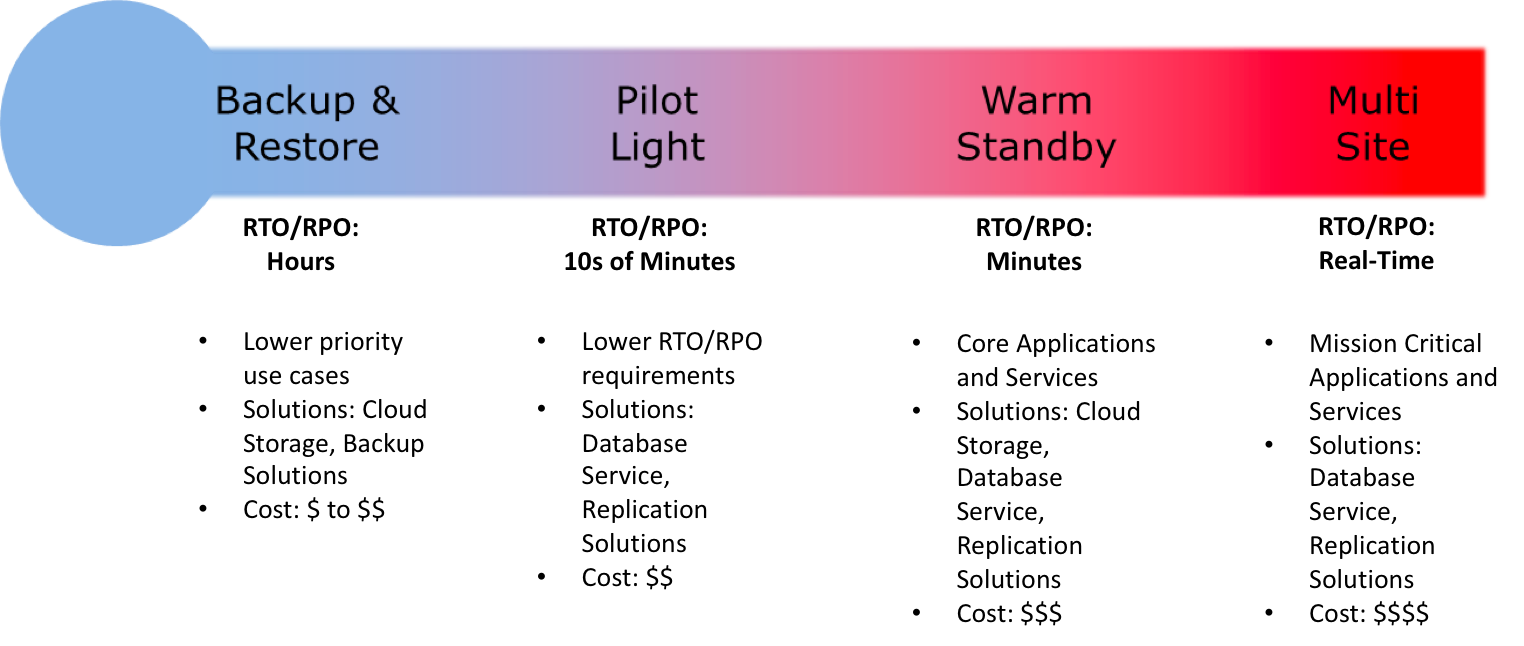
For the DR scenarios options, RTO and RPO reduces with an increase in Cost as you move from Backup & Restore option (left) to Multi-Site option (right)
Backup & Restore
AWS can be used to backup the data in a cost effective, durable and secure manner as well as recover the data quickly and reliably.
Backup phase
In most traditional environments, data is backed up to tape and sent off-site regularly taking longer time to restore the system in the event of a disruption or disaster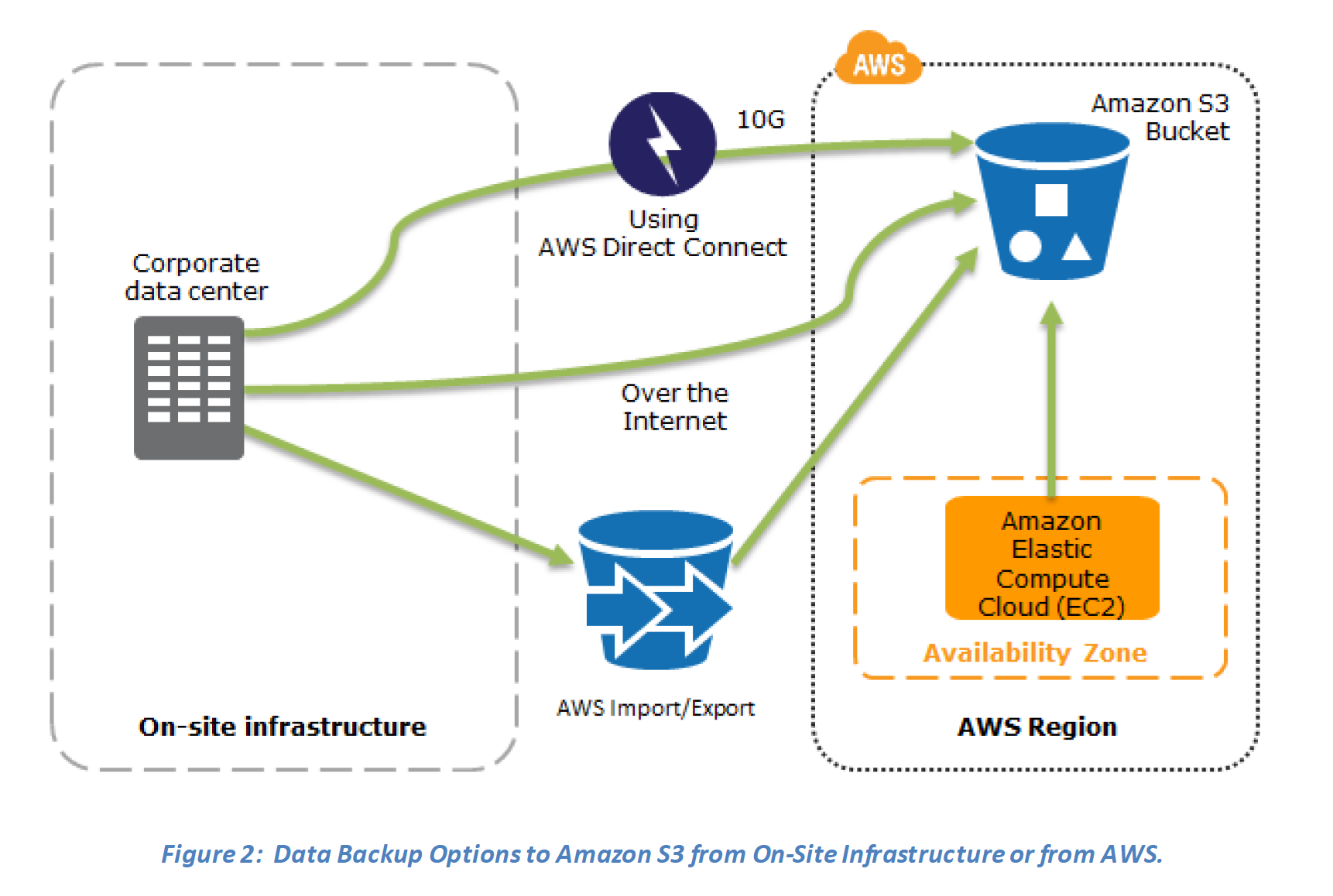
- Amazon S3 can be used to backup the data and perform a quick restore and is also available from any location
- AWS Import/Export can be used to transfer large data sets by shipping storage devices directly to AWS bypassing the Internet
- Amazon Glacier can be used for archiving data, where retrieval time of several hours are adequate and acceptable
- AWS Storage Gateway enables snapshots (used to created EBS volumes) of the on-premises data volumes to be transparently copied into S3 for backup. It can be used either as a backup solution (Gateway-stored volumes) or as a primary data store (Gateway-cached volumes)
- AWS Direct connect can be used to transfer data directly from On-Premise to Amazon consistently and at high speed
- Snapshots of Amazon EBS volumes, Amazon RDS databases, and Amazon Redshift data warehouses can be stored in Amazon S3
Restore phase
Data backed up then can be used to quickly restore and create Compute and Database instances
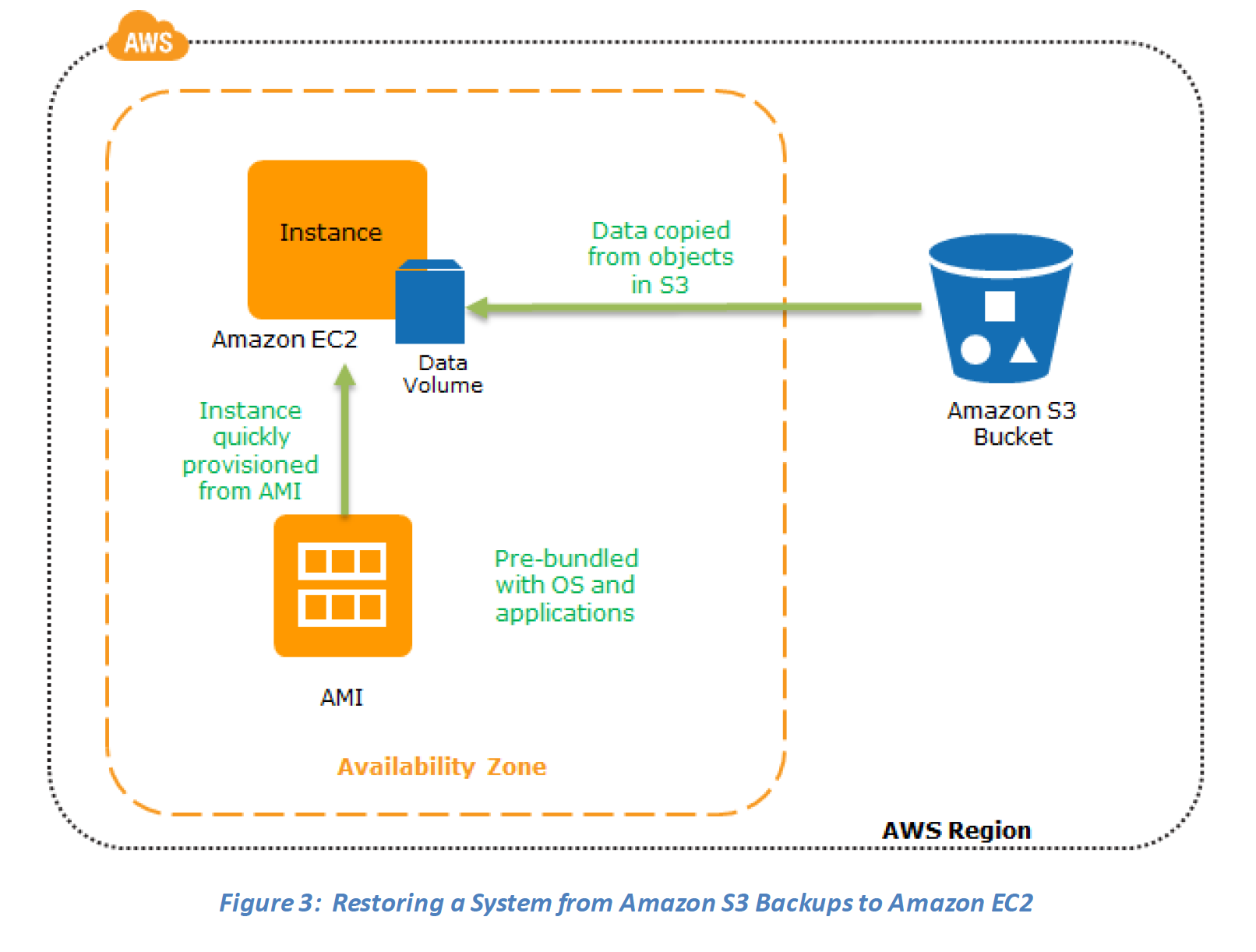 Key steps for Backup and Restore:
Key steps for Backup and Restore:
1. Select an appropriate tool or method to back up the data into AWS.
2. Ensure an appropriate retention policy for this data.
3. Ensure appropriate security measures are in place for this data, including encryption and access policies.
4. Regularly test the recovery of this data and the restoration of the system.
Pilot Light
In a Pilot Light Disaster Recovery scenario option a minimal version of an environment is always running in the cloud, which basically host the critical functionalities of the application for e.g. databases
In this approach :-
- Maintain a pilot light by configuring and running the most critical core elements of your system in AWS for e.g. Databases where the data needs to be replicated and kept updated.
- During recovery, a full-scale production environment, for e.g. application and web servers, can be rapidly provisioned (using preconfigured AMIs and EBS volume snapshots) around the critical core
- For Networking, either a ELB to distribute traffic to multiple instances and have DNS point to the load balancer or preallocated Elastic IP address with instances associated can be used
Preparation phase steps :
- Set up Amazon EC2 instances or RDS instances to replicate or mirror data critical data
- Ensure that all supporting custom software packages available in AWS.
- Create and maintain AMIs of key servers where fast recovery is required.
- Regularly run these servers, test them, and apply any software updates and configuration changes.
- Consider automating the provisioning of AWS resources.



 Key steps for Backup and Restore:
Key steps for Backup and Restore: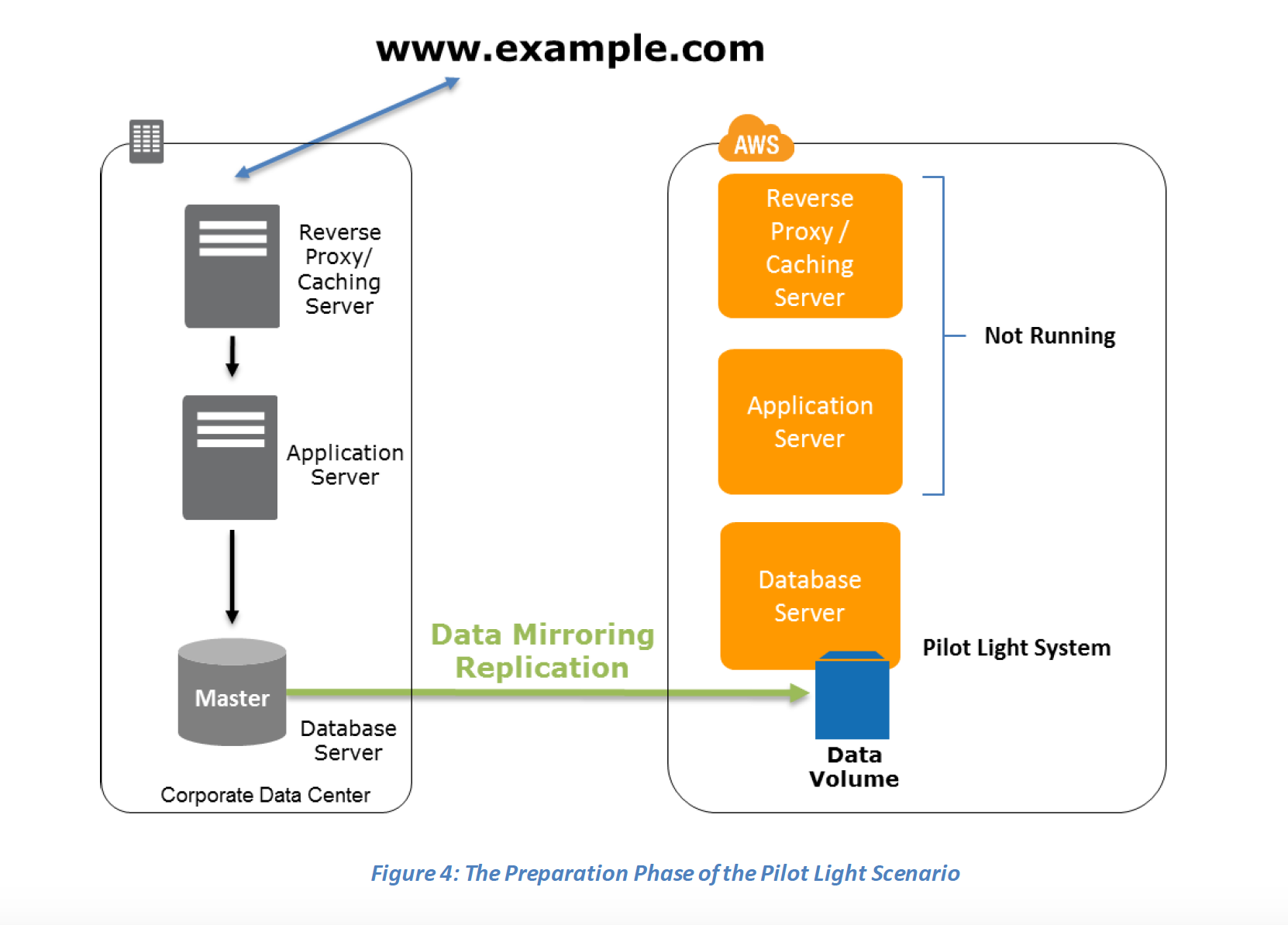
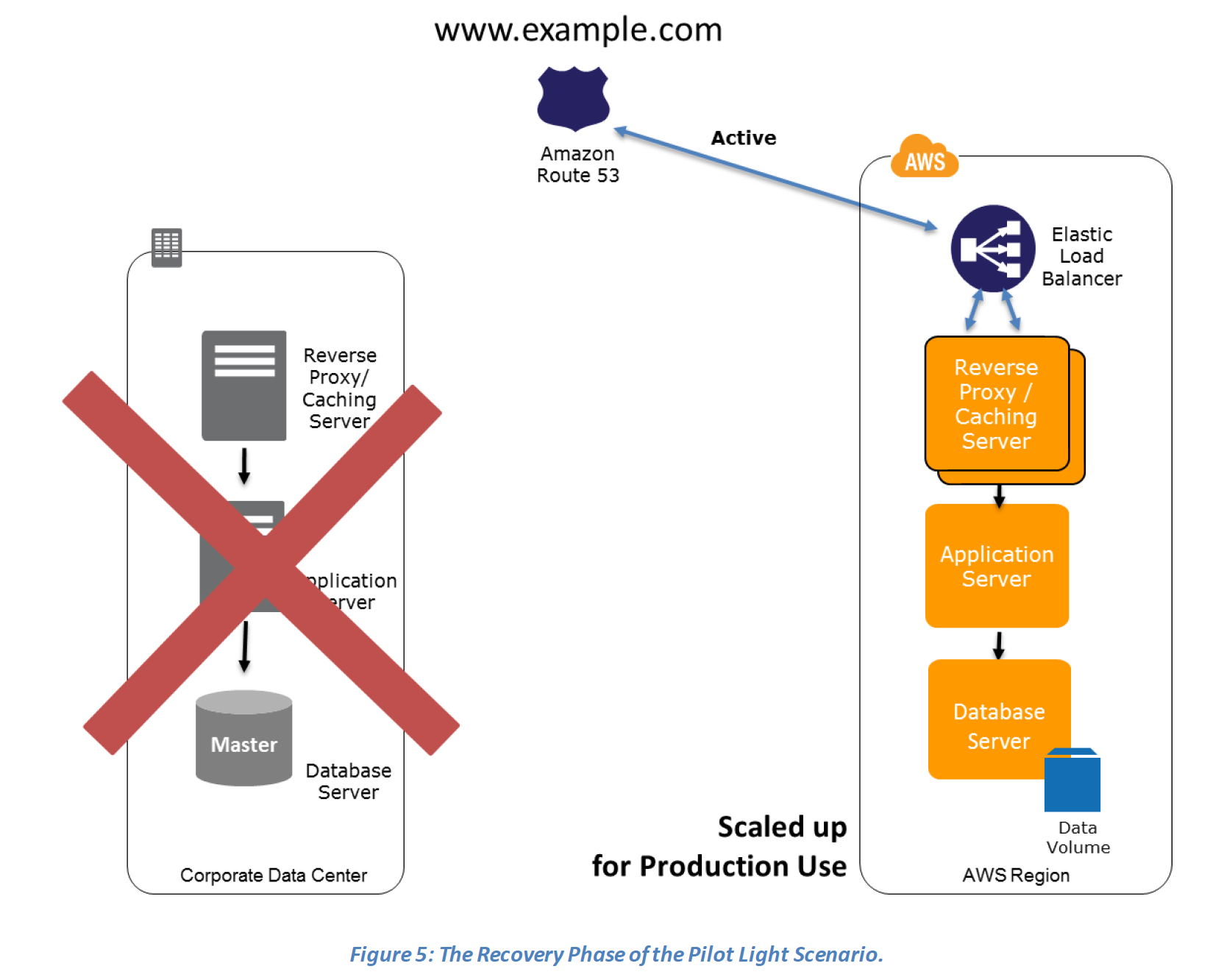
 Recovery phase Steps:
Recovery phase Steps: