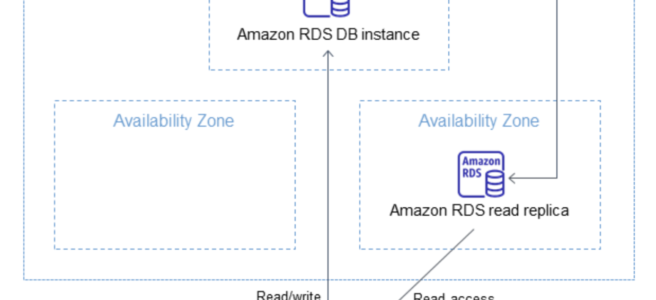
RDS Read Replicas
-
RDS Read Replica is a read-only copy of the DB instance.
- RDS Read Replicas provide enhanced performance and durability for RDS.
- RDS Read Replicas allow elastic scaling beyond the capacity constraints of a single DB instance for read-heavy database workloads.
- RDS Read replicas enable increased scalability and database availability in the case of an AZ failure.
- Read Replicas can help reduce the load on the source DB instance by routing read queries from applications to the Read Replica.
- Read replicas can also be promoted when needed to become standalone DB instances.
- RDS read replicas can be Multi-AZ i.e. set up with their own standby instances in a different AZ.
- One or more replicas of a given source DB Instance can serve high-volume application read traffic from multiple copies of the data, thereby increasing aggregate read throughput.
- RDS uses DB engines’ built-in replication functionality to create a special type of DB instance called a Read Replica from a source DB instance. It uses the engines’ native asynchronous replication to update the read replica whenever there is a change to the source DB instance.
- Read Replicas are eventually consistent due to asynchronous replication.
- RDS sets up a secure communications channel using public-key encryption between the source DB instance and the read replica, even when replicating across regions.
- Read replica operates as a DB instance that allows only read-only connections. Applications can connect to a read replica just as they would to any DB instance.
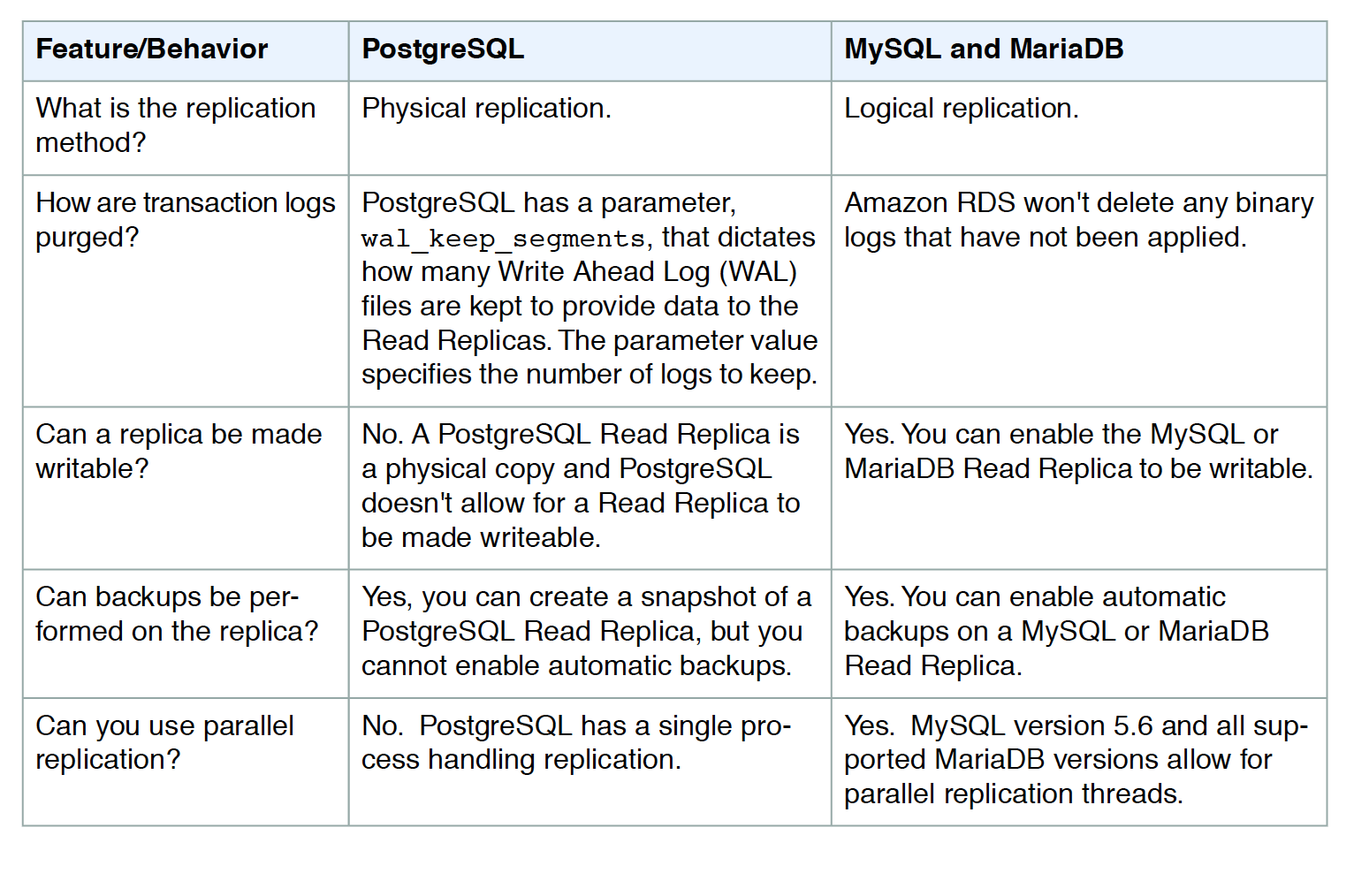
- Read replicas are available in RDS for MySQL, MariaDB, PostgreSQL, Oracle, SQL Server, and Db2.
- RDS replicates all databases in the source DB instance.
- RDS supports replication between an RDS MySQL or MariaDB DB instance and a MySQL or MariaDB instance that is external to RDS using Binary Log File Position or Global Transaction Identifiers (GTIDs) replication.
- Up to 15 Read Replicas can be created from one source DB instance (including up to 5 cross-region read replicas) for MySQL, MariaDB, PostgreSQL, SQL Server, and Oracle.
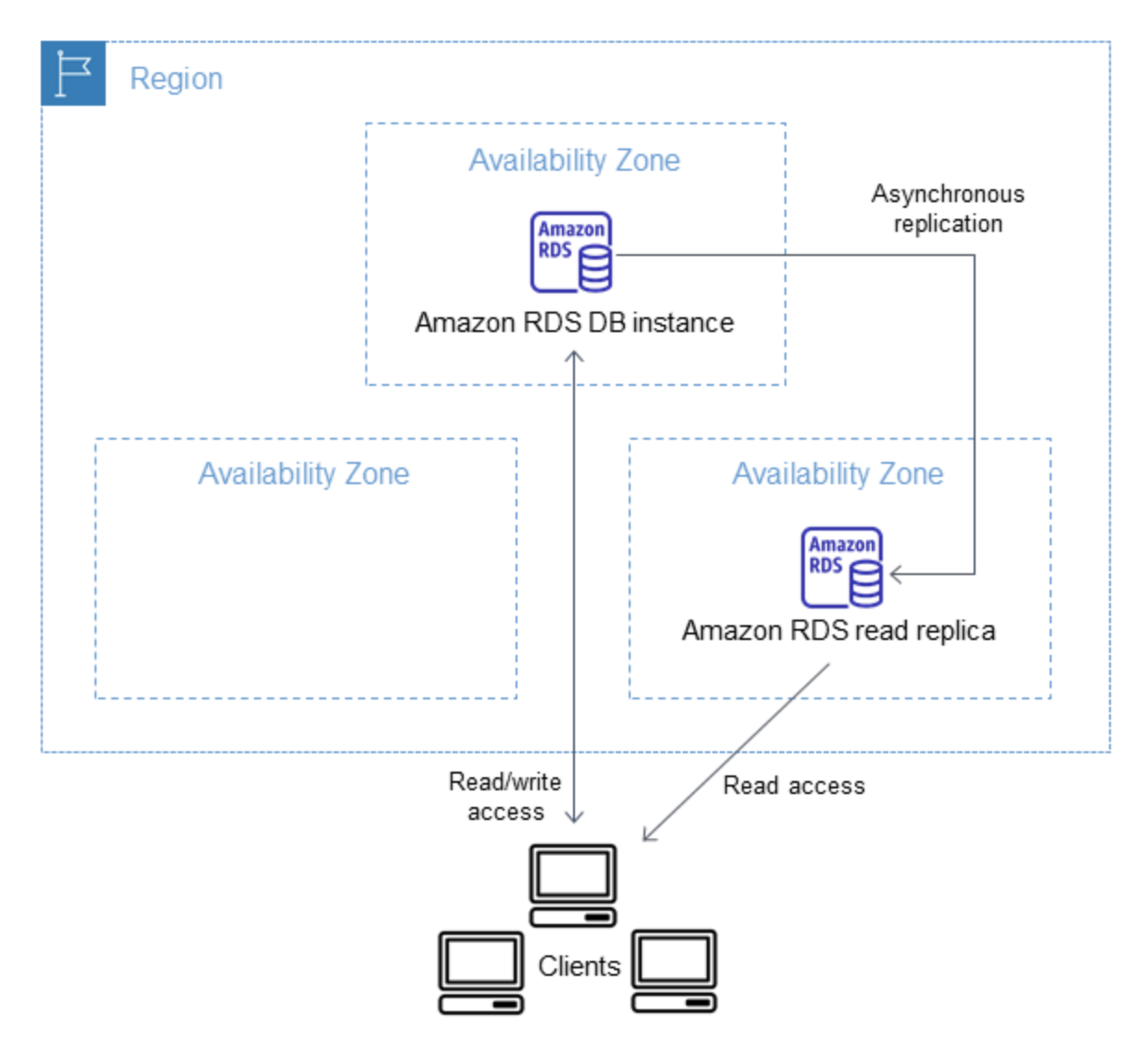
Read Replicas Creation
- Read Replicas can be created within the same AZ, different AZ within the same region, and cross-region as well.
- Up to 15 Read Replicas can be created from one source DB instance, including up to 5 cross-region read replicas.
- Creation process
- Automatic backups must be enabled on the source DB instance by setting the backup retention period to a value other than 0
- An existing DB instance needs to be specified as the source.
- RDS takes a snapshot of the source instance and creates a read-only instance from the snapshot.
- RDS then uses the asynchronous replication method for the DB engine to update the Read Replica for any changes to the source DB instance.
- RDS replicates all databases in the source DB instance.
- RDS sets up a secure communications channel between the source DB instance and the Read Replica if that Read Replica is in a different AWS region from the DB instance.
- RDS establishes any AWS security configurations, such as adding security group entries, needed to enable the secure channel.
- During the Read Replica creation, a brief I/O suspension on the source DB instance can be experienced as the DB snapshot occurs.
- I/O suspension typically lasts about one minute and can be avoided if the source DB instance is a Multi-AZ deployment (in the case of Multi-AZ deployments, DB snapshots are taken from the standby).
- Read Replica creation time can be slow if any long-running transactions are being executed and should wait for completion
- For multiple Read Replicas created in parallel from the same source DB instance, only one snapshot is taken at the start of the first create action.
- A Read Replica can be promoted to a new independent source DB, in which case the replication link is broken between the Read Replica and the source DB. However, the replication continues for other replicas using the original source DB as the replication source
Read Replica Deletion & DB Failover
- Read Replicas must be explicitly deleted, using the same mechanisms for deleting a DB instance.
- If the source DB instance is deleted without deleting the replicas, each replica is promoted to a stand-alone, single-AZ DB instance.
- If the source instance of a Multi-AZ deployment fails over to the standby, any associated Read Replicas are switched to use the secondary as their replication source.
Read Replica Storage & Compute Requirements
- A Read Replica, by default, is created with the same storage type as the source DB instance.
- Read Replicas can be created with a different storage type from the source DB instance (e.g., Provisioned IOPS, General Purpose, or Magnetic) depending on the source storage allocation.
- For replication to operate effectively, each Read Replica should have the same amount of compute & storage resources as the source DB instance.
- Read Replicas should be scaled accordingly if the source DB instance is scaled.
Read Replicas Promotion
- A read replica can be promoted into a standalone DB instance.
- When the read replica is promoted
- New DB instance is rebooted before it becomes available.
- New DB instance that is created retains the option group and the parameter group of the former read replica.
- The promotion process can take several minutes or longer to complete, depending on the size of the read replica.
- If a source DB instance has several read replicas, promoting one of the read replicas to a DB instance has no effect on the other replicas.
- If you plan to promote a read replica to a standalone instance, AWS recommends that you enable backups and complete at least one backup prior to promotion.
- Oracle Data Guard Switchover – For RDS for Oracle, AWS supports a managed switchover that reverses the replication direction (the replica becomes the primary and the old primary becomes the new replica) with zero data loss, without requiring promotion and re-creation.
- Read Replicas Promotion can help with
- Performing DDL operations (MySQL and MariaDB only)
- DDL Operations such as creating or rebuilding indexes can take time and can be performed on the read replica once it is in sync with its primary DB instance.
- Sharding
- Sharding embodies the “share-nothing” architecture and essentially involves breaking a large database into several smaller databases.
- Read Replicas can be created and promoted corresponding to each of the shards and then using a hashing algorithm to determine which host receives a given update.
- Implementing failure recovery
- Read replica promotion can be used as a data recovery scheme if the primary DB instance fails.
- Performing DDL operations (MySQL and MariaDB only)
Cascading Read Replicas
- Cascading read replicas allow you to create a read replica from another read replica, reducing the replication overhead on the source DB instance.
- Cascading read replicas are supported for MySQL, MariaDB, and PostgreSQL (version 14.1 and later).
- Cascading read replicas are not supported for Oracle, SQL Server, or Db2.
- With cascading replicas, the source DB instance sends data only to the first-level replica, which then replicates to its own downstream replicas.
- There cannot be more than three instances in a replication chain (source → replica → cascaded replica).
- Replica lag is typically higher for cascaded read replicas.
- Cascading read replicas help scale reads without adding overhead to the source DB instance.
Delayed Read Replicas (PostgreSQL)
- RDS for PostgreSQL supports delayed read replicas, allowing you to specify a minimum time period (up to 24 hours) that a replica lags behind the source database.
- This feature creates a time buffer that helps protect against data loss from human errors such as accidental table drops or unintended data modifications.
- Delayed replication is configured using the
recovery_min_apply_delayparameter (allowed range: 0 to 86,400,000 ms, i.e., 0 to 24 hours). - When data corruption occurs, you can promote the delayed replica to become the new primary, recovering within minutes rather than hours via traditional point-in-time restore.
- Available with RDS for PostgreSQL versions 14.19, 15.14, 16.10, and 17.6 and later.
- Delayed read replicas function as a real-time safety net for disaster recovery, complementing automated backups.
Read Replicas Multi-AZ
- RDS read replicas can be Multi-AZ and we can have read-only standby instances in a different AZ.
- Read Replicas with Multi-AZ configuration is supported for MySQL, MariaDB, PostgreSQL, Oracle, and SQL Server database engines.
- Read Replicas with Multi-AZ help build a resilient disaster recovery strategy and simplify the database engine upgrade process.
- Read replica as Multi-AZ allows you to use the read replica as a DR target providing automatic failover.
- Also, when you promote the read replica to be a standalone database, it will already be Multi-AZ enabled.
Multi-AZ DB Cluster (Two Readable Standbys)
- RDS Multi-AZ DB Cluster is a newer deployment option with a primary DB instance and two readable standby DB instances, each in a different AZ.
- The two standby instances use synchronous replication and can serve read traffic, unlike traditional Multi-AZ standbys.
- Multi-AZ DB Clusters provide faster failover (typically under 35 seconds), improved commit latency, and built-in read scaling.
- Supported for MySQL and PostgreSQL engines.
- You can also create read replicas from a Multi-AZ DB Cluster for additional read scaling (up to 15 read replicas for MySQL).
- Multi-AZ DB Clusters support up to 15 read replicas for MySQL and PostgreSQL.
Cross-Region Read Replicas
- Supported for MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server (Enterprise Edition).
- SQL Server cross-region read replicas were introduced in November 2022 and expanded to additional regions in January 2026.
- Cross-Region Read Replicas help to improve
- disaster recovery capabilities (reduces RTO and RPO),
- scale read operations into a region closer to end users,
- migration from a data center in one region to another region
- A source DB instance can have cross-region read replicas in multiple AWS Regions.
- Up to 5 cross-region read replicas can be created per source DB instance.
- Cross-Region RDS read replica can be created from a source RDS DB instance that is not a read replica of another RDS DB instance (except for cascading-capable engines).
- Replica lags are higher for Cross-region replicas. This lag time comes from the longer network channels between regional data centers.
- RDS can’t guarantee more than five cross-region read replica instances, due to the limit on the number of access control list (ACL) entries for a VPC.
- Read Replica uses the default DB parameter group and DB option group for the specified DB engine.
- Read Replica uses the default security group.
- Deleting the source for a cross-Region read replica will result in
- read replica promotion for MariaDB, MySQL, Oracle, and SQL Server DB instances
- no read replica promotion for PostgreSQL DB instances and the replication status of the read replica is set to
terminated.
Read Replica Features & Limitations
- RDS does not support circular replication.
- DB instance cannot be configured to serve as a replication source for an existing DB instance; a new Read Replica can be created only from an existing DB instance for e.g., if MyDBInstance replicates to ReadReplica1, ReadReplica1 can’t be configured to replicate back to MyDBInstance. From ReadReplica1, only a new Read Replica can be created, such as ReadRep2 (for MySQL, MariaDB, and PostgreSQL 14.1+).
- Cascading Read Replicas (read replica from another read replica) are supported for MySQL, MariaDB, and PostgreSQL (14.1+). They are NOT supported for Oracle, SQL Server, or Db2.
- For cascading replicas, there cannot be more than three instances in a replication chain, and replica lag is higher.
- RDS for Db2 and RDS for Oracle also support replicas in standby/mounted mode (not read-only), primarily for cross-Region disaster recovery.
- RDS does not support autoscaling of read replicas. Replicas must be created and deleted manually.
RDS Read Replicas Use Cases
- Scaling beyond the compute or I/O capacity of a single DB instance for read-heavy database workloads, directing excess read traffic to Read Replica(s)
- Serving read traffic while the source DB instance is unavailable for e.g. If the source DB instance cannot take I/O requests due to backups I/O suspension or scheduled maintenance, the read traffic can be directed to the Read Replica(s). However, the data might be stale.
- Business reporting or data warehousing scenarios where business reporting queries can be executed against a Read Replica, rather than the primary, production DB instance.
- Implementing disaster recovery by promoting the read replica to a standalone instance as a disaster recovery solution, if the primary DB instance fails.
- Reducing downtime during database upgrades — use a read replica to prepare the upgrade, then promote it (or use Blue/Green Deployments for near-zero downtime).
- Using delayed read replicas (PostgreSQL) as a safety net against accidental data corruption or deletion.
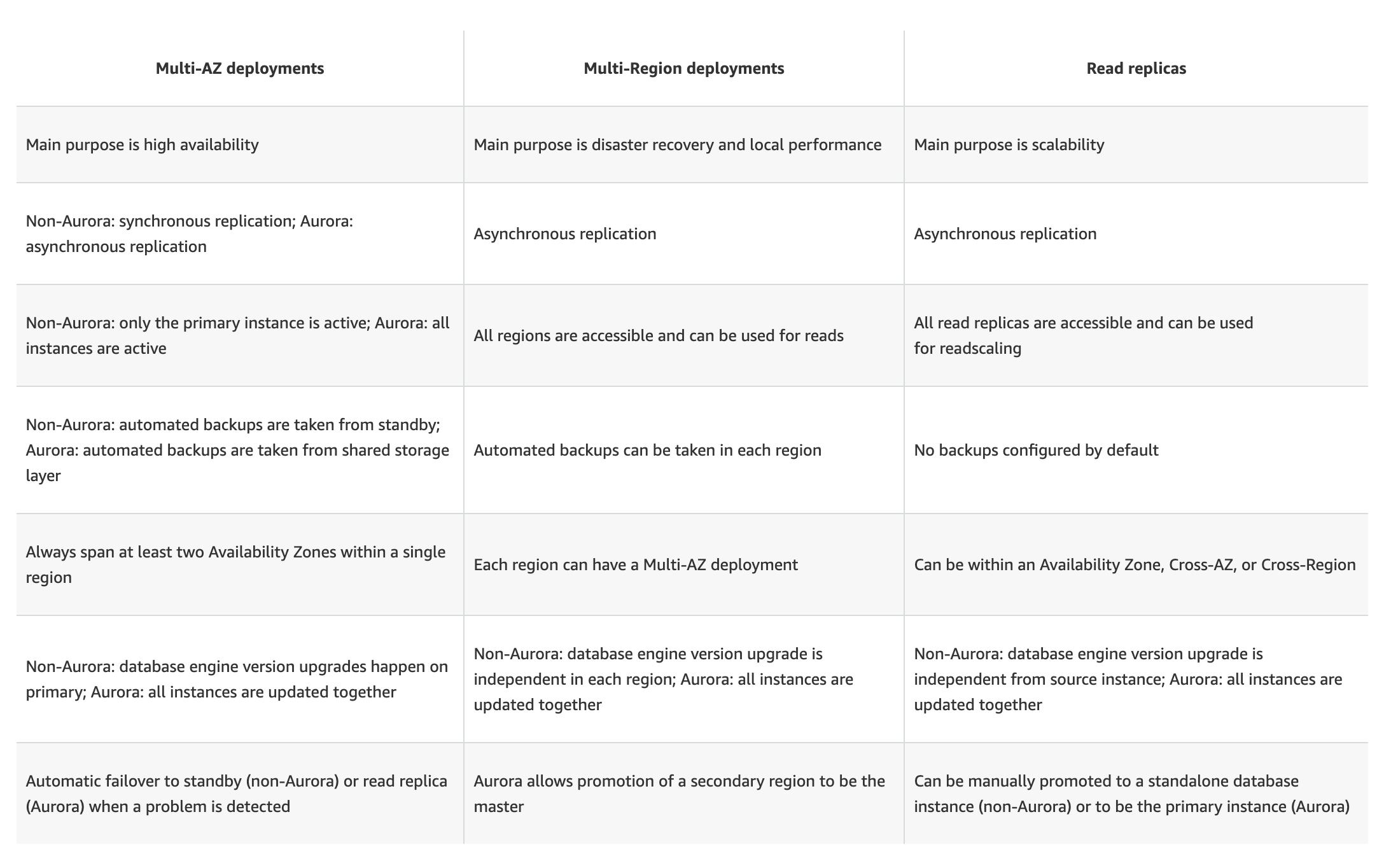
RDS Read Replicas vs Multi-AZ
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- You are running a successful multi-tier web application on AWS and your marketing department has asked you to add a reporting tier to the application. The reporting tier will aggregate and publish status reports every 30 minutes from user-generated information that is being stored in your web applications database. You are currently running a Multi-AZ RDS MySQL instance for the database tier. You also have implemented ElastiCache as a database caching layer between the application tier and database tier. Please select the answer that will allow you to successfully implement the reporting tier with as little impact as possible to your database.
- Continually send transaction logs from your master database to an S3 bucket and generate the reports off the S3 bucket using S3 byte range requests.
- Generate the reports by querying the synchronously replicated standby RDS MySQL instance maintained through Multi-AZ (Standby instance cannot be used as a scaling solution)
- Launch a RDS Read Replica connected to your Multi-AZ master database and generate reports by querying the Read Replica.
- Generate the reports by querying the ElastiCache database caching tier. (ElasticCache does not maintain full data and is simply a caching solution)
- Your company is getting ready to do a major public announcement of a social media site on AWS. The website is running on EC2 instances deployed across multiple Availability Zones with a Multi-AZ RDS MySQL Extra Large DB Instance. The site performs a high number of small reads and writes per second and relies on an eventual consistency model. After comprehensive tests you discover that there is read contention on RDS MySQL. Which are the best approaches to meet these requirements? (Choose 2 answers)
- Deploy ElastiCache in-memory cache running in each availability zone
- Implement sharding to distribute load to multiple RDS MySQL instances (this is only a read contention, the writes work fine)
- Increase the RDS MySQL Instance size and Implement provisioned IOPS (not scalable, this is only a read contention, the writes work fine)
- Add an RDS MySQL read replica in each availability zone
- Your company has HQ in Tokyo and branch offices all over the world and is using logistics software with a multi-regional deployment on AWS in Japan, Europe and US. The logistic software has a 3-tier architecture and currently uses MySQL 5.6 for data persistence. Each region has deployed its own database. In the HQ region you run an hourly batch process reading data from every region to compute cross-regional reports that are sent by email to all offices this batch process must be completed as fast as possible to quickly optimize logistics. How do you build the database architecture in order to meet the requirements?
- For each regional deployment, use RDS MySQL with a master in the region and a read replica in the HQ region
- For each regional deployment, use MySQL on EC2 with a master in the region and send hourly EBS snapshots to the HQ region
- For each regional deployment, use RDS MySQL with a master in the region and send hourly RDS snapshots to the HQ region
- For each regional deployment, use MySQL on EC2 with a master in the region and use S3 to copy data files hourly to the HQ region
- Use Direct Connect to connect all regional MySQL deployments to the HQ region and reduce network latency for the batch process
- Your business is building a new application that will store its entire customer database on a RDS MySQL database, and will have various applications and users that will query that data for different purposes. Large analytics jobs on the database are likely to cause other applications to not be able to get the query results they need to, before time out. Also, as your data grows, these analytics jobs will start to take more time, increasing the negative effect on the other applications. How do you solve the contention issues between these different workloads on the same data?
- Enable Multi-AZ mode on the RDS instance
- Use ElastiCache to offload the analytics job data
- Create RDS Read-Replicas for the analytics work
- Run the RDS instance on the largest size possible
- If I have multiple Read Replicas for my master DB Instance and I promote one of them, what happens to the rest of the Read Replicas?
- The remaining Read Replicas will still replicate from the older master DB Instance
- The remaining Read Replicas will be deleted
- The remaining Read Replicas will be combined to one read replica
- You need to scale an RDS deployment. You are operating at 10% writes and 90% reads, based on your logging. How best can you scale this in a simple way?
- Create a second master RDS instance and peer the RDS groups.
- Cache all the database responses on the read side with CloudFront.
- Create read replicas for RDS since the load is mostly reads.
- Create a Multi-AZ RDS installs and route read traffic to standby.
- A customer is running an application in US-West (Northern California) region and wants to setup disaster recovery failover to the Asian Pacific (Singapore) region. The customer is interested in achieving a low Recovery Point Objective (RPO) for an Amazon RDS multi-AZ MySQL database instance. Which approach is best suited to this need?
- Synchronous replication
- Asynchronous replication
- Route53 health checks
- Copying of RDS incremental snapshots
- A user is using a small MySQL RDS DB. The user is experiencing high latency due to the Multi AZ feature. Which of the below mentioned options may not help the user in this situation?
- Schedule the automated back up in non-working hours
- Use a large or higher size instance
- Use PIOPS
- Take a snapshot from standby Replica
- My Read Replica appears “stuck” after a Multi-AZ failover and is unable to obtain or apply updates from the source DB Instance. What do I do?
- You will need to delete the Read Replica and create a new one to replace it.
- You will need to disassociate the DB Engine and re associate it.
- The instance should be deployed to Single AZ and then moved to Multi- AZ once again
- You will need to delete the DB Instance and create a new one to replace it.
- A company is running a batch analysis every hour on their main transactional DB running on an RDS MySQL instance to populate their central Data Warehouse running on Redshift. During the execution of the batch their transactional applications are very slow. When the batch completes they need to update the top management dashboard with the new data. The dashboard is produced by another system running on-premises that is currently started when a manually-sent email notifies that an update is required The on-premises system cannot be modified because is managed by another team. How would you optimize this scenario to solve performance issues and automate the process as much as possible?
- Replace RDS with Redshift for the batch analysis and SNS to notify the on-premises system to update the dashboard
- Replace RDS with Redshift for the batch analysis and SQS to send a message to the on-premises system to update the dashboard
- Create an RDS Read Replica for the batch analysis and SNS to notify the on-premises system to update the dashboard
- Create an RDS Read Replica for the batch analysis and SQS to send a message to the on-premises system to update the dashboard.
- A company wants to protect its RDS PostgreSQL database against accidental table drops by a developer. Which solution provides the fastest recovery with minimal operational effort?
- Enable automated backups with a 7-day retention period and perform point-in-time recovery when needed.
- Create a delayed read replica with a recovery_min_apply_delay of 1 hour and promote it if data corruption occurs.
- Take manual snapshots every hour and restore from the most recent snapshot.
- Use AWS Backup with hourly backup rules and restore from the latest recovery point.
- An organization needs to scale their RDS MySQL database to handle increased read traffic. They currently have 5 read replicas but need more read capacity. What should they do?
- Create additional MySQL instances and use application-level sharding.
- Create additional read replicas, as RDS supports up to 15 read replicas per source instance.
- Migrate to Aurora which supports unlimited read replicas.
- Create a second primary instance and distribute reads between both primaries.
- A company is planning a disaster recovery strategy for their RDS for Oracle database. They need the ability to switch between primary and replica databases with zero data loss and without breaking the replication link. Which approach should they use?
- Promote the read replica to a standalone instance.
- Use RDS Blue/Green Deployments.
- Use the managed Oracle Data Guard switchover feature.
- Create a new instance from the latest automated backup.
- A company wants to reduce replication overhead on their source RDS MySQL instance while maintaining multiple read replicas for different workloads. Which feature should they use?
- Multi-AZ DB Cluster with readable standbys
- Cascading read replicas where downstream replicas replicate from a first-level replica
- Cross-region read replicas to distribute replication load
- RDS Proxy to distribute read traffic across existing replicas
- A company requires both fast failover (under 35 seconds) and read scaling for their RDS PostgreSQL database. They currently use a Multi-AZ instance with a separate read replica. Which deployment option best consolidates these requirements?
- Keep the Multi-AZ instance and add more read replicas.
- Migrate to a Multi-AZ DB Cluster with two readable standbys.
- Migrate to Aurora with Aurora Replicas.
- Create a cross-region read replica for disaster recovery.