Google Cloud Dataproc
- Cloud Dataproc is a managed Spark and Hadoop service that lets you take advantage of open-source data tools for batch processing, querying, streaming, and machine learning.
- Dataproc automation helps to create clusters quickly, manage them easily, and save money by turning clusters on and off as needed.
- Dataproc helps reduce time on time and money spent on administration and lets you focus on your jobs and your data.
- Dataproc clusters are quick to start, scale, and shutdown, with each of these operations taking 90 seconds or less, on average
- Dataproc has built-in integration with other GCP services, such as BigQuery, Cloud Storage, Bigtable, Cloud Logging, and Monitoring
- Dataproc clusters support preemptible instances that have lower compute prices to reduce costs further.
- Dataproc supports connectors for BigQuery, Bigtable, Cloud Storage
- Dataproc also supports Anaconda, HBase, Flink, Hive WebHcat, Druid, Jupyter, Presto, Solr, Zepplin, Ranger, Zookeeper, and much more.
Dataproc Cluster High Availability
- Dataproc cluster can be configured for High Availability by specifying the number of master instances in the cluster
- Dataproc supports two master configurations:
- Single Node Cluster – 1 master – 0 Workers (default, non HA)
- provides one node for both master and worker
- if the master fails, the in-flight jobs will necessarily fail and need to be retried, and HDFS will be inaccessible until the single NameNode fully recovers on reboot.
- High Availability Cluster – 3 masters – N Workers (Hadoop HA)
- HDFS High Availability and YARN High Availability are configured to allow uninterrupted YARN and HDFS operations despite any single-node failures/reboots.
- All nodes in a High Availability cluster reside in the same zone. If there is a failure that impacts all nodes in a zone, the failure will not be mitigated.
Dataproc Cluster Scaling
- Dataproc cluster can be adjusted to scale by increasing or decreasing the number of primary or secondary worker nodes (horizontal scaling)
- Dataproc cluster can be scaled at any time, even when jobs are running on the cluster.
- Machine type of an existing cluster (vertical scaling) cannot be changed. To vertically scale, create a cluster using a supported machine type, then migrate jobs to the new cluster.
- Dataproc cluster can help scale
- to increase the number of workers to make a job run faster
- to decrease the number of workers to save money
- to increase the number of nodes to expand available Hadoop Distributed Filesystem (HDFS) storage
Dataproc Cluster Autoscaling
- Dataproc Autoscaling provides a mechanism for automating cluster resource management and enables cluster autoscaling.
- An
Autoscaling Policy is a reusable configuration that describes how clusters using the autoscaling policy should scale.
- It defines scaling boundaries, frequency, and aggressiveness to provide fine-grained control over cluster resources throughout cluster lifetime.
- Autoscaling is recommended for
- on clusters that store data in external services, such as Cloud Storage
- on clusters that process many jobs
- to scale up single-job clusters
- Autoscaling is not recommended with/for:
- HDFS: Autoscaling is not intended for scaling on-cluster HDFS
- YARN Node Labels: Autoscaling does not support YARN Node Labels. YARN incorrectly reports cluster metrics when node labels are used.
- Spark Structured Streaming: Autoscaling does not support Spark Structured Streaming
- Idle Clusters: Autoscaling is not recommended for the purpose of scaling a cluster down to minimum size when the cluster is idle. It is better to delete an Idle cluster.
Dataproc Workers
- Primary workers are standard Compute Engine VMs
- Secondary workers can be used to scale with the below limitations
- Processing only
- Secondary workers do not store data.
- can only function as processing nodes
- useful to scale compute without scaling storage.
- No secondary-worker-only clusters
- Cluster must have primary workers
- Dataproc adds two primary workers to the cluster, by default, if no primary workers are specified.
- Machine type
- use the machine type of the cluster’s primary workers.
- Persistent disk size
- are created, by default, with the smaller of 100GB or the primary worker boot disk size.
- This disk space is used for local caching of data and is not available through HDFS.
- Asynchronous Creation
- Dataproc manages secondary workers using Managed Instance Groups (MIGs), which create VMs asynchronously as soon as they can be provisioned
Dataproc Initialization Actions
- Dataproc supports initialization actions in executables or scripts that will run on all nodes in the cluster immediately after the cluster is set up
- Initialization actions often set up job dependencies, such as installing Python packages, so that jobs can be submitted to the cluster without having to install dependencies when the jobs are run.
Dataproc Cloud Storage Connector
- Dataproc Cloud Storage connector helps Dataproc use Google Cloud Storage as the persistent store instead of HDFS.
- Cloud Storage connector helps separate the storage from the cluster lifecycle and allows the cluster to be shut down when not processing data
- Cloud Storage connector benefits
- Direct data access – Store the data in Cloud Storage and access it directly. You do not need to transfer it into HDFS first.
- HDFS compatibility – can easily access your data in Cloud Storage using the
gs:// prefix instead of hdfs://
- Interoperability – Storing data in Cloud Storage enables seamless interoperability between Spark, Hadoop, and Google services.
- Data accessibility – data is accessible even after shutting down the cluster, unlike HDFS.
- High data availability – Data stored in Cloud Storage is highly available and globally replicated without a loss of performance.
- No storage management overhead – Unlike HDFS, Cloud Storage requires no routine maintenance, such as checking the file system, or upgrading or rolling back to a previous version of the file system.
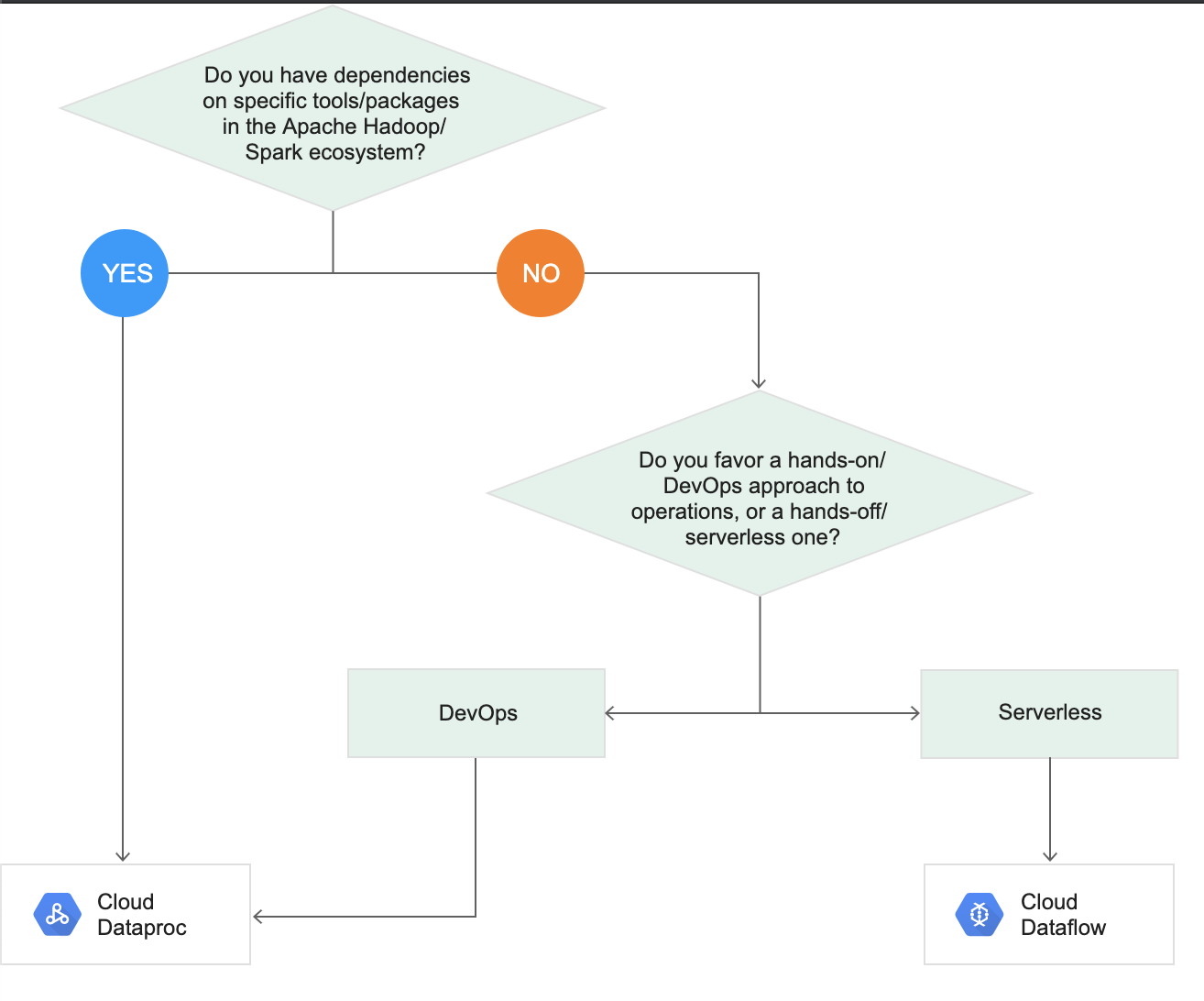
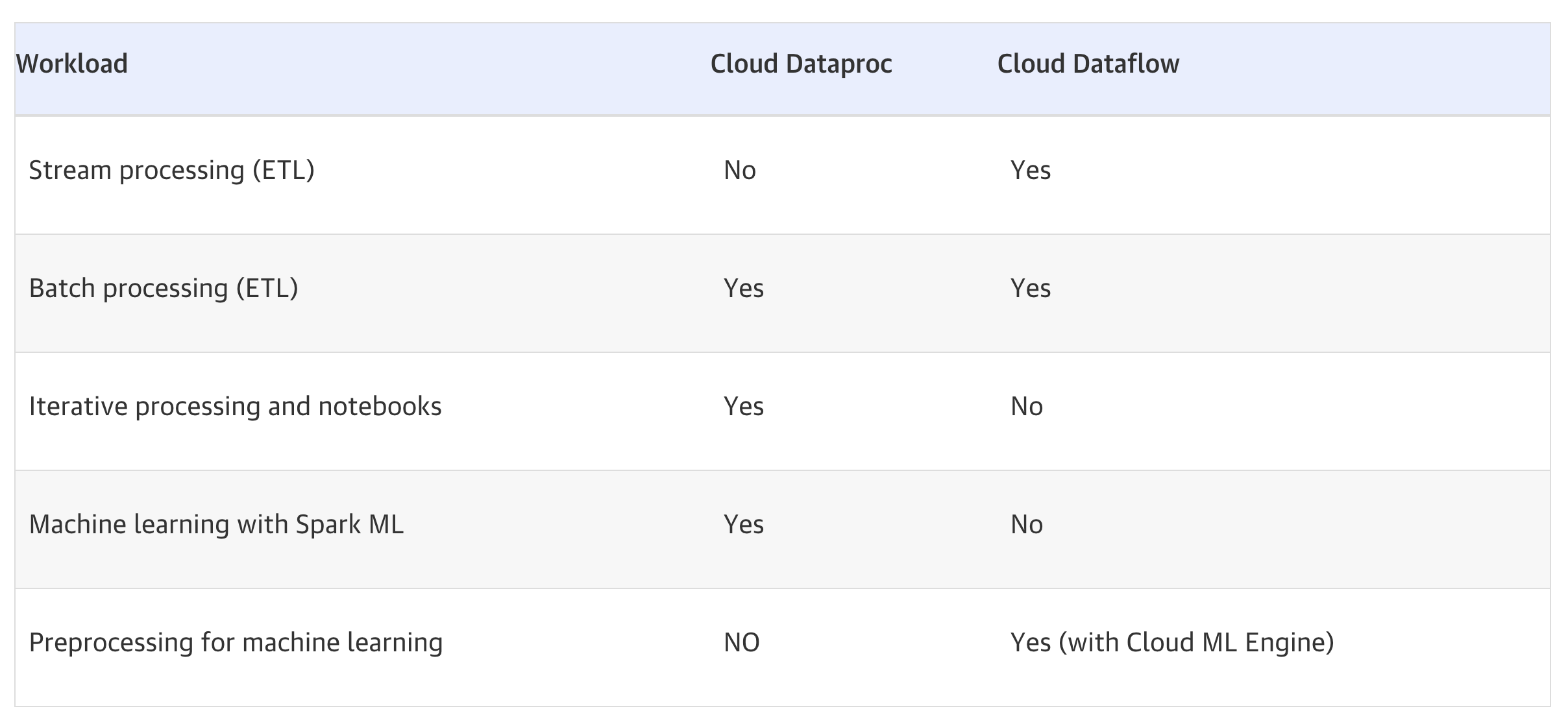
Cloud Dataproc vs Dataflow
Refer blog post @ Cloud Dataproc vs Dataflow
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your company is forecasting a sharp increase in the number and size of Apache Spark and Hadoop jobs being run on your local data center. You want to utilize the cloud to help you scale this upcoming demand with the least amount of operations work and code change. Which product should you use?
- Google Cloud Dataflow
- Google Cloud Dataproc
- Google Compute Engine
- Google Container Engine
- Your company is migrating to the Google cloud and looking for HBase alternative. Current solution uses a lot of custom code using the observer coprocessor. You are required to find the best alternative for migration while using managed services, is possible?
- Dataflow
- HBase on Dataproc
- Bigtable
- BigQuery
References
Google_Cloud_Dataproc