Google Cloud Dataflow
- Google Cloud Dataflow is a managed, serverless service for unified stream and batch data processing requirements
- Dataflow provides Horizontal autoscaling to automatically choose the appropriate number of worker instances required to run the job.
- Dataflow is based on Apache Beam, an open-source, unified model for defining both batch and streaming-data parallel-processing pipelines.
Dataflow (Apache Beam) Programming Model
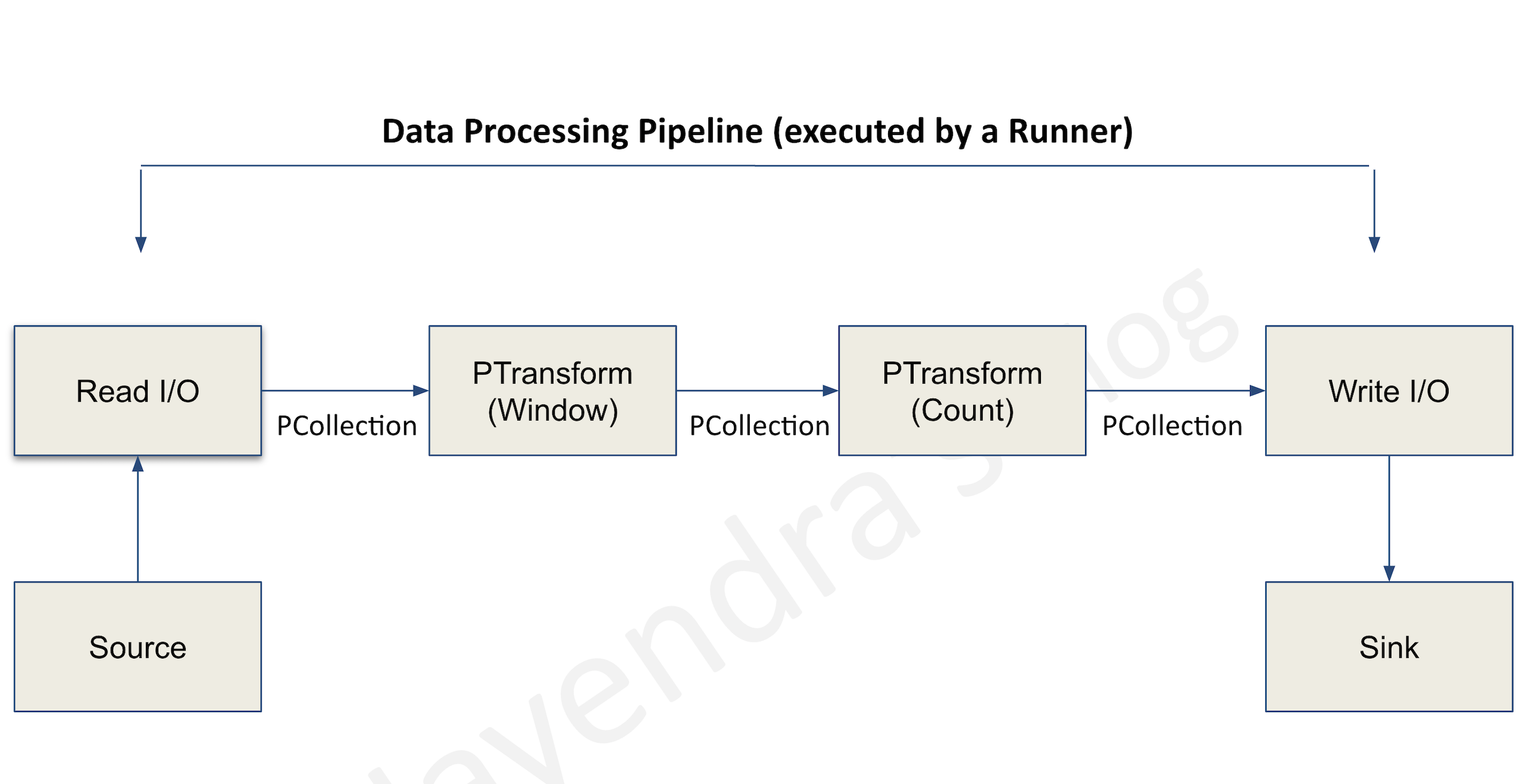
Pipelines
- A pipeline encapsulates the entire series of computations involved in reading input data, transforming that data, and writing output data.
- The input source and output sink can be the same or of different types, allowing data conversion from one format to another.
- Apache Beam programs start by constructing a Pipeline object and then using that object as the basis for creating the pipeline’s datasets.
- Each pipeline represents a single, repeatable job.
PCollection
- A PCollection represents a potentially distributed, multi-element dataset that acts as the pipeline’s data.
- Apache Beam transforms use PCollection objects as inputs and outputs for each step in your pipeline.
Transforms
- A transform represents a processing operation that transforms data.
- A transform takes one or more PCollections as input, performs a specified operation on each element in that collection, and produces one or more PCollections as output.
- A transform can perform nearly any kind of processing operation like
- performing mathematical computations,
- data conversion from one format to another,
- grouping data together,
- reading and writing data,
- filtering data to output only the required elements, or
- combining data elements into single values.
ParDo
- ParDo is the core parallel processing operation invoking a user-specified function on each of the elements of the input PCollection.
- ParDo collects the zero or more output elements into an output PCollection.
- ParDo processes elements independently and in parallel, if possible.
Pipeline I/O
- Apache Beam I/O connectors help read data into the pipeline and write output data from the pipeline.
- An I/O connector consists of a source and a sink.
- All Apache Beam sources and sinks are transforms that let the pipeline work with data from several different data storage formats.
Aggregation
- Aggregation is the process of computing some value from multiple input elements.
- The primary computational pattern for aggregation is to
- group all elements with a common key and window.
- combine each group of elements using an associative and commutative operation.
User-defined functions (UDFs)
- User-defined functions allow executing user-defined code as a way of configuring the transform.
- For ParDo, user-defined code specifies the operation to apply to every element, and for Combine, it specifies how values should be combined.
- A pipeline might contain UDFs written in a different language than the language of the runner.
- A pipeline might also contain UDFs written in multiple languages.
Runner
- Runners are the software that accepts a pipeline and executes it.
Event time
- Time a data event occurs, determined by the timestamp on the data element itself.
- This contrasts with the time the actual data element gets processed at any stage in the pipeline.
Windowing
- Windowing enables grouping operations over unbounded collections by dividing the collection into windows of finite collections according to the timestamps of the individual elements.
- A windowing function tells the runner how to assign elements to an initial window, and how to merge windows of grouped elements.
Tumbling Windows (Fixed Windows)
- A tumbling window represents a consistent, disjoint time interval, for e.g. every 1 min, in the data stream.
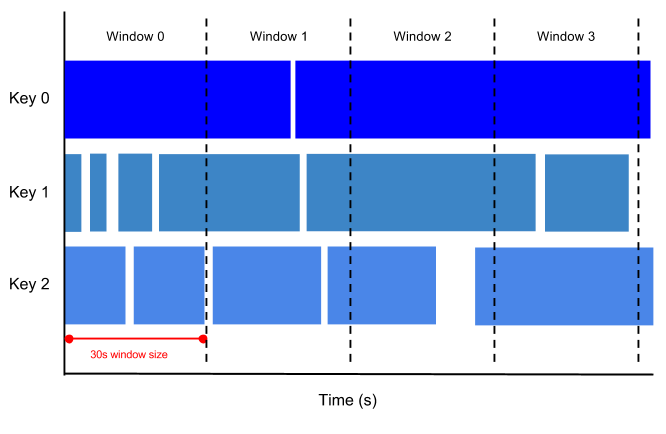
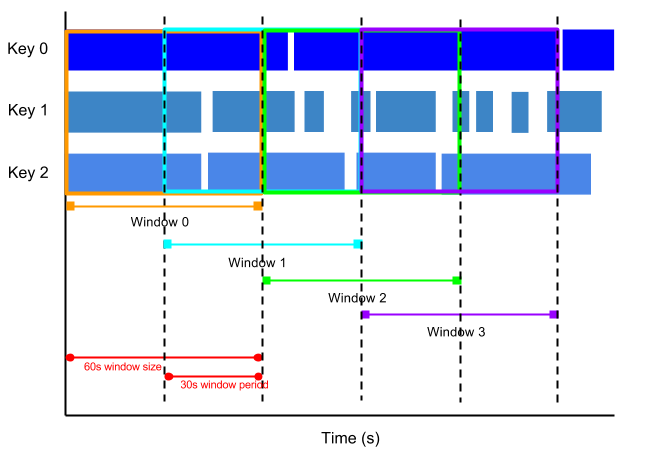
Hopping Windows (Sliding Windows)
- A hopping window represents a consistent time interval in the data stream for e.g., a hopping window can start every 30 seconds and capture 1 min of data and the window. The frequency with which hopping windows begin is called the period.
- Hopping windows can overlap, whereas tumbling windows are disjoint.
- Hopping windows are ideal to take running averages of data
Session windows
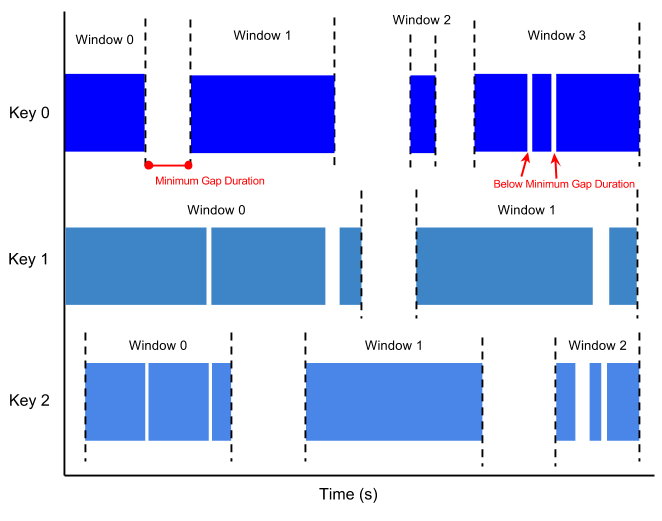
- A session window contains elements within a gap duration of another element for e.g., session windows can divide a data stream representing user mouse activity. This data stream might have long periods of idle time interspersed with many clicks. A session window can contain the data generated by the clicks.
- The gap duration is an interval between new data in a data stream.
- If data arrives after the gap duration, the data is assigned to a new window
- Session windowing assigns different windows to each data key.
- Tumbling and hopping windows contain all elements in the specified time interval, regardless of data keys.
Watermarks
- A Watermark is a threshold that indicates when Dataflow expects all of the data in a window to have arrived.
- Watermark is tracked and its a system’s notion of when all data in a certain window can be expected to have arrived in the pipeline
- If new data arrives with a timestamp that’s in the window but older than the watermark, the data is considered late data.
- Dataflow tracks watermarks because of the following:
- Data is not guaranteed to arrive in time order or at predictable intervals.
- Data events are not guaranteed to appear in pipelines in the same order that they were generated.
Trigger
- Triggers determine when to emit aggregated results as data arrives.
- For bounded data, results are emitted after all of the input has been processed.
- For unbounded data, results are emitted when the watermark passes the end of the window, indicating that the system believes all input data for that window has been processed.
Dataflow Pipeline Operations
- Cancelling a job
- causes the Dataflow service to stop the job immediately.
- might lose in-flight data
- Draining a job
- supports graceful stop
- prevents data loss
- is useful to deploy incompatible changes
- allows the job to clear the existing queue before stoping
- supports only streaming jobs and does not support batch pipelines
Dataflow Security
- Dataflow provides data-in-transit encryption.
- All communication with Google Cloud sources and sinks is encrypted and is carried over HTTPS.
- All inter-worker communication occurs over a private network and is subject to the project’s permissions and firewall rules.
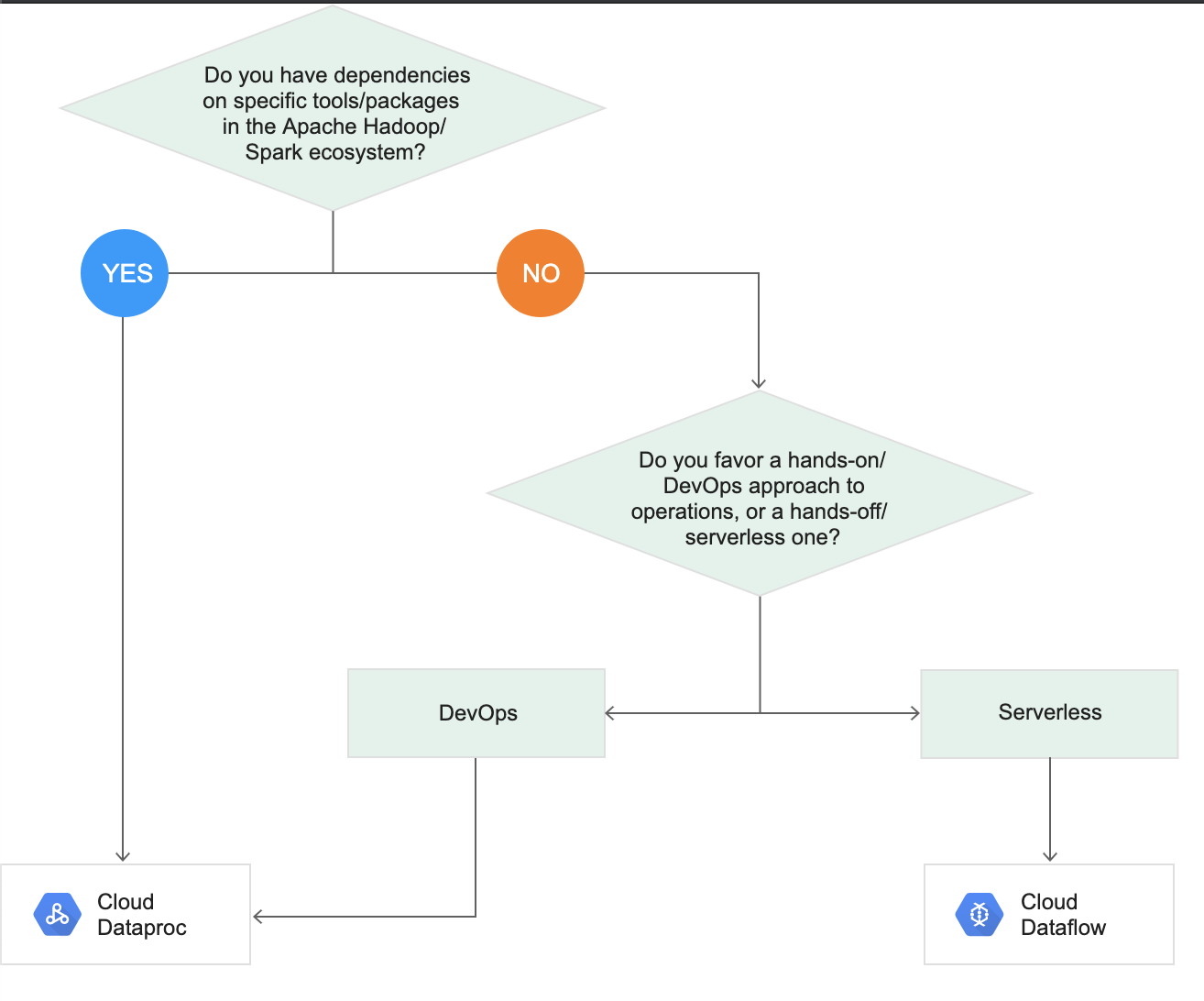
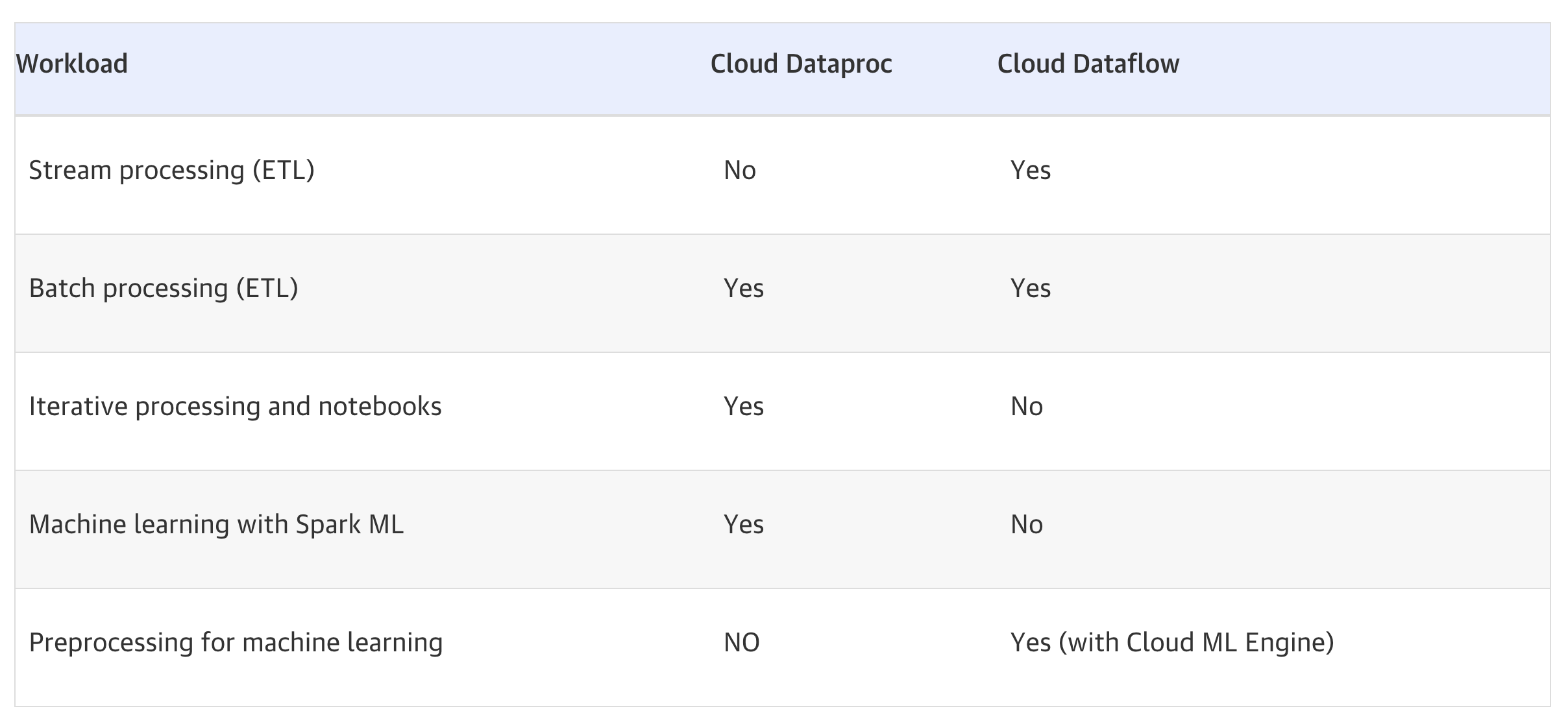
Cloud Dataflow vs Dataproc
Refer blog post @ Cloud Dataflow vs Dataproc
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A startup plans to use a data processing platform, which supports both batch and streaming applications. They would prefer to have a hands-off/serverless data processing platform to start with. Which GCP service is suited for them?
- Dataproc
- Dataprep
- Dataflow
- BigQuery
References
Google_Cloud_Dataflow