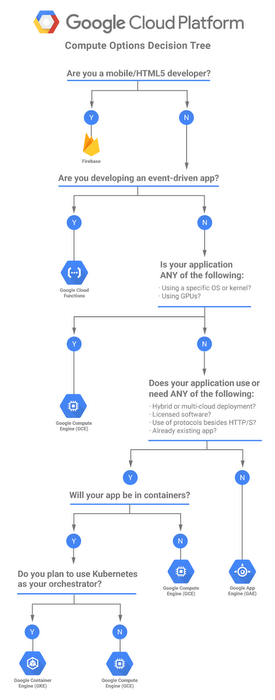
Google Cloud Compute Engine
- Compute Engine instance is a virtual machine (VM) hosted on Google’s infrastructure.
- Compute Engine instances can run the public images for Linux and Windows Server that Google provides as well as private custom images created or imported from existing systems.
- Docker containers can also be deployed, which are automatically launched on instances running the Container-Optimized OS public image.
- Each instance belongs to a GCP project, and a project can have one or more instances. When you delete an instance, it is removed from the project.
- For instance creation, the zone, operating system, and machine type (number of virtual CPUs and the amount of memory) need to be specified.
- By default, each Compute Engine instance has a small boot persistent disk that contains the OS. Additional storage options can be attached.
- Each network interface of a Compute Engine instance is associated with a subnet of a unique VPC network.
- Regardless of the region where the VM instance is created, the default time for the VM instance is Coordinated Universal Time (UTC).
Compute Engine Instance Lifecycle

PROVISIONING. Resources are being allocated for the instance. The instance is not running yet.STAGING. Resources have been acquired and the instance is being prepared for the first boot.RUNNING. The instance is booting up or running. You should be able to ssh into the instance soon, but not immediately after it enters this state.REPAIRING – The instance is being repaired because the instance encountered an internal error or the underlying machine is unavailable due to maintenance. During this time, the instance is unusable. If repair is successful, the instance returns to one of the above states.STOPPING: The instance is being stopped because a user has made a request to stop the instance or there was a failure. This is a temporary status and the instance will move to TERMINATED.TERMINATED. A user shut down the instance, or the instance encountered a failure. You can choose to restart the instance or delete it.SUSPENDING The instance is being suspended due to a user actionSUSPENDED – Instance is suspended and can be resumed or deleted
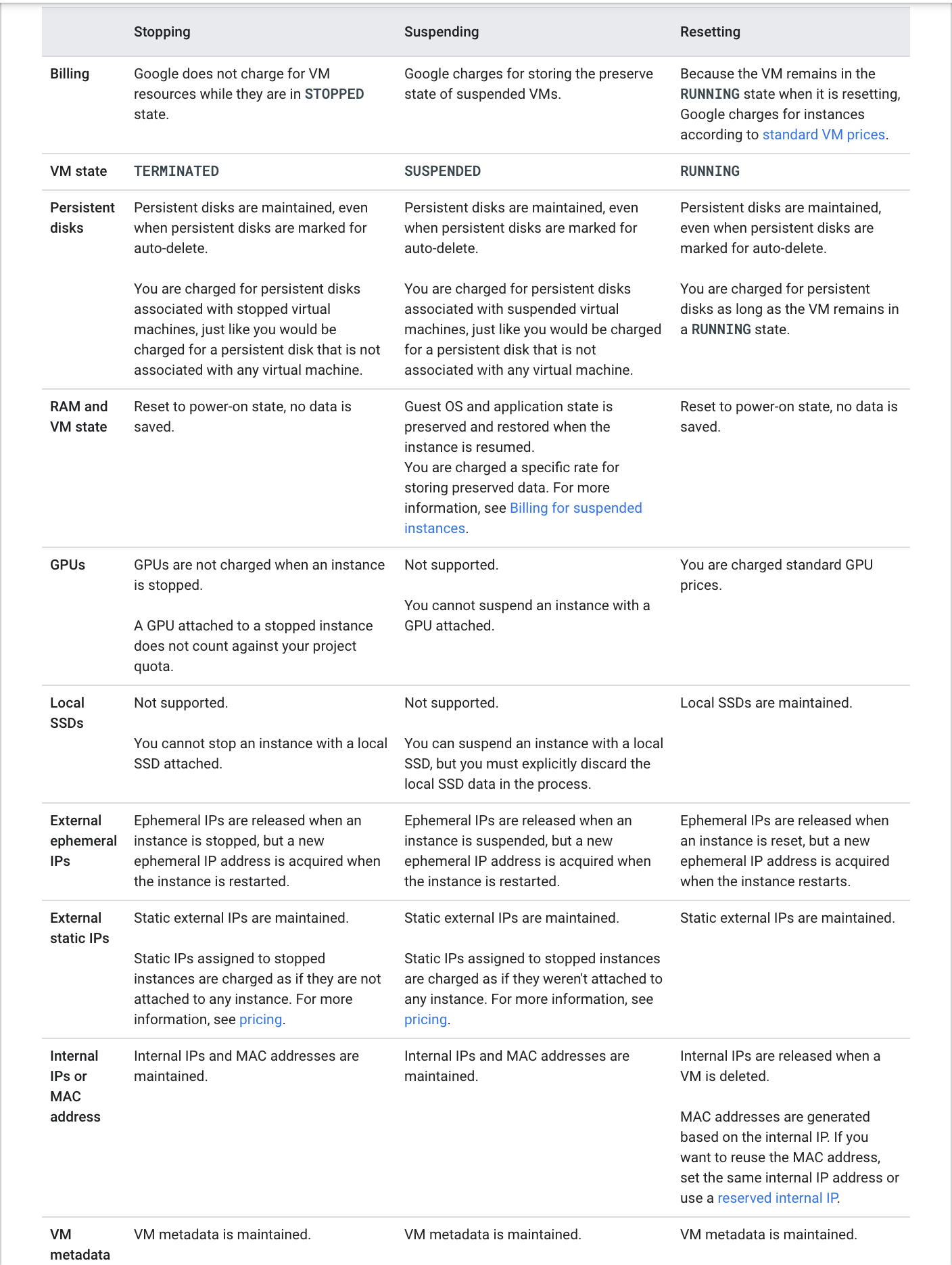
Compute Engine Machine Types
- A machine type is a set of virtualized hardware resources available to a virtual machine (VM) instance, including the system memory size, virtual CPU (vCPU) count, and persistent disk limits.
- Machine types are grouped and curated by families for different workloads
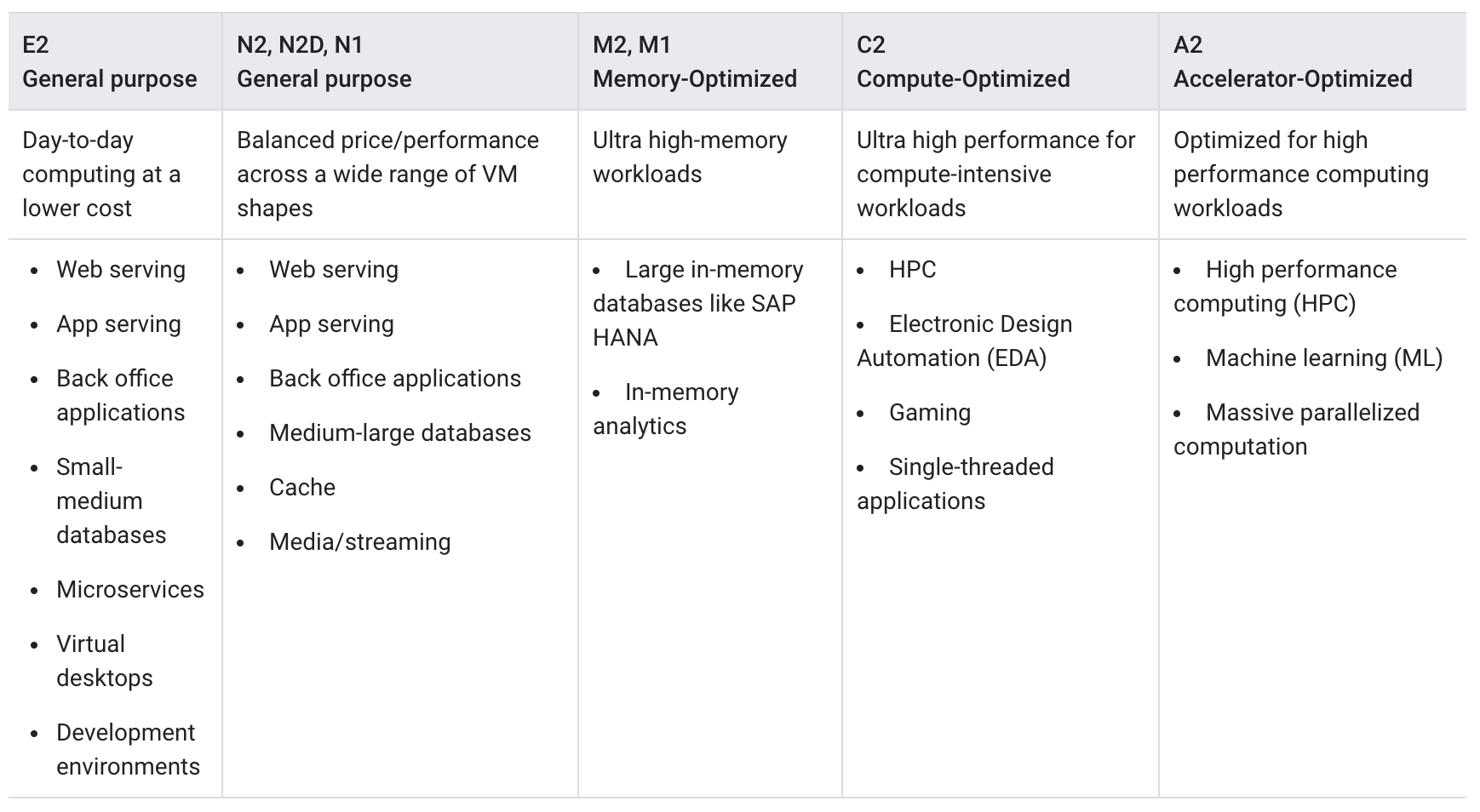
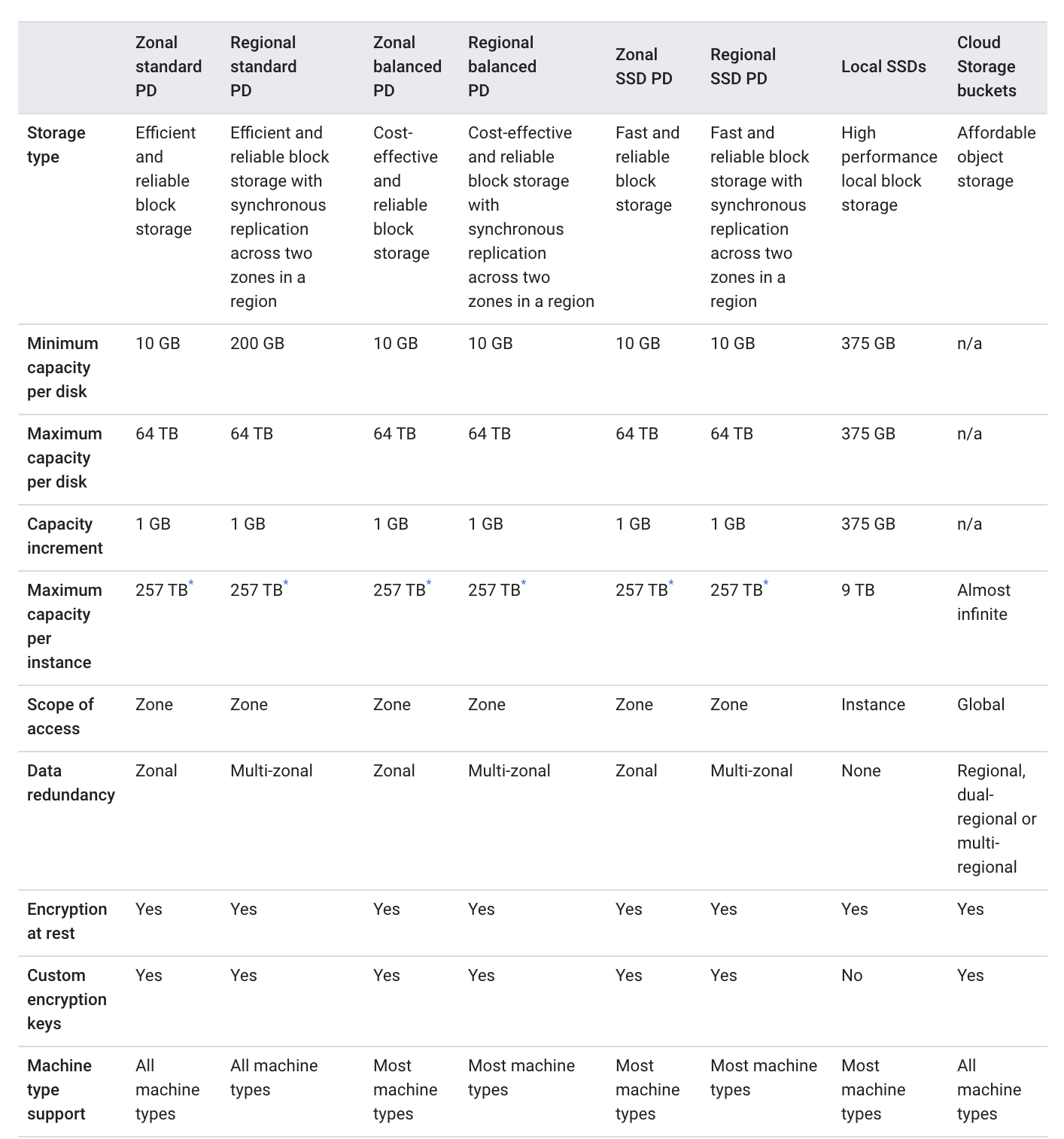
Compute Engine Storage
Refer blog post @ Compute Engine Storage Options
Compute Engine Guest Environment
- A Guest environment is automatically installed on the VM instance when using Google-provided public images
- Guest environment is a set of scripts, daemons, and binaries that read the content of the metadata server to make a VM run properly on CE
- A metadata server is a communication channel for transferring information from a client to the guest operating system.
- Guest environment can be manually installed on custom images
Compute Engine Instance Availability Policies
- Compute Engine does regular maintenance of its infrastructure which entails hardware and software updates
- Google might require to move the VM away from the host undergoing maintenance and Compute Engine automatically manages the scheduling behavior of these instances.
- Compute Engine instance’s availability policy determines how it behaves when there is a maintenance event
- Live migrate – move the VM instances to another host machine
- Stop the instances
- Instance’s availability policy can be changed by configuring the following two settings:
- VM instance’s maintenance behavior
onHostMaintenance, which determines whether the instance is live migrated MIGRATE (default) or stopped TERMINATE
- Instance’s restart behavior
automaticRestart which determines whether the instance automatically restarts (default) if it crashes or gets stopped
Compute Engine Live Migration
- Live migration helps keep the VM instances running even when a host system event, such as a software or hardware update, occurs
- Compute Engine live migrates the running instances to another host in the same zone instead of requiring the VMs to be rebooted
- Live migration allows Google to perform maintenance to keep infrastructure protected and reliable without interrupting any of the VMs.
- GCP provides a notification to the guest that migration is imminent, when a VM is scheduled to be live migrated
- Regular infrastructure maintenance and upgrades.
- Network and power grid maintenance in the data centers.
- Failed hardware such as memory, CPU, network interface cards, disks, power, and so on. This is done on a best-effort basis; if hardware fails completely or otherwise prevents live migration, the VM crashes and restarts automatically and a
hostError is logged.
- Host OS and BIOS upgrades.
- Security-related updates, with the need to respond quickly.
- System configuration changes, including changing the size of the host root partition, for storage of the host image and packages. Live migration keeps the instances running during:
- Live migration does not change any attributes or properties of the VM including internal and external IP addresses, instance metadata, block storage data and volumes, OS and application state, network settings, network connections, and so on.
- Compute Engine can also live migrate instances with local SSDs attached, moving the VMs along with their local SSD to a new machine in advance of any planned maintenance.
- Instances with GPUs attached cannot be live migrated and must be set to stop and optionally restart. Compute Engine offers a 60-minute notice before a VM instance with a GPU attached is stopped
- Preemptible instance cannot be configured for live migration
Preemptible VM instances
- A preemptible VM is an instance that can be created and run at a much lower price than normal instances.
- Compute Engine might stop (preempt) these instances if it requires access to those resources for other tasks.
- Preemptible VMs are excess Compute Engine capacity, so their availability varies with usage.
- Preemptible VM are ideal to reduce costs significantly, if the apps are fault-tolerant and can withstand possible instance preemptions or interruptions
- Preemptible instance limitations
- might stop preemptible instances at any time due to system events.
- always stops preemptible instances after they run for 24 hours.
- are finite GCE resources, so they might not always be available.
- can’t live migrate to a regular VM instance, or be set to automatically restart when there is a maintenance event.
- are not covered by any Service Level Agreement
- GCP Free Tier credits for Compute Engine don’t apply to preemptible instances
- Preemption process
- Compute Engine sends a preemption notice to the instance in the form of an ACPI G2 Soft Off signal.
- Shutdown script can be used to handle the preemption notice and complete cleanup actions before the instance stops
- If the instance does not stop after 30 seconds, Compute Engine sends an ACPI G3 Mechanical Off signal to the operating system.
- Compute Engine transitions the instance to a
TERMINATED state.
- Managed Instance group supports Preemptible instances.
Shielded VM
- Shielded VM offers verifiable integrity of the Compute Engine VM instances, to confirm the instances haven’t been compromised by boot- or kernel-level malware or rootkits.
- Shielded VM’s verifiable integrity is achieved through the use of Secure Boot, virtual trusted platform module (vTPM)-enabled Measured Boot, and integrity monitoring.
Managing access to the instances
- Linux instances:
- Compute Engine uses key-based SSH authentication to establish connections to Linux virtual machine (VM) instances.
- By default, local users with passwords aren’t configured on Linux VMs.
- By default, Compute Engine uses custom project and/or instance metadata to configure SSH keys and to manage SSH access. If OS Login is used, metadata SSH keys are disabled.
- Managing Instance Access Using OS Login,
- allows associating SSH keys with the Google Account or Google Workspace account and manage admin or non-admin access to the instance through IAM roles.
- connecting to the instances using the
gcloud command-line tool or SSH from the console, Compute Engine can automatically generate SSH keys and apply them to the Google Account or Google Workspace account.
- Manage the SSH keys in the project or instance metadata
- allows granting admin access to instances with metadata access that does not use OS Login.
- connecting to the instances using the
gcloud command-line tool or SSH from the console, Compute Engine can automatically generate SSH keys and apply them to project metadata.
- Project-wide public SSH keys
- give users general access to a Linux instance.
- give users access to all of the Linux instances in a project that allows project-wide public SSH keys
- Instance metadata
- If an instance blocks project-wide public SSH keys, a user can’t use the project-wide public SSH key to connect to the instance unless the same public SSH key is also added to instance metadata
- On Windows Server instances:
- Create a password for a Windows Server instance
Compute Engine Images
- Compute Engine Images help provide operation system images to create boot disks and application images with preinstalled, configured software
- Main purpose is to create new instances or configure instance templates
- Images can be regional or multi-regional and can be shared and accessed across projects and organizations
- Compute Engine instances can run the public images for Linux and Windows Server that Google provides as well as private custom images created or imported from existing systems.
- Public images
- provided and maintained by Google, open-source communities, and third-party vendors.
- All Google Cloud projects have access to these images and can use them to create instances.
- Custom images
- are available only to the Cloud project.
- Custom images can be created from boot disks and other images.
- Image families
- help image versioning
- helps to manage images in the project by grouping related images together, so that they can roll forward and roll back between specific image versions
- always points to newest latest non-deprecated version
- Linux images can be exported as a tar.gz file to Cloud Storage
- Google Cloud supports images with Container-Optimized OS, an OS image for the CE instances optimized for running Docker containers
Instance Templates
- Instance template is a resource used to create VM instances and managed instance groups (MIGs) with identical configuration
- Instance templates define the machine type, boot disk image or container image, labels, and other instance properties
- Instance templates are a convenient way to save a VM instance’s configuration to create VMs or groups of VMs later
- Instance template is a global resource that is not bound to a zone or a region. However, if some zonal resources are specified in an instance template for e.g. disks, which restricts the template to the zone where that resource resides.
- Labels defined within an instance template are applied to all instances that are created from that instance template. The labels do not apply to the instance template itself.
- Existing instance template cannot be updated or changed after its created
Instance Groups
Refer blog post @ Compute Engine Instance Groups
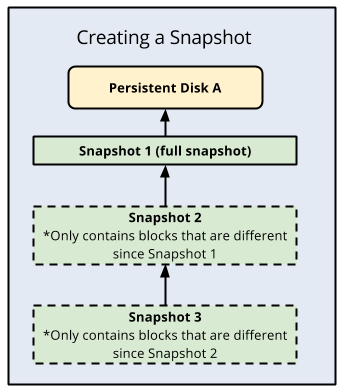
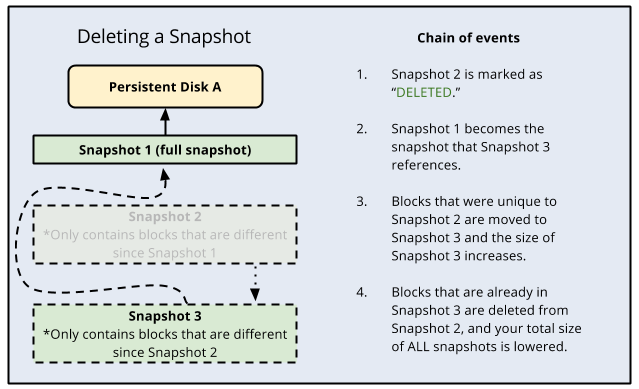
Snapshots
Refer blog post @ Compute Engine Snapshots
Startup & Shutdown Scripts
- Startup scripts
- can be added and executed on the VM instances to perform automated tasks every time the instance boots up.
- can perform actions such as installing software, turning on services, performing updates, and any other tasks defined in the script.
- Shutdown scripts
- execute commands right before a VM instance is stopped or restarted.
- can be useful allowing instances time to clean up or perform tasks, such as exporting logs, or syncing with other systems.
- are executed only on a best-effort basis
- have a limited amount of time to finish running before the instance stops i.e. 90 secs for on-demand and 30 secs for Preemptible instances
- Startup & Shutdown scripts are executed using
root user
- Startup & Shutdown scripts can be provided to the VM instance using
- local file, supported by
gcloud only
- inline using
startup-script or shutdown-script option
- Cloud Storage URL and
startup-script-url or shutdown-script-url as the metadata key, provided the instance has access to the script
Machine Image
- A machine image is a Compute Engine resource that stores all the configuration, metadata, permissions, and data from one or more disks required to create a virtual machine (VM) instance.
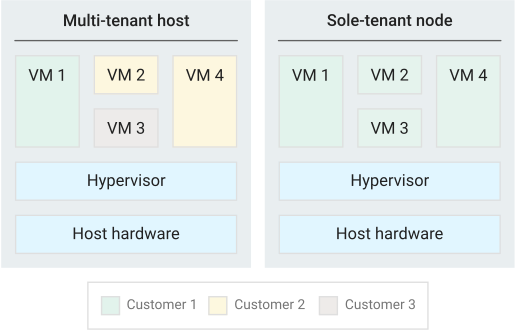
Sole Tenant Nodes
- Sole-tenancy provides dedicated hosting only for the project’s VM and provides an added layer of hardware isolation
- Sole-tenant nodes ensure that the VMs do not share host hardware with VMs from other projects
- Each sole-tenant node maintains a one-to-one mapping to the physical server that is backing the node
- Project has exclusive access to a sole-tenant node, which is a physical CE server and can be used to keep the VMs physically separated from VMs in other projects or to group the VMs together on the same host hardware
- Sole-tenant nodes can help meet dedicated hardware requirements for bring your own license (BYOL) scenarios that require per-core or per-processor licenses
Preventing Accidental VM Deletion
- Accidental VM deletion can be prevented by setting the property
deletionProtection on an instance resource esp. for VMs running critical workloads and need to be protected
- Deletion request fails if a user attempts to delete a VM instance for which the
deletionProtection flag is set
- Only a user granted with
compute.instances.create permission can reset the flag to allow the resource to be deleted.
- Deletion prevention does not prevent the following actions:
- Terminating an instance from within the VM (such as running the
shutdown command)
- Stopping an instance
- Resetting an instance
- Suspending an instance
- Instances being removed due to fraud and abuse after being detected by Google
- Instances being removed due to project termination
- Deletion protection can be applied to both regular and preemptible VMs.
- Deletion protection cannot be applied to VMs that are part of a managed instance group but can be applied to instances that are part of unmanaged instance groups.
- Deletion prevention cannot be specified in instance templates.
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your company hosts multiple applications on Compute Engine instances. They want the instances to be resilient to any Host maintenance activities performed on the instance. How would you configure the instances?
- Set
automaticRestart availability policy to true
- Set
automaticRestart availability policy to false
- Set
onHostMaintenance availability policy to migrate instances
- Set
onHostMaintenance availability policy to terminate instances
References
Google Cloud Engine – Compute Engine documentation