Amazon Athena
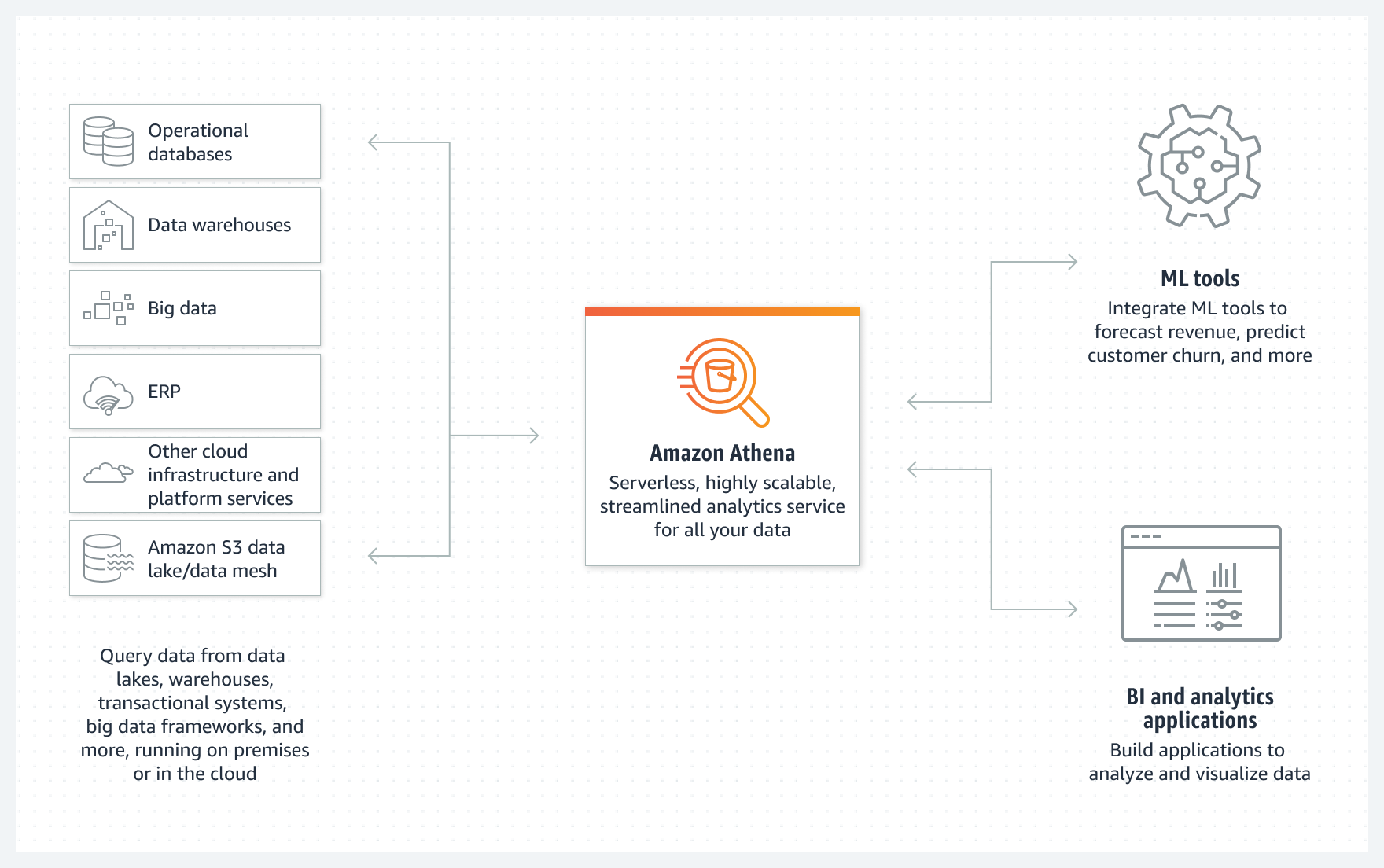
- Amazon Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open-table and file formats.
- provides a simplified, flexible way to analyze petabytes of data in an S3 data lake and 30+ data sources, including on-premises data sources or other cloud systems using SQL or Python without loading the data.
- is built on open-source Trino and Presto engines and Apache Spark frameworks, with no provisioning or configuration effort required.
- supports Athena for Apache Spark, enabling serverless Spark applications for advanced analytics and machine learning workloads.
- features Athena SQL v3 engine with improved performance, enhanced SQL capabilities, and better cost optimization.
- offers Provisioned Capacity mode for predictable query performance and consistent workloads alongside the traditional on-demand pricing.
- is highly available and runs queries using compute resources across multiple facilities, automatically routing queries appropriately if a particular facility is unreachable
- can process unstructured, semi-structured, and structured datasets.
- integrates with QuickSight for visualizing the data or creating dashboards.
- supports various standard data formats, including CSV, TSV, JSON, ORC, Avro, and Parquet.
- supports modern table formats including Apache Iceberg, Delta Lake, and Apache Hudi for ACID transactions and time travel queries.
- supports compressed data in Snappy, Zlib, LZO, and GZIP formats. You can improve performance and reduce costs by compressing, partitioning, and using columnar formats.
- enables cross-region querying to analyze data stored across multiple AWS regions from a single query interface.
- can handle complex analysis, including large joins, window functions, and arrays
- uses a managed Glue Data Catalog to store information and schemas about the databases and tables that you create for the data stored in S3
- uses schema-on-read technology, which means that the table definitions are applied to the data in S3 when queries are being applied. There’s no data loading or transformation required. Table definitions and schema can be deleted without impacting the underlying data stored in S3.
- supports fine-grained access control with AWS Lake Formation which allows for centrally managing permissions and access control for data catalog resources in the S3 data lake.
- integrates with Amazon DataZone for comprehensive data governance, cataloging, and discovery across the organization.
- supports AWS Clean Rooms integration for privacy-preserving collaborative analytics without sharing raw data.
Athena Workgroups
- Athena workgroups can be used to separate users, teams, applications, or workloads, to set limits on amount of data each query or the entire workgroup can process, and to track costs.
- Resource-level identity-based policies can be used to control access to a specific workgroup.
- Workgroups help view query-related metrics in CloudWatch, control costs by configuring limits on the amount of data scanned, create thresholds, and trigger actions, such as SNS, when these thresholds are breached.
- Workgroups now support query result reuse and caching to reduce costs and improve performance for repeated queries.
- Enhanced cost controls with per-query data scanning limits and automatic query termination for runaway queries.
- Workgroup-level encryption settings and fine-grained access controls for improved security governance.
- Workgroups can now be configured with Provisioned Capacity for consistent performance and predictable costs.
- Workgroups integrate with IAM, CloudWatch, Simple Notification Service, and AWS Cost and Usage Reports as follows:
- IAM identity-based policies with resource-level permissions control who can run queries in a workgroup.
- Athena publishes the workgroup query metrics to CloudWatch if you enable query metrics.
- SNS topics can be created that issue alarms to specified workgroup users when data usage controls for queries in a workgroup exceed the established thresholds.
- Workgroup tag can be configured as a cost allocation tag in the Billing and Cost Management console and the costs associated with running queries in that workgroup appear in the Cost and Usage Reports with that cost allocation tag.
Athena Best Practices
- Partition the data
- which helps keep the related data together based on column values such as date, country, and region.
- Athena supports Hive partitioning and advanced partition projection with custom expressions.
- Use dynamic partition pruning for improved query performance with complex partition schemes.
- Consider partition evolution strategies when using modern table formats like Iceberg.
- Pick partition keys that will support the queries
- Partition projection is an Athena feature that stores partition information not in the Glue Data Catalog but as rules in the properties of the table in AWS Glue.
- Compression
- Compressing the data can speed up queries significantly, as long as the files are either of an optimal size or the files are splittable.
- Smaller data sizes reduce the data scanned from S3, resulting in lower costs of running queries and reduced network traffic.
- Optimize file sizes
- Queries run more efficiently when data scanning can be parallelized and when blocks of data can be read sequentially.
- Modern file formats and optimization
- Columnar storage formats like ORC and Parquet remain optimal for analytical workloads.
- Apache Iceberg tables provide ACID transactions, schema evolution, and time travel capabilities.
- Delta Lake integration enables reliable data lakes with ACID guarantees.
- Use Z-ordering and data clustering techniques for improved query performance.
- A splittable file can be read in parallel by the execution engine in Athena, whereas an unsplittable file can’t be read in parallel.
- Query optimization and performance
- Leverage query result caching and reuse for frequently executed queries.
- Use EXPLAIN and ANALYZE statements to understand query execution plans.
- Implement query performance monitoring with CloudWatch Insights.
- Consider Provisioned Capacity for consistent performance requirements.
- Optimize queries by using appropriate WHERE clauses and avoiding SELECT * statements.
Security and Governance
- Enhanced Lake Formation Integration: Row-level and cell-level security controls for fine-grained data access.
- Data Masking and Anonymization: Built-in functions for protecting sensitive data during queries.
- Cross-Account Access: Secure data sharing across AWS accounts with resource-based policies.
- Audit and Compliance: Comprehensive query logging and data lineage tracking through AWS CloudTrail and DataZone.
- Encryption Enhancements: Support for customer-managed KMS keys and field-level encryption.
- Identity-Based Access Control: Integration with AWS IAM for fine-grained permissions and role-based access.
- VPC Endpoints: Private connectivity to Athena without internet gateway requirements.
Advanced Use Cases and Patterns
- Machine Learning Integration: Query results can be directly used with Amazon SageMaker for ML model training and inference.
- Real-time Analytics: Near real-time querying of streaming data from Kinesis Data Firehose with minimal latency.
- Federated Queries: Query data across multiple sources including RDS, Redshift, and on-premises databases using Athena Federated Query.
- Data Mesh Architecture: Athena serves as a query engine for decentralized data architectures with domain-specific data products.
- Serverless ETL Pipelines: Combine Athena with AWS Step Functions and Lambda for fully serverless data processing workflows.
- Cost Optimization Patterns: Implement intelligent tiering and lifecycle policies based on query patterns and data access frequency.
- Multi-Account Analytics: Centralized analytics across multiple AWS accounts using cross-account access patterns.
- Hybrid Cloud Analytics: Query on-premises data alongside cloud data using federated query capabilities.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A SysOps administrator is storing access logs in Amazon S3 and wants to use standard SQL to query data and generate a report without having to manage infrastructure. Which AWS service will allow the SysOps administrator to accomplish this task?
- Amazon Inspector
- Amazon CloudWatch
- Amazon Athena
- Amazon RDS
- A Solutions Architect must design a storage solution for incoming billing reports in CSV format. The data does not need to be scanned frequently and is discarded after 30 days. Which service will be MOST cost-effective in meeting these requirements?
- Import the logs into an RDS MySQL instance
- Use AWS Data pipeline to import the logs into a DynamoDB table
- Write the files to an S3 bucket and use Amazon Athena to query the data
- Import the logs to an Amazon Redshift cluster
- A data engineering team needs to implement ACID transactions and time travel queries on their data lake. They want to maintain compatibility with existing Athena queries while adding these capabilities. Which solution should they choose?
- Migrate to Amazon Redshift Spectrum
- Use Amazon EMR with Apache Hive
- Implement Apache Iceberg tables with Athena
- Use AWS Glue with Delta Lake format
- An organization wants to share analytical insights with external partners without exposing raw data. They need to perform collaborative analytics while maintaining data privacy. Which AWS service integration with Athena would be most appropriate?
- AWS Lake Formation with external account access
- AWS Clean Rooms with Athena integration
- Amazon QuickSight with embedded dashboards
- AWS DataSync with cross-account replication
- A company wants to optimize costs for their Athena workloads that have predictable query patterns and consistent performance requirements. Which Athena feature should they implement?
- Athena Federated Query
- Athena for Apache Spark
- Athena Provisioned Capacity
- Athena Query Result Reuse
4 thoughts on “Amazon Athena”
Comments are closed.