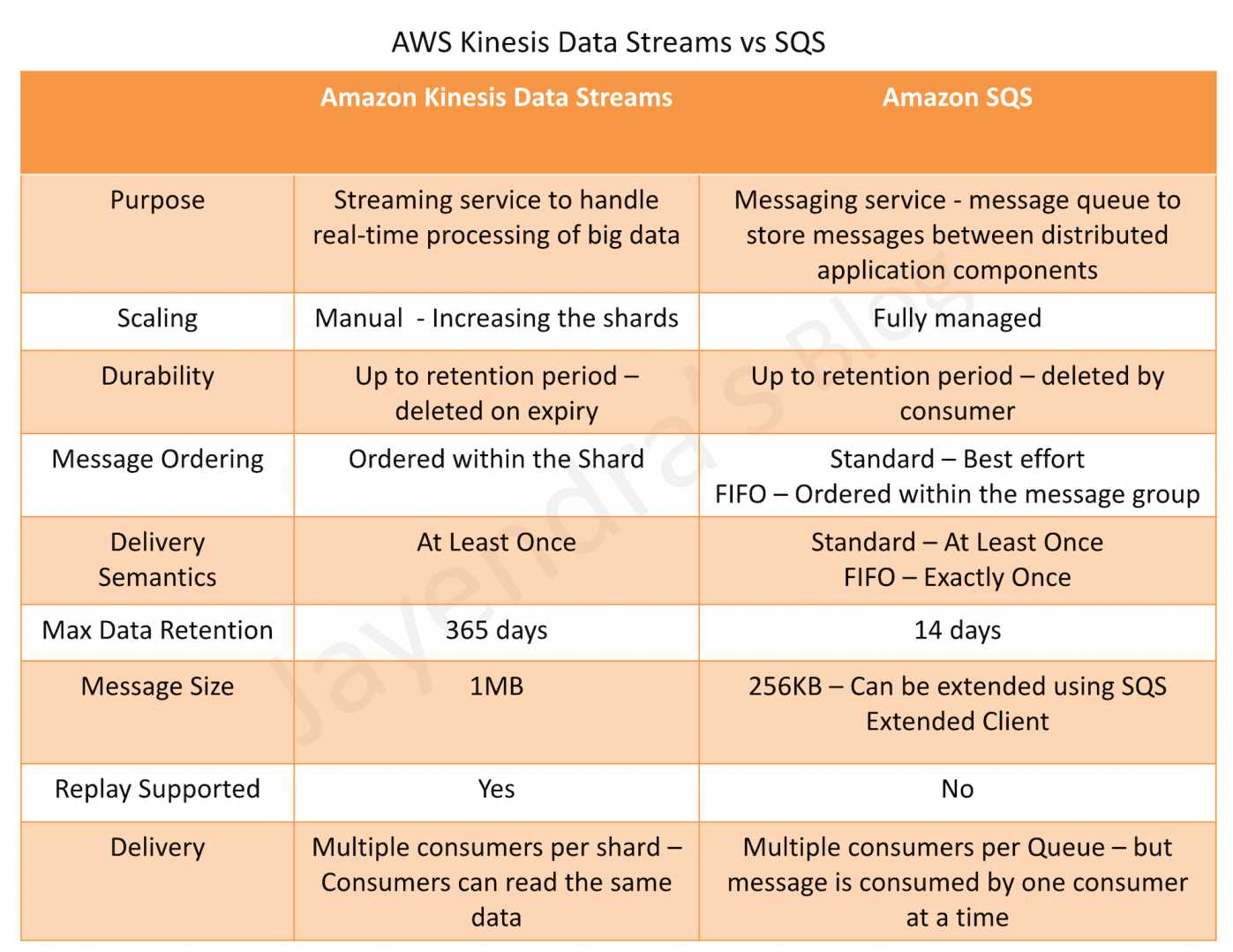
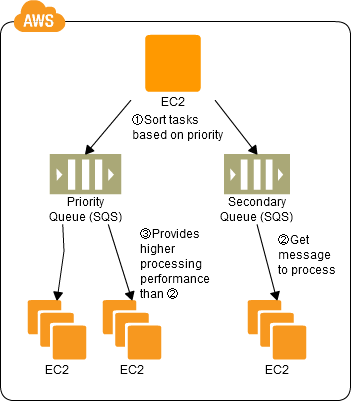allows real-time processing of streaming big data and the ability to read and replay records to multiple Amazon Kinesis Applications.
Amazon Kinesis Client Library (KCL) delivers all records for a given partition key to the same record processor, making it easier to build multiple applications that read from the same Amazon Kinesis stream (for example, to perform counting, aggregation, and filtering).
offers a reliable, highly-scalable hosted queue for storing messages as they travel between applications or microservices.
It moves data between distributed application components and helps decouple these components.
provides common middleware constructs such as dead-letter queues and poison-pill management.
provides a generic web services API and can be accessed by any programming language that the AWS SDK supports.
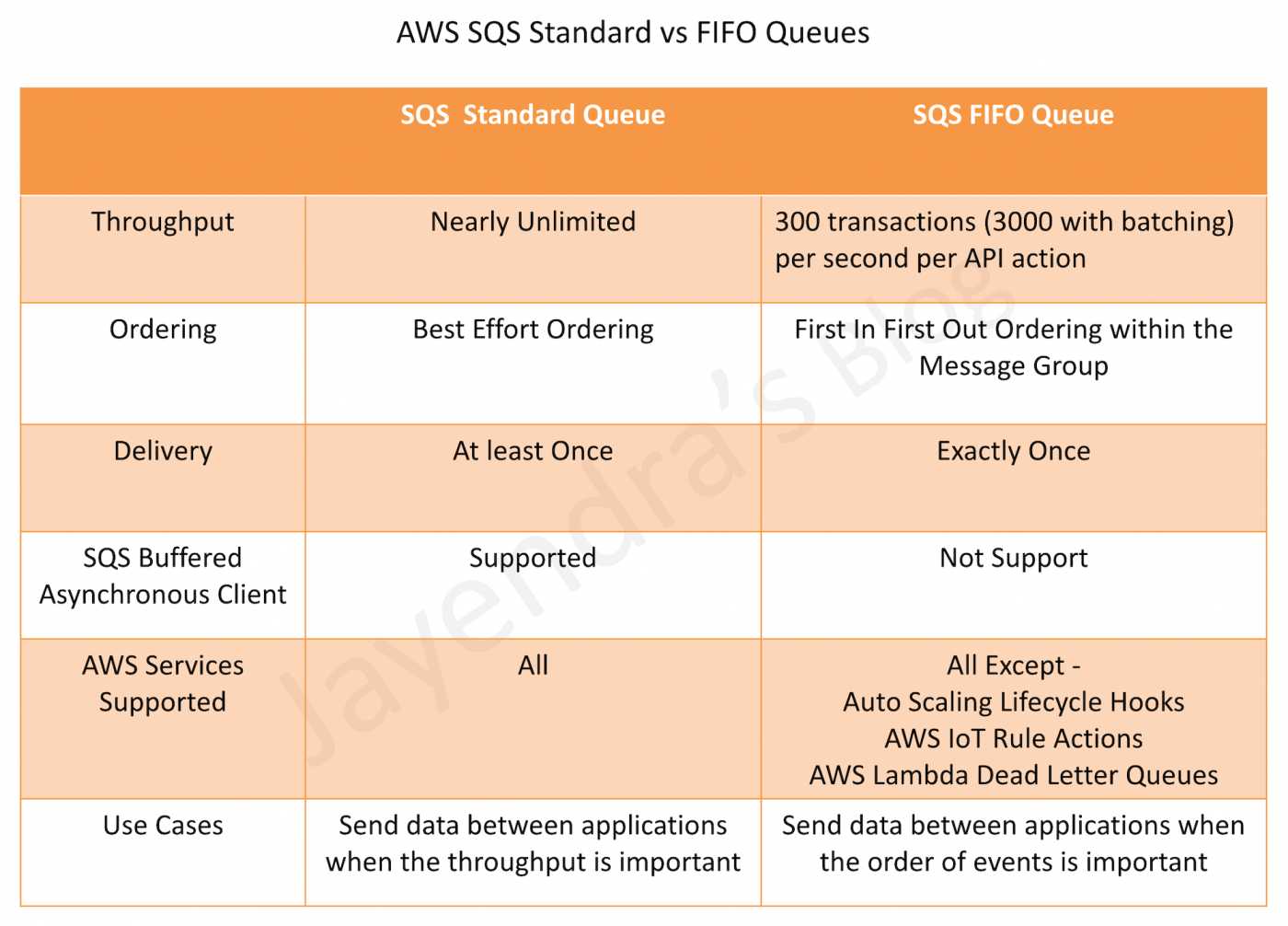
supports both standard and FIFO queues
Scaling
Kinesis Data streams is not fully managed and requires manual provisioning and scaling by increasing shards
SQS is fully managed, highly scalable and requires no administrative overhead and little configuration
Ordering
Kinesis provides ordering of records, as well as the ability to read and/or replay records in the same order to multiple Kinesis Applications
SQS Standard Queue does not guarantee data ordering and provides at least once delivery of messages
SQS FIFO Queue guarantees data ordering within the message group
Data Retention Period
Kinesis Data Streams stores the data for up to 24 hours, by default, and can be extended to 365 days
SQS stores the message for up to 4 days, by default, and can be configured from 1 minute to 14 days but clears the message once deleted by the consumer
Delivery Semantics
Kinesis and SQS Standard Queue both guarantee at least one delivery of the message.
SQS FIFO Queue guarantees Exactly once delivery
Parallel Clients
Kinesis supports multiple consumers
SQS allows the messages to be delivered to only one consumer at a time and requires multiple queues to deliver messages to multiple consumers
Use Cases
Kinesis use cases requirements
Ordering of records.
Ability to consume records in the same order a few hours later
Ability for multiple applications to consume the same stream concurrently
Routing related records to the same record processor (as in streaming MapReduce)
SQS uses cases requirements
Messaging semantics like message-level ack/fail and visibility timeout
Leveraging SQS’s ability to scale transparently
Dynamically increasing concurrency/throughput at read time
Individual message delay, which can be delayed
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
You are deploying an application to track GPS coordinates of delivery trucks in the United States. Coordinates are transmitted from each delivery truck once every three seconds. You need to design an architecture that will enable real-time processing of these coordinates from multiple consumers. Which service should you use to implement data ingestion?
Amazon Kinesis
AWS Data Pipeline
Amazon AppStream
Amazon Simple Queue Service
Your customer is willing to consolidate their log streams (access logs, application logs, security logs etc.) in one single system. Once consolidated, the customer wants to analyze these logs in real time based on heuristics. From time to time, the customer needs to validate heuristics, which requires going back to data samples extracted from the last 12 hours? What is the best approach to meet your customer’s requirements?
Send all the log events to Amazon SQS. Setup an Auto Scaling group of EC2 servers to consume the logs and apply the heuristics.
Send all the log events to Amazon Kinesis develop a client process to apply heuristics on the logs (Can perform real time analysis and stores data for 24 hours which can be extended to 7 days)
Configure Amazon CloudTrail to receive custom logs, use EMR to apply heuristics the logs (CloudTrail is only for auditing)
Setup an Auto Scaling group of EC2 syslogd servers, store the logs on S3 use EMR to apply heuristics on the logs (EMR is for batch analysis)
Simple Queue Service – SQS is a highly available distributed queue system
A queue is a temporary repository for messages awaiting processing and acts as a buffer between the component producer and the consumer
is a message queue service used by distributed applications to exchange messages through a polling model, and can be used to decouple sending and receiving components.
is fully managed and requires no administrative overhead and little configuration
offers a reliable, highly-scalable, hosted queue for storing messages in transit between applications.
provides fault-tolerant, loosely coupled, flexibility of distributed components of applications to send & receive without requiring each component to be concurrently available
helps build distributed applications with decoupled components
supports encryption at rest and encryption in transit using the HTTP over SSL (HTTPS) and Transport Layer Security (TLS) protocols for security.
Standard queues support at-least-once message delivery. However, occasionally (because of the highly distributed architecture that allows nearly unlimited throughput), more than one copy of a message might be delivered out of order.
Standard queues support a nearly unlimited number of API calls per second, per API action (SendMessage, ReceiveMessage, or DeleteMessage).
Standard queues provide best-effort ordering which ensures that messages are generally delivered in the same order as they’re sent.
FIFO (First-In-First-Out) queues provide messages in order and exactly once delivery.
FIFO queues have all the capabilities of the standard queues but are designed to enhance messaging between applications when the order of operations and events is critical, or where duplicates can’t be tolerated.
Decouple components of a distributed application that may not all process the same amount of work simultaneously.
Buffer and Batch Operations
Add scalability and reliability to the architecture and smooth out temporary volume spikes without losing messages or increasing latency
Request Offloading
Move slow operations off of interactive request paths by enqueueing the request.
Fan-out
Combine SQS with SNS to send identical copies of a message to multiple queues in parallel for simultaneous processing.
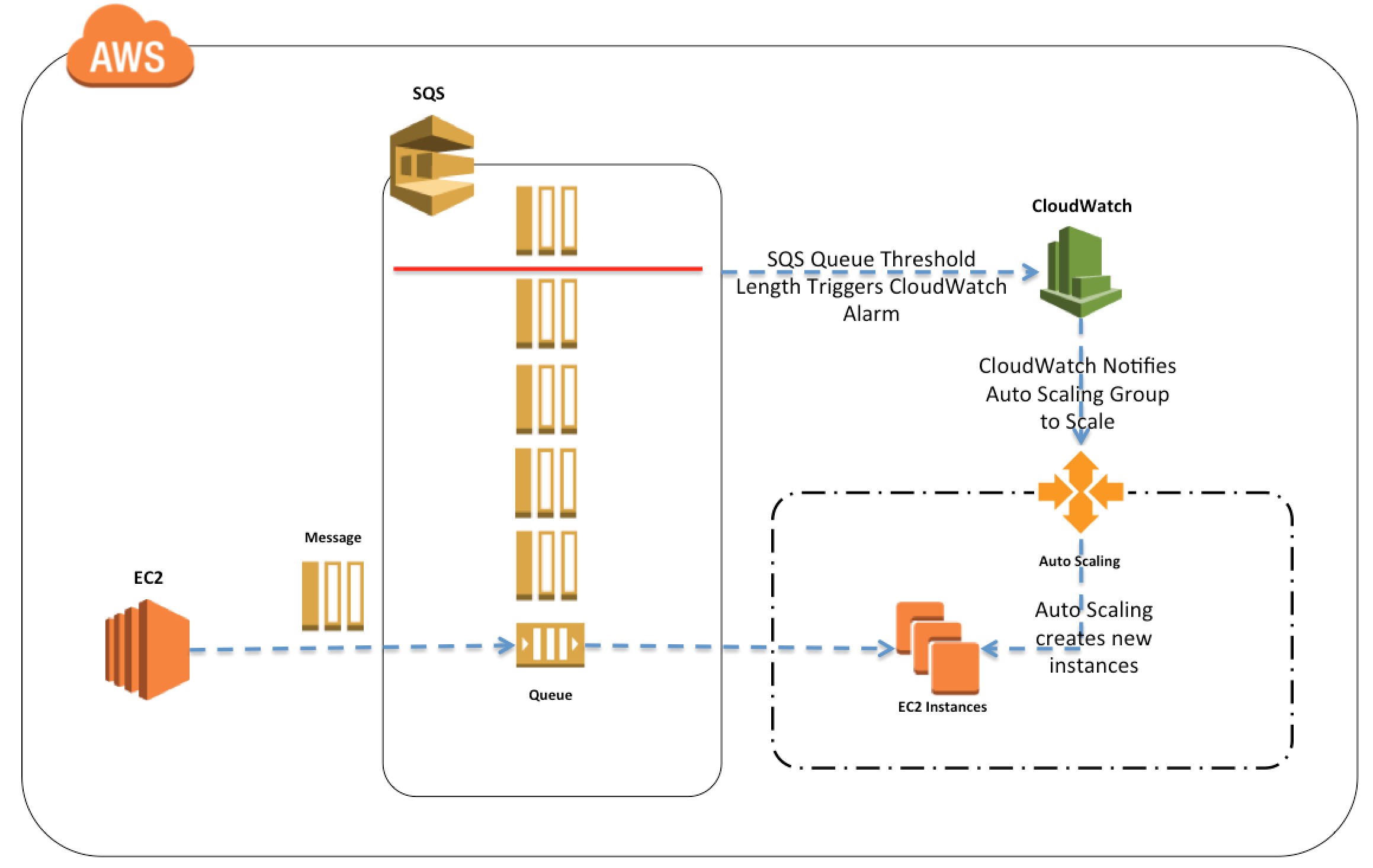
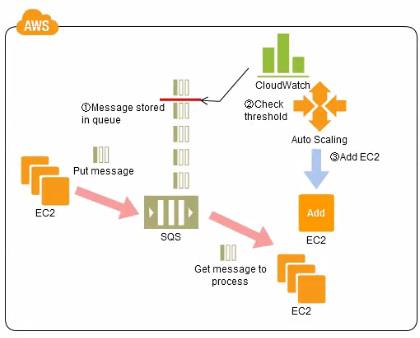
Auto Scaling
SQS queues can be used to determine the load on an application, and combined with Auto Scaling, the EC2 instances can be scaled in or out, depending on the volume of traffic
How SQS Queues Works
SQS allows queues to be created, deleted and messages can be sent and received from it
SQS queue retains messages for four days, by default.
Queues can be configured to retain messages for 1 minute to 14 days after the message has been sent.
SQS can delete a queue without notification if any action hasn’t been performed on it for 30 consecutive days.
SQS allows the deletion of the queue with messages in it
Visibility timeout defines the period where SQS blocks the visibility of the message and prevents other consuming components from receiving and processing that message.
DLQ Redrive policy specifies the source queue, the dead-letter queue, and the conditions under which SQS moves messages from the former to the latter if the consumer of the source queue fails to process a message a specified number of times.
SQS Short and Long polling control how the queues would be polled and Long polling help reduce empty responses.
SQS Buffered Asynchronous Client
Amazon SQS Buffered Async Client for Java provides an implementation of the AmazonSQSAsyncClient interface and adds several important features:
Automatic batching of multiple SendMessage, DeleteMessage, or ChangeMessageVisibility requests without any required changes to the application
Prefetching of messages into a local buffer that allows the application to immediately process messages from SQS without waiting for the messages to be retrieved
Working together, automatic batching and prefetching increase the throughput and reduce the latency of the application while reducing the costs by making fewer SQS requests.
SQS Security and reliability
SQS stores all message queues and messages within a single, highly-available AWS region with multiple redundant Availability Zones (AZs)
SQS supports HTTP over SSL (HTTPS) and Transport Layer Security (TLS) protocols.
SQS supports Encryption at Rest. SSE encrypts messages as soon as SQS receives them and decrypts messages only when they are sent to an authorized consumer.
SQS also supports resource-based permissions
SQS Design Patterns
Priority Queue Pattern
Use SQS to prepare multiple queues for the individual priority levels.
Place those processes to be executed immediately (job requests) in the high priority queue.
Prepare numbers of batch servers, for processing the job requests of the queues, depending on the priority levels.
Queues have a message “Delayed Send” function, which can be used to delay the time for starting a process.
SQS Job Observer Pattern
Enqueue job requests as SQS messages.
Have the batch server dequeue and process messages from SQS.
Set up Auto Scaling to automatically increase or decrease the number of batch servers, using the number of SQS messages, with CloudWatch, as the trigger to do so.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which AWS service can help design architecture to persist in-flight transactions?
Elastic IP Address
SQS
Amazon CloudWatch
Amazon ElastiCache
A company has a workflow that sends video files from their on-premise system to AWS for transcoding. They use EC2 worker instances that pull transcoding jobs from SQS. Why is SQS an appropriate service for this scenario?
SQS guarantees the order of the messages.
SQS synchronously provides transcoding output.
SQS checks the health of the worker instances.
SQS helps to facilitate horizontal scaling of encoding tasks
Which statement best describes an Amazon SQS use case?
Automate the process of sending an email notification to administrators when the CPU utilization reaches 70% on production servers (Amazon EC2 instances) (CloudWatch + SNS + SES)
Create a video transcoding website where multiple components need to communicate with each other, but can’t all process the same amount of work simultaneously (SQS provides loose coupling)
Coordinate work across distributed web services to process employee’s expense reports (SWF – Steps in order and might need manual steps)
Distribute static web content to end users with low latency across multiple countries (CloudFront + S3)
Your application provides data transformation services. Files containing data to be transformed are first uploaded to Amazon S3 and then transformed by a fleet of spot EC2 instances. Files submitted by your premium customers must be transformed with the highest priority. How should you implement such a system?
Use a DynamoDB table with an attribute defining the priority level. Transformation instances will scan the table for tasks, sorting the results by priority level.
Use Route 53 latency based-routing to send high priority tasks to the closest transformation instances.
Use two SQS queues, one for high priority messages, and the other for default priority. Transformation instances first poll the high priority queue; if there is no message, they poll the default priority queue
Use a single SQS queue. Each message contains the priority level. Transformation instances poll high-priority messages first.
Your company plans to host a large donation website on Amazon Web Services (AWS). You anticipate a large and undetermined amount of traffic that will create many database writes. To be certain that you do not drop any writes to a database hosted on AWS. Which service should you use?
Amazon RDS with provisioned IOPS up to the anticipated peak write throughput.
Amazon Simple Queue Service (SQS) for capturing the writes and draining the queue to write to the database
Amazon ElastiCache to store the writes until the writes are committed to the database.
Amazon DynamoDB with provisioned write throughput up to the anticipated peak write throughput.
A customer has a 10 GB AWS Direct Connect connection to an AWS region where they have a web application hosted on Amazon Elastic Computer Cloud (EC2). The application has dependencies on an on-premises mainframe database that uses a BASE (Basic Available, Soft state, Eventual consistency) rather than an ACID (Atomicity, Consistency, Isolation, Durability) consistency model. The application is exhibiting undesirable behavior because the database is not able to handle the volume of writes. How can you reduce the load on your on-premises database resources in the most cost-effective way?
Use an Amazon Elastic Map Reduce (EMR) S3DistCp as a synchronization mechanism between the onpremises database and a Hadoop cluster on AWS.
Modify the application to write to an Amazon SQS queue and develop a worker process to flush the queue to the on-premises database
Modify the application to use DynamoDB to feed an EMR cluster which uses a map function to write to the on-premises database.
Provision an RDS read-replica database on AWS to handle the writes and synchronize the two databases using Data Pipeline.
An organization has created a Queue named “modularqueue” with SQS. The organization is not performing any operations such as SendMessage, ReceiveMessage, DeleteMessage, GetQueueAttributes, SetQueueAttributes, AddPermission, and RemovePermission on the queue. What can happen in this scenario?
AWS SQS sends notification after 15 days for inactivity on queue
AWS SQS can delete queue after 30 days without notification
AWS SQS marks queue inactive after 30 days
AWS SQS notifies the user after 2 weeks and deletes the queue after 3 weeks.
A user is using the AWS SQS to decouple the services. Which of the below mentioned operations is not supported by SQS?
SendMessageBatch
DeleteMessageBatch
CreateQueue
DeleteMessageQueue
A user has created a queue named “awsmodule” with SQS. One of the consumers of queue is down for 3 days and then becomes available. Will that component receive message from queue?
Yes, since SQS by default stores message for 4 days
No, since SQS by default stores message for 1 day only
No, since SQS sends message to consumers who are available that time
Yes, since SQS will not delete message until it is delivered to all consumers
A user has created a queue named “queue2” in US-East region with AWS SQS. The user’s AWS account ID is 123456789012. If the user wants to perform some action on this queue, which of the below Queue URL should he use?
A user has created a queue named “myqueue” with SQS. There are four messages published to queue, which are not received by the consumer yet. If the user tries to delete the queue, what will happen?
A user can never delete a queue manually. AWS deletes it after 30 days of inactivity on queue
It will delete the queue
It will initiate the delete but wait for four days before deleting until all messages are deleted automatically.
I t will ask user to delete the messages first
A user has developed an application, which is required to send the data to a NoSQL database. The user wants to decouple the data sending such that the application keeps processing and sending data but does not wait for an acknowledgement of DB. Which of the below mentioned applications helps in this scenario?
AWS Simple Notification Service
AWS Simple Workflow
AWS Simple Queue Service
AWS Simple Query Service
You are building an online store on AWS that uses SQS to process your customer orders. Your backend system needs those messages in the same sequence the customer orders have been put in. How can you achieve that?
It is not possible to do this with SQS
You can use sequencing information on each message
You can do this with SQS but you also need to use SWF
Messages will arrive in the same order by default
A user has created a photo editing software and hosted it on EC2. The software accepts requests from the user about the photo format and resolution and sends a message to S3 to enhance the picture accordingly. Which of the below mentioned AWS services will help make a scalable software with the AWS infrastructure in this scenario?
AWS Glacier
AWS Elastic Transcoder
AWS Simple Notification Service
AWS Simple Queue Service
Refer to the architecture diagram of a batch processing solution using Simple Queue Service (SQS) to set up a message queue between EC2 instances, which are used as batch processors. Cloud Watch monitors the number of Job requests (queued messages) and an Auto Scaling group adds or deletes batch servers automatically based on parameters set in Cloud Watch alarms. You can use this architecture to implement which of the following features in a cost effective and efficient manner?
Reduce the overall time for executing jobs through parallel processing by allowing a busy EC2 instance that receives a message to pass it to the next instance in a daisy-chain setup.
Implement fault tolerance against EC2 instance failure since messages would remain in SQS and worn can continue with recovery of EC2 instances implement fault tolerance against SQS failure by backing up messages to S3.
Implement message passing between EC2 instances within a batch by exchanging messages through SOS.
Coordinate number of EC2 instances with number of job requests automatically thus Improving cost effectiveness
Handle high priority jobs before lower priority jobs by assigning a priority metadata field to SQS messages.
How does Amazon SQS allow multiple readers to access the same message queue without losing messages or processing them many times?
By identifying a user by his unique id
By using unique cryptography
Amazon SQS queue has a configurable visibility timeout
Multiple readers can’t access the same message queue
A user has created photo editing software and hosted it on EC2. The software accepts requests from the user about the photo format and resolution and sends a message to S3 to enhance the picture accordingly. Which of the below mentioned AWS services will help make a scalable software with the AWS infrastructure in this scenario?
AWS Elastic Transcoder
AWS Simple Notification Service
AWS Simple Queue Service
AWS Glacier
How do you configure SQS to support longer message retention?
Set the MessageRetentionPeriod attribute using the SetQueueAttributes method
Using a Lambda function
You can’t. It is set to 14 days and cannot be changed
You need to request it from AWS
A user has developed an application, which is required to send the data to a NoSQL database. The user wants to decouple the data sending such that the application keeps processing and sending data but does not wait for an acknowledgement of DB. Which of the below mentioned applications helps in this scenario?
AWS Simple Notification Service
AWS Simple Workflow
AWS Simple Query Service
AWS Simple Queue Service
If a message is retrieved from a queue in Amazon SQS, how long is the message inaccessible to other users by default?
0 seconds
1 hour
1 day
forever
30 seconds
Which of the following statements about SQS is true?
Messages will be delivered exactly once and messages will be delivered in First in, First out order
Messages will be delivered exactly once and message delivery order is indeterminate
Messages will be delivered one or more times and messages will be delivered in First in, First out order
Messages will be delivered one or more times and message delivery order is indeterminate (Before the introduction of FIFO queues)
How long can you keep your Amazon SQS messages in Amazon SQS queues?
From 120 secs up to 4 weeks
From 10 secs up to 7 days
From 60 secs up to 2 weeks
From 30 secs up to 1 week
When a Simple Queue Service message triggers a task that takes 5 minutes to complete, which process below will result in successful processing of the message and remove it from the queue while minimizing the chances of duplicate processing?
Retrieve the message with an increased visibility timeout, process the message, delete the message from the queue
Retrieve the message with an increased visibility timeout, delete the message from the queue, process the message
Retrieve the message with increased DelaySeconds, process the message, delete the message from the queue
Retrieve the message with increased DelaySeconds, delete the message from the queue, process the message
You need to process long-running jobs once and only once. How might you do this?
Use an SNS queue and set the visibility timeout to long enough for jobs to process.
Use an SQS queue and set the reprocessing timeout to long enough for jobs to process.
Use an SQS queue and set the visibility timeout to long enough for jobs to process.
Use an SNS queue and set the reprocessing timeout to long enough for jobs to process.
You are getting a lot of empty receive requests when using Amazon SQS. This is making a lot of unnecessary network load on your instances. What can you do to reduce this load?
Subscribe your queue to an SNS topic instead.
Use as long of a poll as possible, instead of short polls. (Refer link)
Alter your visibility timeout to be shorter.
Use <code>sqsd</code> on your EC2 instances.
You have an asynchronous processing application using an Auto Scaling Group and an SQS Queue. The Auto Scaling Group scales according to the depth of the job queue. The completion velocity of the jobs has gone down, the Auto Scaling Group size has maxed out, but the inbound job velocity did not increase. What is a possible issue?
Some of the new jobs coming in are malformed and unprocessable. (As other options would cause the job to stop processing completely, the only reasonable option seems that some of the recent messages must be malformed and unprocessable)
The routing tables changed and none of the workers can process events anymore. (If changed, none of the jobs would be processed)
Someone changed the IAM Role Policy on the instances in the worker group and broke permissions to access the queue. (If IAM role changed no jobs would be processed)
The scaling metric is not functioning correctly. (scaling metric did work fine as the autoscaling caused the instances to increase)
Company B provides an online image recognition service and utilizes SQS to decouple system components for scalability. The SQS consumers poll the imaging queue as often as possible to keep end-to-end throughput as high as possible. However, Company B is realizing that polling in tight loops is burning CPU cycles and increasing costs with empty responses. How can Company B reduce the number of empty responses?
Set the imaging queue visibility Timeout attribute to 20 seconds
Set the Imaging queue ReceiveMessageWaitTimeSeconds attribute to 20 seconds (Long polling. Refer link)
Set the imaging queue MessageRetentionPeriod attribute to 20 seconds
Set the DelaySeconds parameter of a message to 20 seconds