EBS Monitoring
AWS supports EBS monitoring by automatically providing data, such as CloudWatch metrics and volume status checks to help monitor EBS volumes.
CloudWatch Monitoring
- CloudWatch metrics are statistical data that you can use to view, analyze, and set alarms on the operational behavior of the EBS volumes.
- All Amazon EBS volume types automatically send 1-minute metrics to CloudWatch at no additional charge, but only when the volume is attached to an instance.
- Some metrics have differences on Nitro-based instances vs. Xen-based instances.
- EBS Metrics (AWS/EBS namespace)
- VolumeReadBytes & VolumeWriteBytes
- Provides information on the I/O operations in a specified period of time, in bytes.
- VolumeReadOps & VolumeWriteOps
- Total number (count) of I/O operations in a specified period of time.
- VolumeTotalReadTime & VolumeTotalWriteTime
- Total number of seconds spent by all operations that were completed in a specified period of time.
- For Xen instances, data is reported only when there is read/write activity on the volume.
- VolumeIdleTime
- Total number of seconds, in a specific period, when the volume was idle (no read and write operations).
- VolumeQueueLength
- Number of read and write operations, in a specific period, waiting to be completed.
- VolumeThroughputPercentage (Provisioned IOPS SSD volumes only)
- Percentage of I/O operations per second (IOPS) delivered of the total IOPS provisioned.
- VolumeConsumedReadWriteOps (Provisioned IOPS SSD volumes only)
- Total amount of read and write operations (normalized to 256K capacity units) consumed in a specified period of time.
- BurstBalance (gp2, st1, and sc1 volumes only)
- Percentage of I/O credits (for gp2) or throughput credits (for st1 and sc1) remaining in the burst bucket.
- Data is reported only when the volume is active. If the baseline performance exceeds the maximum burst performance, credits are never spent and burst balance remains at 100%.
- VolumeReadBytes & VolumeWriteBytes
I/O Latency Metrics (Nitro Instances Only – Added Oct 2024)
- VolumeReadLatency
- The per-minute average read I/O latency for the EBS volume, in milliseconds.
- VolumeWriteLatency
- The per-minute average write I/O latency for the EBS volume, in milliseconds.
- Available at 1-minute granularity at no additional charge for all EBS volumes attached to EC2 Nitro instances.
- Helps identify if latency is a result of under-provisioned EBS volumes.
Performance Exceeded Check Metrics (Nitro Instances Only – Added Oct 2024)
- VolumeIOPSExceededCheck
- Reports whether an application consistently attempted to drive IOPS that exceeds the volume’s provisioned IOPS performance within the last minute.
- Returns 0 (not exceeded) or 1 (exceeded).
- VolumeThroughputExceededCheck
- Reports whether an application consistently attempted to drive throughput that exceeds the volume’s provisioned throughput performance within the last minute.
- Returns 0 (not exceeded) or 1 (exceeded).
- Supported for all volume types except magnetic (standard) attached to Nitro instances.
- Not supported with Multi-Attach enabled volumes.
Average Performance Metrics (Nitro Instances Only – Added Oct 2025)
- VolumeAvgIOPS
- The average read and write IOPS driven to the volume in a minute.
- Returns zero if no operations were driven to the volume within the last minute.
- VolumeAvgThroughput
- The average read and write throughput (KiB/s) driven to the volume in a minute.
- Returns zero if no operations were driven to the volume within the last minute.
- Useful for tracking performance trends, detecting bottlenecks, and right-sizing provisioned performance.
Instance-Level EBS Metrics (AWS/EC2 Namespace – Nitro Instances)
- InstanceEBSIOPSExceededCheck (Added Oct 2025)
- Reports whether driven IOPS is exceeding the maximum EBS IOPS that the instance can support within the last minute.
- Returns 0 (not exceeded) or 1 (exceeded).
- InstanceEBSThroughputExceededCheck (Added Oct 2025)
- Reports whether driven throughput is exceeding the maximum EBS throughput limits for the instance within the last minute.
- Returns 0 (not exceeded) or 1 (exceeded).
- EBSReadOps & EBSWriteOps
- Completed read/write operations from all EBS volumes attached to the instance.
- EBSIOBalance% & EBSByteBalance%
- Percentage of I/O credits and throughput credits remaining for burst-capable instances.
- Available for instances that burst to their maximum performance for 30 minutes at least once every 24 hours.
CloudWatch Agent – EBS Detailed Performance Statistics (Added Jun 2025)
- The CloudWatch agent can collect NVMe-based detailed performance statistics from EBS volumes attached to Nitro instances.
- Metrics include queue depth, number of operations, bytes sent and received, and time spent on read and write I/O operations.
- Available at sub-minute granularity as custom metrics in CloudWatch.
- Provides deeper visibility beyond standard CloudWatch metrics for performance-sensitive workloads.
Volume Status Checks Monitoring
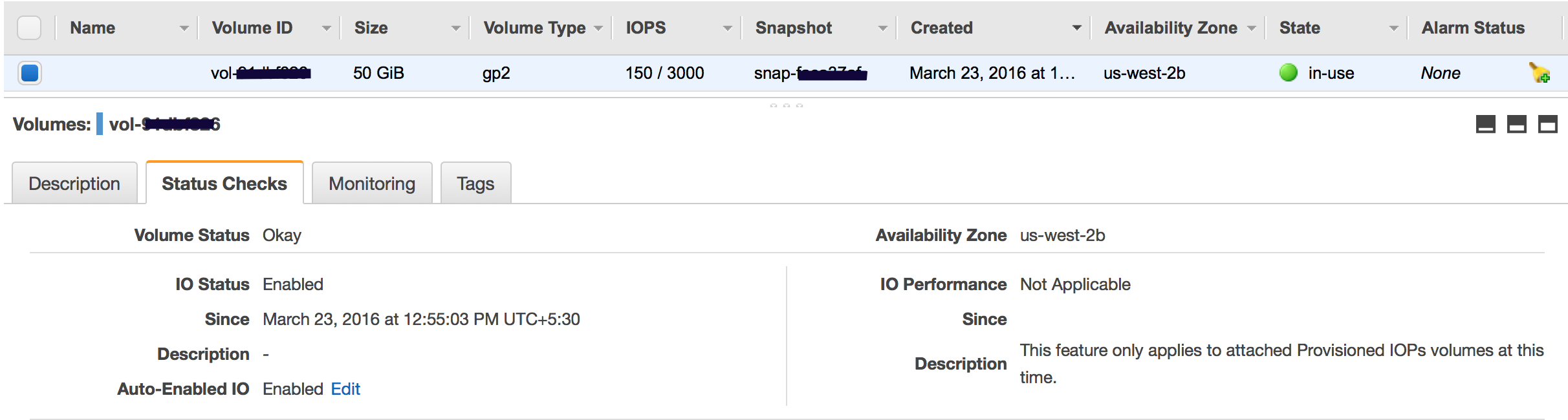
- Volume status checks are automated tests that run every 5 minutes and return a pass or fail status.
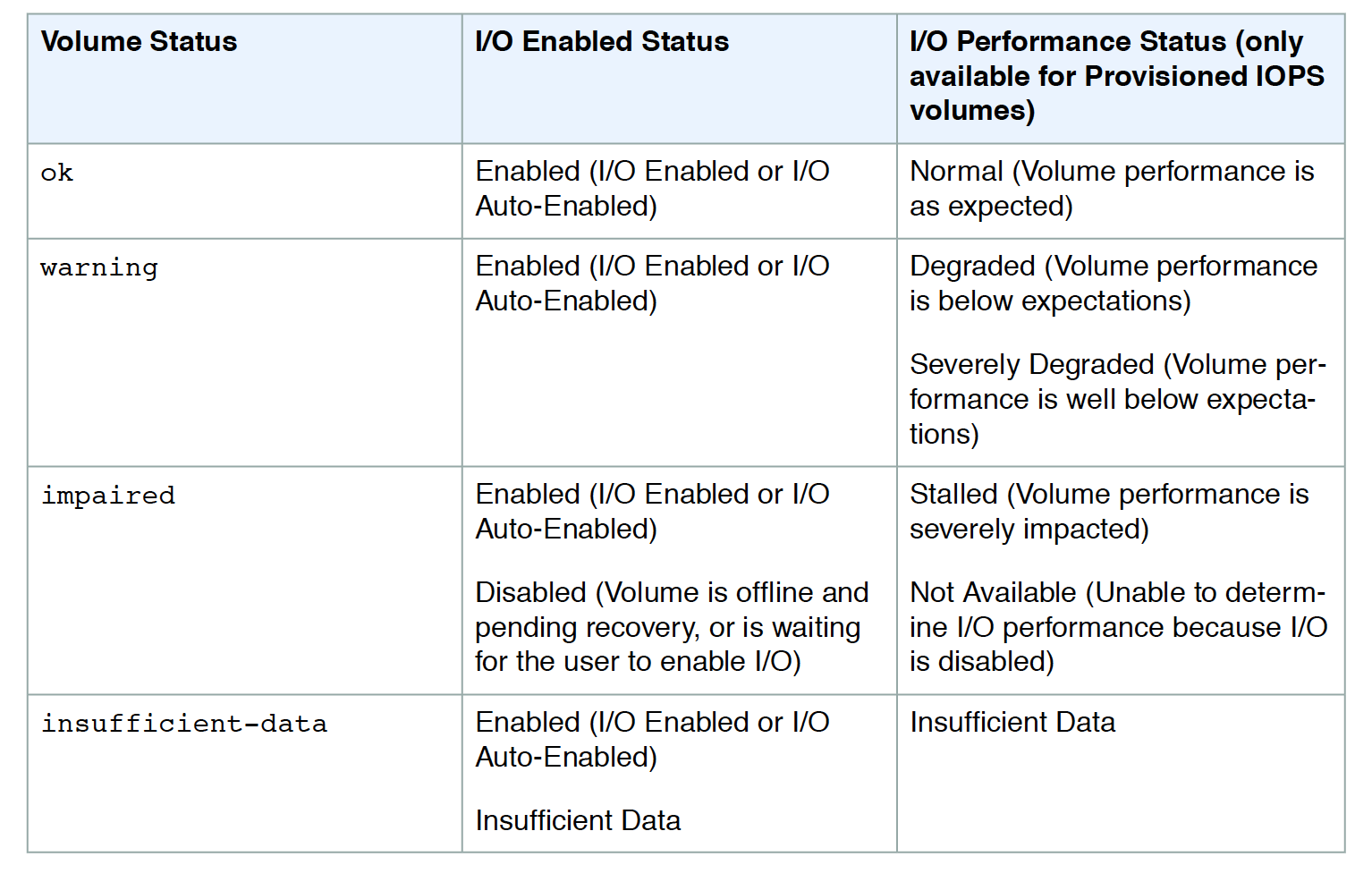
- Volume check status
- Ok – all the status checks passed
- Impaired – if the status checks failed
- Insufficient-Data – checks are still in progress
- Warning – the I/O performance of the volume is below expectations
- When EBS determines the volume’s data is potentially inconsistent, it disables the I/O to the EBS volume from the attached EC2 instance to prevent any data corruption. This leads to the status check to fail and the volume status being impaired. Amazon waits for the I/O to be enabled, giving you an opportunity to perform consistency checks.
- If the auto disabling of I/O is not needed, it can be overridden by enabling the Auto-Enabled IO flag, which would make the EBS volume auto-available immediately after the impaired status.
- Events would be fired for notification whenever the I/O for an EBS volume is disabled.
- I/O performance status checks compare actual volume performance with the expected volume performance and alert if performing below expectations. Applicable to io1, io2, and gp3 volumes.
- While initializing Provisioned IOPS (SSD) volumes that were restored from snapshots, the performance of the volume may drop below 50 percent of its expected level, which causes the volume to display a warning state in the I/O Performance status check. This is expected and can be ignored.
Attached EBS Status Checks (Added Aug 2024)
- Amazon EC2 now includes a third type of status check — Attached EBS Status Check — that monitors whether the EBS volumes attached to an instance are reachable and can complete I/O operations.
- The CloudWatch metric StatusCheckFailed_AttachedEBS reports a binary value:
- 0 – All attached EBS volumes are reachable and can complete I/O.
- 1 – One or more attached EBS volumes are impaired and unable to complete I/O operations.
- Available for Nitro-based EC2 instances.
- Enables creating CloudWatch alarms to automatically detect and respond to EBS volume reachability issues at the instance level.
- Three types of EC2 status checks now exist:
- System status checks – monitor the AWS systems the instance runs on.
- Instance status checks – monitor the instance’s software and network configuration.
- Attached EBS status checks – monitor reachability of attached EBS volumes.
Volume Initialization Status Monitoring (Added Jul 2025)
- EBS now provides visibility into volume initialization status for volumes created from snapshots.
- Allows you to validate when all blocks have been downloaded and written to the volume, enabling fully provisioned performance.
- Can be used to time application launches to align with volume initialization completion.
- EBS also supports Provisioned Rate for Volume Initialization (Added May 2025) that allows specifying a volume initialization rate between 100-300 MiB/s for faster initialization of snapshot-restored volumes.
- EventBridge events are published for volume initialization state changes.
Volume Events Monitoring
- EBS sends events to Amazon EventBridge for volume status changes and actions performed on volumes and snapshots.
- Each event includes a start time that indicates the time at which the event occurred and a duration that indicates how long I/O for the volume was disabled.
- Events description can be:
- Awaiting Action: Enable IO – Volume data is potentially inconsistent, I/O is disabled.
- IO Enabled – I/O operations were explicitly enabled for this volume.
- IO Auto-Enabled – I/O operations were automatically enabled on this volume after an event.
- Normal – For io1, io2, and gp3 volumes only. Volume performance is as expected.
- Degraded – For io1, io2, and gp3 volumes only. Volume performance is below expectations.
- Severely Degraded or Stalled – Volume performance significantly impacted.
- EventBridge rules can trigger programmatic actions in response to these events (e.g., send notifications, invoke Lambda functions).
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A user has configured CloudWatch monitoring on an EBS backed EC2 instance. If the user has not attached any additional device, which of the below mentioned metrics will always show a 0 value?
- DiskReadBytes
- NetworkIn
- NetworkOut
- CPUUtilization
- What does it mean if you have zero IOPS and a non-empty I/O queue for all EBS volumes attached to a running EC2 instance?
- The I/O queue is buffer flushing.
- Your EBS disk head(s) is/are seeking magnetic stripes.
- The EBS volume is unavailable. (EBS volumes are unavailable when all of the attached volumes perform zero read write IO, with pending IO in the queue. Refer link)
- You need to re-mount the EBS volume in the OS.
- While performing the volume status checks, if the status is insufficient-data, what does it mean?
- checks may still be in progress on the volume
- check has passed
- check has failed
- An application running on an EC2 instance with an io2 EBS volume is experiencing intermittent latency spikes. Which NEW CloudWatch metrics should be used to identify if the volume is under-provisioned? (Choose 2)
- VolumeReadLatency and VolumeWriteLatency
- VolumeQueueLength
- VolumeIOPSExceededCheck
- VolumeIdleTime
- VolumeTotalReadTime
- A company wants to monitor whether EBS volume performance bottlenecks are caused by the volume limits or the EC2 instance limits. Which combination of metrics should be used?
- VolumeReadOps and VolumeWriteOps
- BurstBalance and VolumeQueueLength
- VolumeIOPSExceededCheck (volume-level) and InstanceEBSIOPSExceededCheck (instance-level)
- EBSIOBalance% and VolumeThroughputPercentage
- After the August 2024 update, how many types of EC2 status checks are available?
- One – System status check
- Two – System and Instance status checks
- Three – System, Instance, and Attached EBS status checks
- Four – System, Instance, EBS Volume, and Network status checks