
Kubernetes and Cloud Native Associate KCNA Exam Learning Path
I recently certified for the Kubernetes and Cloud Native Associate – KCNA exam.
- KCNA exam focuses on a user’s foundational knowledge and skills in Kubernetes and the wider cloud native ecosystem.
- KCNA exam is intended to prepare candidates to work with cloud-native technologies and pursue further CNCF credentials, including CKA, CKAD, and CKS.
- KCNA validates the conceptual knowledge of
- the entire cloud native ecosystem, particularly focusing on Kubernetes.
- Kubernetes and cloud-native technologies, including how to deploy an application using basic kubectl commands, the architecture of Kubernetes (containers, pods, nodes, clusters), understanding the cloud-native landscape and projects (storage, networking, GitOps, service mesh), and understanding the principles of cloud-native security.

KCNA Exam Pattern
- KCNA exam curriculum includes these general domains and their weights on the exam:
-
Kubernetes Fundamentals – 46%
-
Container Orchestration – 22%
-
Cloud Native Architecture – 16%
-
Cloud Native Observability – 8%
-
Cloud Native Application Delivery – 8%
-
- KCNA exam requires you to solve 60 questions in 90 minutes.
- Exam questions can be attempted in any order and don’t have to be sequential. So be sure to move ahead and come back later.
- Time is more than sufficient if you are well prepared. I was able to get through the exam within an hour.
KCNA Exam Preparation and Tips
- I used the courses from KodeKloud KCNA for practicing and it would be good enough to cover what is required for the exam.
KCNA Resources
- Go through the KCNA Curriculum
- Linux Foundation KCNA Course and Certification Bundle
- KodeKloud – Mumshad Mannambeth Kubernetes and Cloud-Native Associate (KCNA) with Practice Tests
- Braincert Kubernetes and Cloud Native Associate – KCNA Practice Exams
KCNA Key Topics
Kubernetes Fundamentals
-
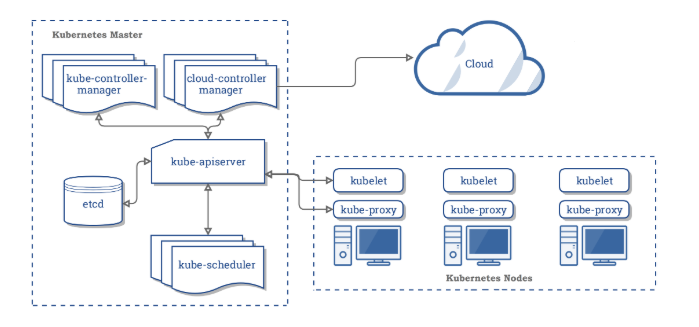
Kubernetes is a highly popular open-source container orchestration platform that can be used to automate deployment, scaling, and the management of containerized workloads.
- Kubernetes Architecture
- A Kubernetes cluster consists of at least one main (control) plane, and one or more worker machines, called nodes.
- Both the control planes and node instances can be physical devices, virtual machines, or instances in the cloud.
- ETCD (key-value store)
- Etcd is a consistent, distributed, and highly-available key-value store.
- is stateful, persistent storage that stores all of Kubernetes cluster data (cluster state and config).
- is the source of truth for the cluster.
- can be part of the control plane, or, it can be configured externally.
- Kubernetes API
- API server exposes a REST interface to the Kubernetes cluster. It is the front end for the Kubernetes control plane.
- All operations against Kubernetes objects are programmatically executed by communicating with the endpoints provided by it.
- It tracks the state of all cluster components and manages the interaction between them.
- It is designed to scale horizontally.
- It consumes YAML/JSON manifest files.
- It validates and processes the requests made via API.
- Scheduling
- The scheduler is responsible for assigning work to the various nodes. It keeps watch over the resource capacity and ensures that a worker node’s performance is within an appropriate threshold.
- It schedules pods to worker nodes.
- It watches api-server for newly created Pods with no assigned node, and selects a healthy node for them to run on.
- If there are no suitable nodes, the pods are put in a pending state until such a healthy node appears.
- It watches API Server for new work tasks.
- Factors taken into account for scheduling decisions include:
- Individual and collective resource requirements.
- Hardware/software/policy constraints.
- Affinity and anti-affinity specifications.
- Data locality.
- Inter-workload interference.
- Deadlines and taints.
- Controller Manager
- Controller manager is responsible for making sure that the shared state of the cluster is operating as expected.
- It watches the desired state of the objects it manages and watches their current state through the API server.
- It takes corrective steps to make sure that the current state is the same as the desired state.
- It is a controller of controllers.
- It runs controller processes. Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
- Kubelet
- A Kubelet tracks the state of a pod to ensure that all the containers are running and healthy
- provides a heartbeat message every few seconds to the control plane.
- runs as an agent on each node in the cluster.
- acts as a conduit between the API server and the node.
- instantiates and executes Pods.
- watches API Server for work tasks.
- gets instructions from master and reports back to Masters.
- Kube-proxy
- Kube proxy is a networking component that routes traffic coming into a node from the service to the correct containers.
- is a network proxy that runs on each node in a cluster.
- manages IP translation and routing.
- maintains network rules on nodes. These network rules allow network communication to Pods from inside or outside of cluster.
- ensures each Pod gets a unique IP address.
- makes possible that all containers in a pod share a single IP.
- facilitates Kubernetes networking services and load-balancing across all pods in a service.
- It deals with individual host sub-netting and ensures that the services are available to external parties.
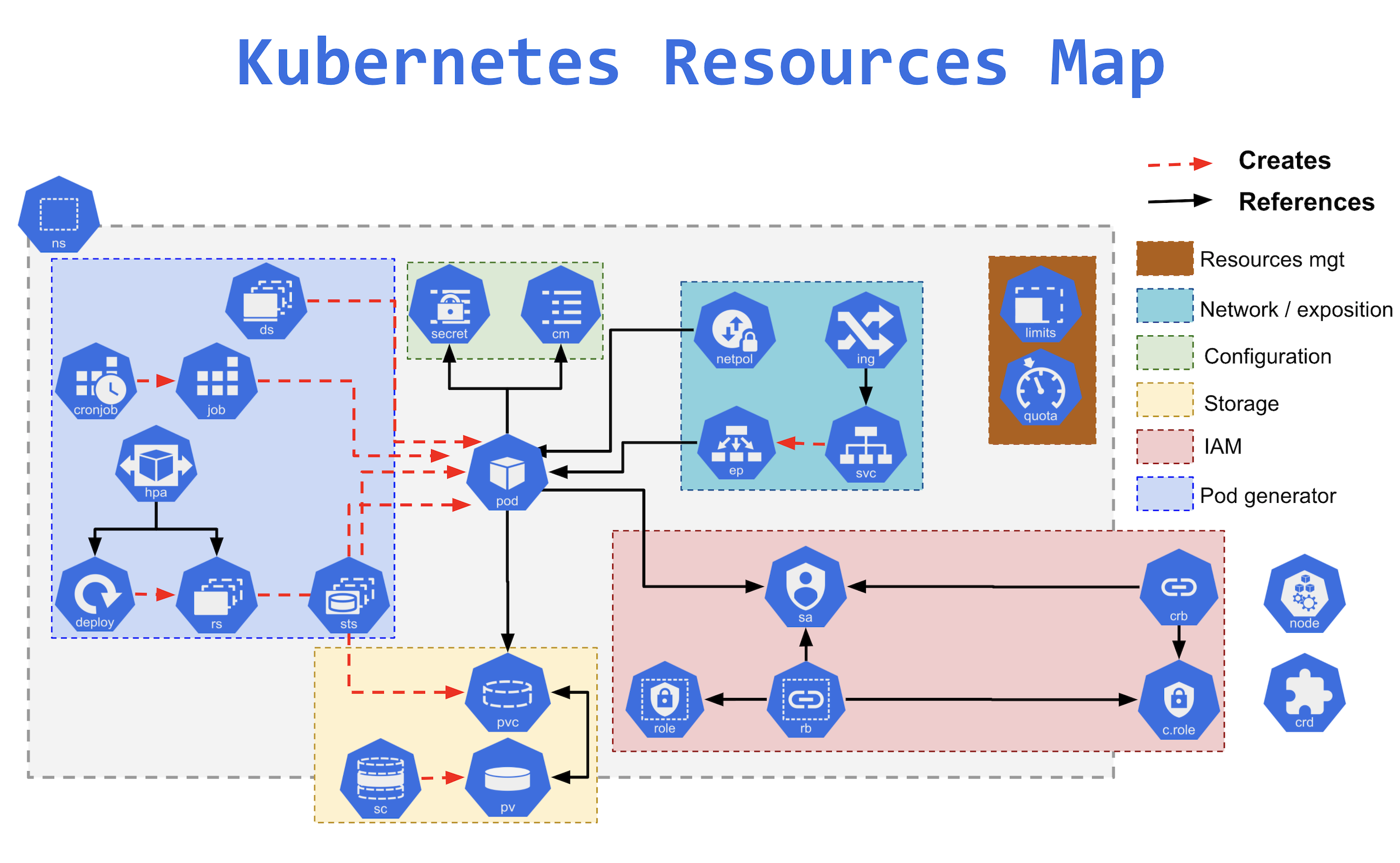
- Kubernetes Resources
- Nodes manage and run pods; it’s the machine (whether virtualized or physical) that performs the given work.
- Namespaces
- provide a mechanism for isolating groups of resources within a single cluster.
- Kubernetes starts with four initial namespaces:
default– default namespace for objects with no other namespace.kube-system– namespace for objects created by the Kubernetes system.kube-public– namespace is created automatically and is readable by all users (including those not authenticated).kube-node-lease– namespace holds Lease objects associated with each node. Node leases allow the kubelet to send heartbeats so that the control plane can detect node failure.
- Resource Quotas can be defined for each namespace to limit the resources consumed.
- Resources within the namespaces can refer to each other with their service names.
- Pods
- is a group of containers and is the smallest unit that Kubernetes administers.
- Containers in a pod share the same resources such as memory and storage.
- ReplicaSet
- ensures a stable set of replica Pods running at any given time.
- helps guarantee the availability of a specified number of identical Pods.
- Deployments
- provide declarative updates for Pods and ReplicaSets.
- describe the number of desired identical pod replicas to run and the preferred update strategy used when updating the deployment.
- supports Rolling Update and Recreate update strategy.
- Services
- is an abstraction over the pods, and essentially, the only interface the various application consumers interact with.
- exposes a single machine name or IP address mapped to pods whose underlying names and numbers are unreliable.
- supports the following types
- ClusterIP
- NodePort
- Load Balancer
- Ingress
- exposes HTTP and HTTPS routes from outside the cluster to services within the cluster.
- DaemonSet
- ensures that all (or some) Nodes run a copy of a Pod.
- ensures pods are added to the newly created nodes and garbage collected as nodes are removed.
- StatefulSet
- is ideal for stateful applications using ReadWriteOnce volumes.
- designed to deploy stateful applications and clustered applications that save data to persistent storage, such as persistent disks.
- ConfigMaps
- helps to store non-confidential data in key-value pairs.
- can be consumed by pods as environment variables, command-line arguments, or configuration files in a volume.
- Secrets
- provides a container for sensitive data such as a password without putting the information in a Pod specification or a container image.
- are not encrypted but only base64 encoded.
- Job & ConJobs
- creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate.
- A CronJob creates Jobs on a repeating schedule.
- Volumes
- supports Persistent volumes that exist beyond the lifetime of a pod.
- When a pod ceases to exist, Kubernetes destroys ephemeral volumes; however, Kubernetes does not destroy persistent volumes.
- PersistentVolume (PV) is a cluster scoped piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes.
- PersistentVolumeClaim (PVC) is a request for storage by a user.
- Labels and Annotations attach metadata to objects in Kubernetes.
- Labels are identifying key/value pairs that can be attached to Kubernetes objects and are used in conjunction with selectors to identify groups of related resources.
- Annotations are key/value pairs designed to hold non-identifying information that can be leveraged by tools and libraries.
- Containers
- Container runtime is responsible for running containers (in Pods).
- Kubernetes supports any implementation of the Kubernetes Container Runtime Interface CRI specifications
- To run the containers, each worker node has a container runtime engine.
- It pulls images from a container image registry and starts and stops containers.
- Kubernetes supports several container runtimes:
Container Orchestration
- Container Orchestration Fundamentals
- Containers help manage the dependencies of an application and run much more efficiently than spinning up a lot of virtual machines.
- While virtual machines emulate a complete machine, including the operating system and a kernel, containers share the kernel of the host machine and are only isolated processes.
- Virtual machines come with some overhead, be it boot time, size or resource usage to run the operating system. Containers on the other hand are processes, like the browser, therefore they start a lot faster and have a smaller footprint.
- Runtime
- Container runtime is responsible for running containers (in Pods).
- Kubernetes supports any implementation of the Kubernetes Container Runtime Interface CRI specifications
- To run the containers, each worker node has a container runtime engine.
- It pulls images from a container image registry and starts and stops containers.
- Kubernetes supports several container runtimes:
- Docker – Standard for a long time but the usage of Docker as the runtime for Kubernetes has been deprecated and removed in Kubernetes 1.24
- contained – containerd is the most popular lightweight and performant implementation to run containers used by all major cloud providers for the Kubernetes As A Service products.
- CRI-O – CRI-O was created by Red Hat and with a similar code base closely related to podman and buildah.
- gvisor – Made by Google, provides an application kernel that sits between the containerized process and the host kernel.
- Kata Containers – A secure runtime that provides a lightweight virtual machine, but behaves like a container
- Security
- 4C’s of Cloud Native security are Cloud, Clusters, Containers, and Code.
- Containers are started on a machine and they always share the same kernel, which then becomes a risk for the whole system, if containers are allowed to call kernel functions like for example killing other processes or modifying the host network by creating routing rules.
- Kubernetes provides security features
- Authentication using Users & Certificates
- Certificates are the recommended way
- Service accounts can be used to provide bearer tokens to authenticate with Kubernetes API.
- Authorization using Node, ABAC, RBAC, Webhooks
- Role-based access control is the most secure and recommended authorization mechanism in Kubernetes.
- Admission Controller is an interceptor to the Kubernetes API server requests prior to persistence of the object, but after the request is authenticated and authorized.
- Security Context helps define privileges and access control settings for a Pod or Container that includes
- Service Mesh like Istio and Linkerd can help implement MTLS for intra-cluster pod-to-pod communication.
- Network Policies help specify how a pod is allowed to communicate with various network “entities” over the network.
- Kubernetes auditing provides a security-relevant, chronological set of records documenting the sequence of actions in a cluster for activities generated by users, by applications that use the Kubernetes API, and by the control plane itself.
- Authentication using Users & Certificates
- Networking
- Container Network Interface (CNI) is a standard that can be used to write or configure network plugins and makes it very easy to swap out different plugins in various container orchestration platforms.
- Kubernetes networking addresses four concerns:
- Containers within a Pod use networking to communicate via loopback.
- Cluster networking provides communication between different Pods.
- Service API helps expose an application running in Pods to be reachable from outside your cluster.
- Ingress provides extra functionality specifically for exposing HTTP applications, websites, and APIs.
- Gateway API is an add-on that provides an expressive, extensible, and role-oriented family of API kinds for modeling service networking.
- Services can also be used to publish services only for consumption inside the cluster.
- Service Mesh
- Service Mesh is a dedicated infrastructure layer added to the applications that allows you to transparently add capabilities without adding them to your own code.
- Service Mesh provides capabilities like service discovery, load balancing, failure recovery, metrics, and monitoring and complex operational requirements, like A/B testing, canary deployments, rate limiting, access control, encryption, and end-to-end authentication.
- Service mesh uses a proxy to intercept all your network traffic, allowing a broad set of application-aware features based on the configuration you set.
- Istio is an open source service mesh that layers transparently onto existing distributed applications.
- An Envoy proxy is deployed along with each service that you start in the cluster, or runs alongside services running on VMs.
- Istio provides
- Secure service-to-service communication in a cluster with TLS encryption, strong identity-based authentication and authorization
- Automatic load balancing for HTTP, gRPC, WebSocket, and TCP traffic
- Fine-grained control of traffic behavior with rich routing rules, retries, failovers, and fault injection
- A pluggable policy layer and configuration API supporting access controls, rate limits and quotas
- Automatic metrics, logs, and traces for all traffic within a cluster, including cluster ingress and egress
- Storage
- Container images are read-only and consist of different layers that include everything added during the build phase ensuring that a container from an image provides the same behavior and functionality.
- To allow writing files, a read-write layer is put on top of the container image when you start a container from an image.
- Container on-disk files are ephemeral and lost if the container crashes.
-
Container Storage Interface (CSI) provides a uniform and standardized interface that allows attaching different storage systems no matter if it’s cloud or on-premises storage.
- Kubernetes supports Persistent volumes that exist beyond the lifetime of a pod. When a pod ceases to exist, Kubernetes destroys ephemeral volumes; however, Kubernetes does not destroy persistent volumes.
- Persistent Volumes is supported using API resources
- PersistentVolume (PV)
- is a piece of storage in the cluster that has been provisioned by an administrator or dynamically provisioned using Storage Classes.
- is a cluster-level resource and not bound to a namespace
- are volume plugins like Volumes, but have a lifecycle independent of any individual pod that uses the PV.
- PersistentVolumeClaim (PVC)
- is a request for storage by a user.
- is similar to a Pod.
- Pods consume node resources and PVCs consume PV resources.
- Pods can request specific levels of resources (CPU and Memory).
- Claims can request specific size and access modes (e.g., they can be mounted ReadWriteOnce, ReadOnlyMany, or ReadWriteMany, see AccessModes).
- PersistentVolume (PV)
- Persistent Volumes can be provisioned
-
- Statically – where the cluster administrator creates the PVs which is available for use by cluster users
- Dynamically using StorageClasses where the cluster may try to dynamically provision a volume, especially for the PVC.
-
Cloud Native Architecture
- Cloud Native Architecture Fundamentals
- Cloud native architecture guides us to optimize the software for scalability, high availability, cost efficiency, reliability, security, and faster time-to-market by using a combination of cultural, technological, and architectural design patterns.
- Cloud native architecture includes containers, service meshes, microservices, immutable infrastructure, and declarative APIs.
- Cloud native techniques enable loosely coupled systems that are resilient, manageable, and observable.
- Microservices
- Microservices are small, independent applications with a clearly defined scope of functions and responsibilities.
- Microservices help break down an application into multiple decoupled applications, that communicate with each other in a network, which are more manageable.
- Microservices enable multiple teams to hold ownership of different functions of the application,
- Microservices also enable functions to be operated and scaled individually.
- Autoscaling
- Autoscaling pattern provides the ability to dynamically adjust the resources based on the current demand without the need to over or under provision the resources.
- Autoscaling can be performed using
- Horizontal scaling – Adds new compute resources which can be new copies of the application, Virtual Machines, or physical servers.
- Vertical scaling – Adds more resources to the existing underlying hardware.
- Serverless
- Serverless allows you to just focus on the code while the cloud provider takes care of the underlying resources required to execute the code.
- Most cloud providers provide this feature as Function as a Service (FaaS) like AWS Lambda, GCP Cloud Functions, etc.
- Serverless enables on-demand provisioning and scaling of the applications with a pay-as-you-use model.
- CloudEvents aims to standardize serverless and event-driven architectures on multiple platforms.
- It provides a specification of how event data should be structured.
- Events are the basis for scaling serverless workloads or triggering corresponding functions.
- Community and Governance
- Open source projects hosted and supported by the CNCF are categorized according to maturity and go through a sandbox and incubation stage before graduating.
- CNCF Technical Oversight Committee – TOC
- is responsible for defining and maintaining the technical vision, approving new projects, accepting feedback from the end-user committee, and defining common practices that should be implemented in CNCF projects.
- does not control the projects, but encourages them to be self-governing and community owned and practices the principle of “minimal viable governance”.
- CNCF Project Maturity Levels
- Sandbox Stage
- Entry point for early stage projects.
- Incubating Stage
- Project meeting the sandbox stage requirements plus full technical due diligence performed, including documentation, a healthy number of committers, contributions, clear versioning scheme, documented security processes, and at least one public reference implementation
- Graduation Stage
- Project meeting the incubation stage criteria plus committers from at least two organizations, well-defined project governance, and committer process, maintained Core Infrastructure Initiative Best Practices Badge, third party security audit, public list of project adopters, received a supermajority vote from the TOC.
- Sandbox Stage
- Personas
- SRE, Security, Cloud, DevOps, and Containers have opened up a lot of different Cloud Native roles
- Cloud Engineer & Architect
- DevOps Engineer
- Security Engineer
- DevSecOps Engineer
- Data Engineer
- Full-Stack Developer
- Site Reliability Engineer (SRE)
- Site Reliability Engineer – SRE
- Founded around 2003 by Google, SRE has become an important job for many organizations.
- SRE’s goal is to create and maintain software that is reliable and scalable.
- To measure performance and reliability, SREs use three main metrics:
- Service Level Objectives – SLO: Specify a target level for the reliability of your service.
- Service Level Indicators – SLI: A carefully defined quantitative measure of some aspect of the level of service that is provided
- Service Level Agreements – SLA: An explicit or implicit contract with your users that includes consequences of meeting (or missing) the SLOs they contain.
- Around these metrics, SREs might define an error budget. An error budget defines the amount (or time) of errors the application can have before actions are taken, like stopping deployments to production.
- SRE, Security, Cloud, DevOps, and Containers have opened up a lot of different Cloud Native roles
- Open Standards
- Open Standards help provide a standardized way to build, package, run, and ship modern software.
- Open standards covers
- Open Container Initiative (OCI) Spec: image, runtime, and distribution specification on how to run, build, and distribute containers
- Container Network Interface (CNI): A specification on how to implement networking for Containers.
- Container Runtime Interface (CRI): A specification on how to implement container runtimes in container orchestration systems.
- Container Storage Interface (CSI): A specification on how to implement storage in container orchestration systems.
- Service Mesh Interface (SMI): A specification on how to implement Service Meshes in container orchestration systems with a focus on Kubernetes.
- OCI provides open industry standards for container technologies and defines
- Image-spec defines how to build and package container images.
- Runtime-spec specifies the configuration, execution environment, and lifecycle of containers.
- Distribution-Spec, which provides a standard for the distribution of content in general and container images in particular.
Cloud Native Observability
- Telemetry & Observability
- Telemetry is the process of measuring and collecting data points and then transferring them to another system.
- Observability is the ability to understand the state of a system or application by examining its outputs, logs, and performance metrics.
- It’s a measure of how well the internal states of a system can be inferred from knowledge of its external outputs.
- Observability mainly consists of
- Logs: Interactions between data and the external world with messages from the application.
- Metrics: Quantitative measurements with numerical values describing service or component behavior over time
- Traces: Records the progression of the request while passing through multiple distributed systems.
- Trace consists of Spans, which can include information like start and finish time, name, tags, or a log message.
- Traces can be stored and analyzed in a tracing system like Jaeger.
- OpenTelemetry
- is a set of APIs, SDKs, and tools that can be used to integrate telemetry such as metrics, and protocols, but especially traces into applications and infrastructures.
- OpenTelemetry clients can be used to export telemetry data in a standardized format to central platforms like Jaeger.
- Prometheus
- Prometheus is a popular, open-source monitoring system.
- Prometheus can collect metrics that were emitted by applications and servers as time series data
- Prometheus data model provides four core metrics:
- Counter: A value that increases, like a request or error count
- Gauge: Values that increase or decrease, like memory size
- Histogram: A sample of observations, like request duration or response size
- Summary: Similar to a histogram, but also provides the total count of observations.
- Prometheus provides PromQL (Prometheus Query Language) to query data stored in the Time Series Database (TSDB).
- Prometheus integrates with Grafana, which can be used to build visualization and dashboards from the collected metrics.
- Prometheus integrates with Alertmanager to configure alerts when certain metrics reach or pass a threshold.
- Cost Management
- All the Cloud providers work on the Pay-as-you-use model.
- Cost optimization can be performed by analyzing what is really needed, how long, and scaling dynamically as per the needs.
- Some of the cost optimization techniques include
- Right sizing the workloads and dynamically scaling as per the demand
- Identify wasted, unused resources and have proper archival techniques
- Using Reserved or Spot instances as per the workloads
- Defining proper budgets and alerts
Cloud Native Application Delivery
- Application Delivery Fundamentals
- Application delivery includes the application lifecycle right from source code, versioning, building, testing, packaging, and deployments.
- The old process included a lot of error-prone manual steps and the constant fear that something would break.
- DevOps process includes both the developers and administrators and focuses on frequent, error-free, repeatable, rapid deployments.
- Version control systems like Git provide a decentralized system that can be used to track changes in the source code.
- CI/CD
- Continuous Integration/Continuous Delivery (CI/CD) provides very fast, more frequent, and higher quality software rollouts with automated builds, tests, code quality checks, and deployments.
- Continuous Integration focuses on building and testing the written code. High automation and usage of version control allow multiple developers and teams to work on the same code base.
- Continuous Delivery focuses on automated deployment of the pre-built software.
- CI/CD tools include Jenkins, Spinnaker, Gitlab, ArgoCD, etc.
- CI/CD can be performed using two different approaches
- Push-based
- The pipeline is started and runs tools that make the changes in the platform. Changes can be triggered by a commit or merge request.
- Pull-based
- An agent watches the git repository for changes and compares the definition in the repository with the actual running state.
- If changes are detected, the agent applies the changes to the infrastructure.
- Push-based
- Continuous Integration/Continuous Delivery (CI/CD) provides very fast, more frequent, and higher quality software rollouts with automated builds, tests, code quality checks, and deployments.
- GitOps
- Infrastructure as a Code with tools like Terraform provides complete automation with versioning and better controls increasing the quality and speed of providing infrastructure.
- GitOps takes the idea of Git as the single source of truth a step further and integrates the provisioning and change process of infrastructure with version control operations.
- GitOps frameworks that use the pull-based approach are Flux and ArgoCD.
- ArgoCD is implemented as a Kubernetes controller
- Flux is built with the GitOps Toolkit
KCNA General information and practices
- The exam can be taken online from anywhere.
- Make sure you have prepared your workspace well before the exams.
- Make sure you have a valid government-issued ID card as it would be checked.
- You are not allowed to have anything around you and no one should enter the room.
- The exam proctor will be watching you always, so refrain from doing any other activities. Your screen is also always shared.
All the Best …