AWS S3 Glacier
⚠️ Important Update: Amazon Glacier (Vault-Based Service) No Longer Accepts New Customers
As of December 15, 2025, the original standalone vault-based Amazon Glacier service stopped accepting new customers. Existing customers can continue using it normally with no requirement to migrate data.
Amazon Glacier (vault-based) is distinct from the S3 Glacier storage classes. The S3 Glacier storage classes (Instant Retrieval, Flexible Retrieval, Deep Archive) accessed via the Amazon S3 API remain fully available and are the recommended approach for new archival workloads.
Migration Options for Vault-Based Glacier Users:
- AWS Data Transfer from Glacier Vaults to S3 – AWS-provided solution for migrating vault archives to S3 buckets with Glacier storage classes
- S3 Glacier is a storage service optimized for archival, infrequently used data, or “cold data.”
- S3 Glacier is an extremely secure, durable, and low-cost storage service for data archiving and long-term backup.
- provides average annual durability of 99.999999999% (11 9’s) for an archive.
- redundantly stores data in multiple facilities and on multiple devices within each facility.
- synchronously stores the data across multiple facilities before returning SUCCESS on uploading archives, to enhance durability.
- performs regular, systematic data integrity checks and is built to be automatically self-healing.
- enables customers to offload the administrative burdens of operating and scaling storage to AWS, without having to worry about capacity planning, hardware provisioning, data replication, hardware failure detection, recovery, or time-consuming hardware migrations.
- offers a range of storage classes and patterns
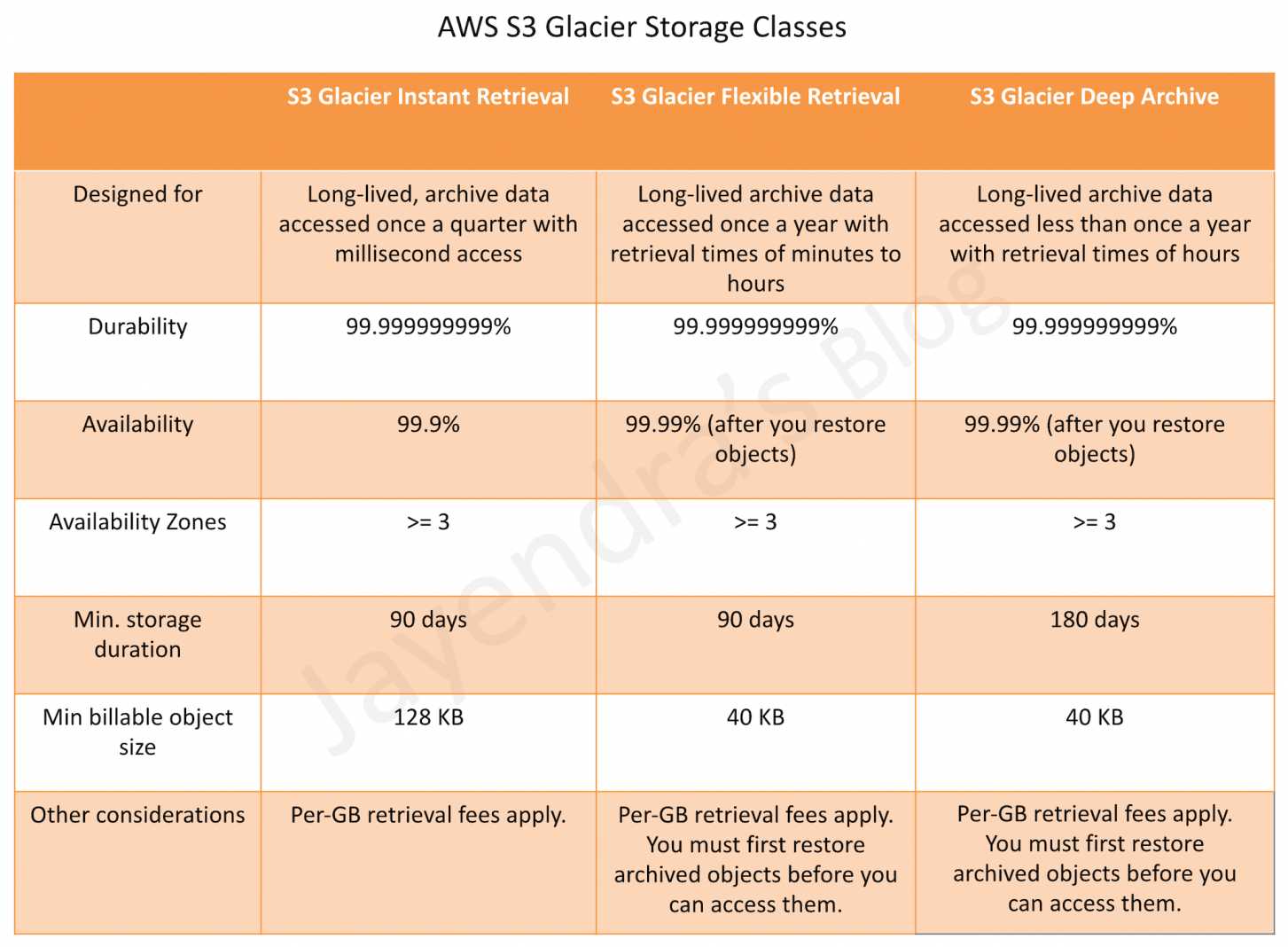
- S3 Glacier Instant Retrieval
- Use for archiving data that is rarely accessed and requires milliseconds retrieval.
- Minimum storage duration: 90 days
- Designed for 99.9% availability
- S3 Glacier Flexible Retrieval (formerly the S3 Glacier storage class)
- Use for archives where portions of the data might need to be retrieved in minutes.
- offers a range of data retrievals options where the retrieval time varies from minutes to hours.
- Expedited retrieval: 1-5 mins
- Standard retrieval: 3-5 hours
- Bulk retrieval: 5-12 hours (free)
- S3 Glacier Deep Archive
- Use for archiving data that rarely needs to be accessed.
- Retrieval options:
- Standard retrieval: within 12 hours
- Bulk retrieval: within 48 hours
- S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive objects are not available for real-time access.
- S3 Glacier Instant Retrieval
- is a great storage choice when low storage cost is paramount, with data rarely retrieved, and retrieval latency is acceptable. S3 should be used if applications require fast, frequent real-time access to the data.
- can store virtually any kind of data in any format.
- allows interaction through AWS Management Console, Command Line Interface CLI, and SDKs or REST-based APIs.
- AWS Management console can only be used to create and delete vaults.
- Rest of the operations to upload, download data, and create jobs for retrieval need CLI, SDK, or REST-based APIs.
- Use cases include
- Digital media archives
- Data that must be retained for regulatory compliance
- Financial and healthcare records
- Raw genomic sequence data
- Long-term database backups
S3 Glacier Storage Classes
S3 Glacier Instant Retrieval
- Use for archiving data that is rarely accessed and requires milliseconds retrieval.
- Delivers the same low latency and high throughput performance as the S3 Standard and S3 Standard-IA storage classes.
- Data has a minimum storage duration period of 90 days.
- Has a minimum object size of 128 KB.
- Designed for 99.999999999% (11 nines) of data durability and 99.9% availability by redundantly storing data across multiple physically separated AWS Availability Zones.
- Ideal for storing data like medical images, genomic sequences, satellite images, news media assets, and user-generated content that require milliseconds access but are accessed once per quarter.
S3 Glacier Flexible Retrieval (S3 Glacier Storage Class)
- Use for archives where portions of the data might need to be retrieved in minutes.
- Data has a minimum storage duration period of 90 days and can be accessed in as little as 1-5 minutes by using an expedited retrieval.
- You can request free Bulk retrievals in 5-12 hours.
- Requires 40 KB of additional metadata per object (32 KB charged at Glacier Flexible Retrieval rate + 8 KB charged at S3 Standard rate).
- S3 supports restore requests at a rate of up to 1,000 transactions per second, per AWS account.
- Faster Restores with S3 Batch Operations (2023): Standard tier retrievals using S3 Batch Operations are up to 85% faster at no additional cost. Restores begin returning objects within minutes.
S3 Glacier Deep Archive
- Use for archiving data that rarely needs to be accessed.
- S3 Glacier Deep Archive is the lowest cost storage option in AWS.
- Data stored has a minimum storage duration period of 180 days.
- Requires 40 KB of additional metadata per object (32 KB charged at Deep Archive rate + 8 KB charged at S3 Standard rate).
- Retrieval options:
- Standard retrieval: within 12 hours
- Bulk retrieval: within 48 hours
- Expedited retrieval is not available for Deep Archive.
- S3 supports restore requests at a rate of up to 1,000 transactions per second, per AWS account.
S3 Glacier vs. S3 Intelligent-Tiering Archive Access
- S3 Intelligent-Tiering includes optional Archive Access and Deep Archive Access tiers that provide automatic archival with no retrieval charges when data is accessed.
- S3 Intelligent-Tiering Archive Access tier has the same performance as S3 Glacier Flexible Retrieval.
- S3 Intelligent-Tiering Deep Archive Access tier has the same performance as S3 Glacier Deep Archive.
- Use S3 Intelligent-Tiering if access patterns are unknown or changing; use S3 Glacier storage classes for known archival workloads with defined retention.
S3 Glacier Flexible Data Retrievals Options
Glacier provides three options for retrieving data with varying access times and costs: Expedited, Standard, and Bulk retrievals.
Expedited Retrievals
- Expedited retrievals allow quick access to the data when occasional urgent requests for a subset of archives are required.
- Data accessed are typically made available within 1-5 minutes.
- There are two types of Expedited retrievals: On-Demand and Provisioned.
- On-Demand requests are like EC2 On-Demand instances and are available the vast majority of the time.
- Provisioned requests are guaranteed to be available when needed.
- Available for S3 Glacier Flexible Retrieval only (not available for Deep Archive).
Standard Retrievals
- Standard retrievals allow access to any of the archives within several hours.
- Standard retrievals typically complete within 3-5 hours for S3 Glacier Flexible Retrieval.
- Standard retrievals typically complete within 12 hours for S3 Glacier Deep Archive.
Bulk Retrievals
- Bulk retrievals are Glacier’s lowest-cost retrieval option, enabling retrieval of large amounts, even petabytes, of data inexpensively in a day.
- Bulk retrievals typically complete within 5-12 hours for S3 Glacier Flexible Retrieval (free of charge).
- Bulk retrievals typically complete within 48 hours for S3 Glacier Deep Archive.
S3 Batch Operations for Glacier Restores
- S3 Batch Operations can be used to restore large numbers of archived objects at scale with a few clicks in the S3 console or a single API request.
- 85% faster Standard tier restores (2023): S3 Glacier Flexible Retrieval Standard tier restores using S3 Batch Operations are up to 85% faster at no additional cost. Objects begin to be returned within minutes.
- S3 automatically optimizes Batch Operations restore jobs for fastest retrieval throughput (no need to manually optimize inventory reports with Athena as of July 2024).
- Supports restoring billions of objects containing petabytes of data.
- Supports on-demand manifest generation that filters objects based on prefix, suffix, and last modified date for targeted restores.
- 10x throughput improvement (2022): S3 Glacier restores now support up to 1,000 MB/s throughput when retrieving large volumes of archived data at no additional cost.
- Objects larger than 5 TB typically finish within 48 hours with up to 300 MB/s retrieval throughput.
S3 Glacier Data Model
- Glacier data model core concepts include vaults and archives and also include job and notification configuration resources
Vault
- A vault is a container for storing archives.
- Each vault resource has a unique address, which comprises the region the vault was created and the unique vault name within the region and account for e.g. https://glacier.us-west-2.amazonaws.com/111122223333/vaults/examplevault
- Vault allows the storage of an unlimited number of archives.
- Glacier supports various vault operations which are region-specific.
- An AWS account can create up to 1,000 vaults per region.
- Note: The vault-based Glacier service stopped accepting new customers on December 15, 2025. For new workloads, use S3 Glacier storage classes via the S3 API.
Archive
- An archive can be any data such as a photo, video, or document and is a base unit of storage in Glacier.
- Each archive has a unique ID and an optional description, which can only be specified during the upload of an archive.
- Glacier assigns the archive an ID, which is unique in the AWS region in which it is stored.
- An archive can be uploaded in a single request. While for large archives, Glacier provides a multipart upload API that enables uploading an archive in parts.
- An Archive can be up to 40TB.
Jobs
- A Job is required to retrieve an Archive and vault inventory list
- Data retrieval requests are asynchronous operations, are queued and some jobs can take about four hours to complete.
- A job is first initiated and then the output of the job is downloaded after the job is completed.
- Vault inventory jobs need the vault name.
- Data retrieval jobs need both the vault name and the archive id, with an optional description
- A vault can have multiple jobs in progress at any point in time and can be identified by Job ID, assigned when is it created for tracking
- Glacier maintains job information such as job type, description, creation date, completion date, and job status and can be queried
- After the job completes, the job output can be downloaded in full or partially by specifying a byte range.
Notification Configuration
- As the jobs are asynchronous, Glacier supports a notification mechanism to an SNS topic when the job completes
- SNS topic for notification can either be specified with each individual job request or with the vault
- Glacier stores the notification configuration as a JSON document
Glacier Supported Operations
Vault Operations
- Glacier provides operations to create and delete vaults.
- A vault can be deleted only if there are no archives in the vault as of the last computed inventory and there have been no writes to the vault since the last inventory (as the inventory is prepared periodically)
- Vault Inventory
- Vault inventory helps retrieve a list of archives in a vault with information such as archive ID, creation date, and size for each archive
- Inventory for each vault is prepared periodically, every 24 hours
- Vault inventory is updated approximately once a day, starting on the day the first archive is uploaded to the vault.
- When a vault inventory job is, Glacier returns the last inventory it generated, which is a point-in-time snapshot and not real-time data.
- Vault Metadata or Description can also be obtained for a specific vault or for all vaults in a region, which provides information such as
- creation date,
- number of archives in the vault,
- total size in bytes used by all the archives in the vault,
- and the date the vault inventory was generated
- S3 Glacier also provides operations to set, retrieve, and delete a notification configuration on the vault. Notifications can be used to identify vault events.
Archive Operations
- S3 Glacier provides operations to upload, download and delete archives.
- All archive operations must either be done using AWS CLI or SDK. It cannot be done using AWS Management Console.
- An existing archive cannot be updated, it has to be deleted and uploaded.
Archive Upload
- An archive can be uploaded in a single operation (1 byte to up to 4 GB in size) or in parts referred to as Multipart upload (40 TB)
- Multipart Upload helps to
- improve the upload experience for larger archives.
- upload archives in parts, independently, parallelly and in any order
- faster recovery by needing to upload only the part that failed upload and not the entire archive.
- upload archives without even knowing the size
- upload archives from 1 byte to about 40,000 GB (10,000 parts * 4 GB) in size
- To upload existing data to Glacier, consider using the following options:
- AWS DataSync – for online data transfers to AWS
- AWS Data Transfer Terminal – secure physical locations where you can bring storage devices for high-speed upload (100 GbE connections) to AWS, replacing the deprecated AWS Snowball Edge service for new customers
Note: AWS Snowball Edge is no longer available to new customers as of November 7, 2025. AWS Import/Export was the original predecessor service that was deprecated years ago. - Glacier returns a response that includes an archive ID that is unique in the region in which the archive is stored.
- Glacier does not support any additional metadata information apart from an optional description. Any additional metadata information required should be maintained on the client side.
✅ New (June 2026): S3 Annotations — For objects stored in S3 using Glacier storage classes, S3 Annotations now allows attaching up to 1GB of rich, queryable metadata (JSON, XML, YAML) per object without retrieving the object. Annotations can be added, modified, and queried (via Amazon Athena) independently of the object’s storage class, eliminating the need for external metadata management.
Archive Download
- Downloading an archive is an asynchronous operation and is the 2 step process
- Initiate an archive retrieval job
- When a Job is initiated, a job ID is returned as a part of the response.
- Job is executed asynchronously and the output can be downloaded after the job completes.
- A job can be initiated to download the entire archive or a portion of the archive.
- After the job completes, download the bytes
- An archive can be downloaded as all the bytes or a specific byte range to download only a portion of the output
- Downloading the archive in chunks helps in the event of a download failure, as only that part needs to be downloaded
- Job completion status can be checked by
- Check status explicitly (Not Recommended)
- periodically poll the describe job operation request to obtain job information
- Completion notification
- An SNS topic can be specified, when the job is initiated or with the vault, to be used to notify job completion
- Check status explicitly (Not Recommended)
- Initiate an archive retrieval job
About Range Retrievals
- S3 Glacier allows retrieving an archive either in whole (default) or a range, or a portion.
- Range retrievals need a range to be provided that is megabyte aligned.
- Glacier returns a checksum in the response which can be used to verify if any errors in the download by comparing it with the checksum computed on the client side.
- Specifying a range of bytes can be helpful when:
- Control bandwidth costs
- Glacier allows retrieval of up to 5 percent of the average monthly storage (pro-rated daily) for free each month
- Scheduling range retrievals can help in two ways.
- meet the monthly free allowance of 5 percent by spreading out the data requested
- if the amount of data retrieved doesn’t meet the free allowance percentage, scheduling range retrievals enable a reduction of the peak retrieval rate, which determines the retrieval fees.
- Manage your data downloads
- Glacier allows retrieved data to be downloaded for 24 hours after the retrieval request completes
- Only portions of the archive can be retrieved so that the schedule of downloads can be managed within the given download window.
- Retrieve a targeted part of a large archive
- Retrieving an archive in a range can be useful if an archive is uploaded as an aggregate of multiple individual files, and only a few files need to be retrieved
- Control bandwidth costs
Archive Deletion
- An archive can be deleted from the vault only one at a time
- This operation is idempotent. Deleting an already-deleted archive does not result in an error
- AWS applies a pro-rated charge for items that are deleted prior to the minimum storage duration (90 days for Glacier Flexible Retrieval, 180 days for Deep Archive), as it is meant for long-term storage
Archive Update
- An existing archive cannot be updated and must be deleted and re-uploaded, which would be assigned a new archive id
S3 Glacier Vault Lock
- S3 Glacier Vault Lock helps deploy and enforce compliance controls for individual S3 Glacier vaults with a vault lock policy.
- Specify controls such as “write once read many” (WORM) can be enforced using a vault lock policy and the policy can be locked for future edits.
- Once locked, the policy can no longer be changed.
- S3 Object Lock provides similar WORM protection for objects stored in S3 buckets (including those using S3 Glacier storage classes via lifecycle policies).
- S3 Object Lock supports both Governance mode (users with special permissions can override) and Compliance mode (no one can override, including root account).
- S3 Object Lock can be enabled on existing buckets (since November 2023).
- For new workloads, S3 Object Lock is the recommended approach for WORM compliance on S3 Glacier storage classes.
S3 Glacier Security
- S3 Glacier supports data in transit encryption using TLS (Transport Layer Security).
- All data is encrypted on the server side with Glacier handling key management and key protection. It uses AES-256, one of the strongest block ciphers available.
- S3 Glacier storage classes also support SSE-KMS and SSE-C encryption options when accessed through S3 API.
- Security and compliance of S3 Glacier are assessed by third-party auditors as part of multiple AWS compliance programs including SOC, HIPAA, PCI DSS, FedRAMP, etc.
S3 Glacier Select (Deprecated)
- S3 Glacier Select allowed running SQL queries directly against Glacier data without needing to restore the entire archive.
- Alternatives for querying archived data:
- Amazon Athena – serverless query service that can query data in S3 including restored archives
- S3 Object Lambda – transform data as it’s being retrieved
- Amazon EMR – simplified access to S3 Glacier for big data processing (2024 enhancement)
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- What is Amazon Glacier?
- You mean Amazon “Iceberg”: it’s a low-cost storage service.
- A security tool that allows to “freeze” an EBS volume and perform computer forensics on it.
- A low-cost storage service that provides secure and durable storage for data archiving and backup
- It’s a security tool that allows to “freeze” an EC2 instance and perform computer forensics on it.
- Amazon Glacier is designed for: (Choose 2 answers)
- Active database storage
- Infrequently accessed data
- Data archives
- Frequently accessed data
- Cached session data
- An organization is generating digital policy files which are required by the admins for verification. Once the files are verified they may not be required in the future unless there is some compliance issue. If the organization wants to save them in a cost effective way, which is the best possible solution?
- AWS RRS
- AWS S3
- AWS RDS
- AWS Glacier
- A user has moved an object to Glacier using the life cycle rules. The user requests to restore the archive after 6 months. When the restore request is completed the user accesses that archive. Which of the below mentioned statements is not true in this condition?
- The archive will be available as an object for the duration specified by the user during the restoration request
- The restored object’s storage class will be RRS (After the object is restored the storage class still remains GLACIER. Read more)
- The user can modify the restoration period only by issuing a new restore request with the updated period
- The user needs to pay storage for both RRS (restored) and Glacier (Archive) Rates
- To meet regulatory requirements, a pharmaceuticals company needs to archive data after a drug trial test is concluded. Each drug trial test may generate up to several thousands of files, with compressed file sizes ranging from 1 byte to 100MB. Once archived, data rarely needs to be restored, and on the rare occasion when restoration is needed, the company has 24 hours to restore specific files that match certain metadata. Searches must be possible by numeric file ID, drug name, participant names, date ranges, and other metadata. Which is the most cost-effective architectural approach that can meet the requirements?
- Store individual files in Amazon Glacier, using the file ID as the archive name. When restoring data, query the Amazon Glacier vault for files matching the search criteria. (Individual files are expensive and does not allow searching by participant names etc)
- Store individual files in Amazon S3, and store search metadata in an Amazon Relational Database Service (RDS) multi-AZ database. Create a lifecycle rule to move the data to Amazon Glacier after a certain number of days. When restoring data, query the Amazon RDS database for files matching the search criteria, and move the files matching the search criteria back to S3 Standard class. (As the data is not needed can be stored to Glacier directly and the data need not be moved back to S3 standard)
- Store individual files in Amazon Glacier, and store the search metadata in an Amazon RDS multi-AZ database. When restoring data, query the Amazon RDS database for files matching the search criteria, and retrieve the archive name that matches the file ID returned from the database query. (Individual files and Multi-AZ is expensive)
- First, compress and then concatenate all files for a completed drug trial test into a single Amazon Glacier archive. Store the associated byte ranges for the compressed files along with other search metadata in an Amazon RDS database with regular snapshotting. When restoring data, query the database for files that match the search criteria, and create restored files from the retrieved byte ranges.
- Store individual compressed files and search metadata in Amazon Simple Storage Service (S3). Create a lifecycle rule to move the data to Amazon Glacier, after a certain number of days. When restoring data, query the Amazon S3 bucket for files matching the search criteria, and retrieve the file to S3 reduced redundancy in order to move it back to S3 Standard class. (Once the data is moved from S3 to Glacier the metadata is lost, as Glacier does not have metadata and must be maintained externally)
- A user is uploading archives to Glacier. The user is trying to understand key Glacier resources. Which of the below mentioned options is not a Glacier resource?
- Notification configuration
- Archive ID
- Job
- Archive
- A company needs to archive 50TB of on-premises data to AWS for long-term retention. The data is rarely accessed but must be retrievable within 12 hours when needed. Which combination provides the MOST cost-effective solution? (Choose 2)
- Use AWS DataSync to transfer data to S3 Standard, then lifecycle to S3 Glacier Instant Retrieval
- Use AWS DataSync to transfer data to S3, then lifecycle to S3 Glacier Deep Archive
- Use S3 Batch Operations for restoring multiple archived objects at scale
- Use S3 Glacier Select to query archived data directly
- Use AWS Snowball Edge for the initial data transfer
(S3 Glacier Deep Archive provides 12-hour standard retrieval and is the lowest cost. S3 Batch Operations enables efficient large-scale restores. Glacier Select is deprecated for new customers. Snowball Edge is no longer available to new customers.)
- An organization wants to implement WORM (Write Once Read Many) protection for compliance on their archived data stored in S3 Glacier storage classes. Which approach should they use?
- S3 Glacier Vault Lock only
- S3 Object Lock in Compliance mode
- S3 bucket policy with deny delete
- IAM policy restricting delete operations
(For objects in S3 using Glacier storage classes (via lifecycle), S3 Object Lock in Compliance mode is the recommended approach. Vault Lock applies to the legacy vault-based Glacier service. Bucket policies and IAM policies can be modified by administrators.)