AWS Route 53 Routing Policy
AWS Route 53 routing policy determines how AWS would respond to the DNS queries and provides multiple routing policy options.
Simple Routing Policy
- Simple routing policy is a simple round-robin policy and can be applied when there is a single resource doing the function for the domain e.g. web server that serves content for the website.
- Simple routing helps configure standard DNS records, with no special Route 53 routing such as weighted or latency.
- Route 53 responds to the DNS queries based on the values in the resource record set e.g. IP address in an A record.
- Simple routing does not allow the creation of multiple records with the same name and type, but multiple values can be specified in the same record, such as multiple IP addresses.
- Route 53 displays all the values to resolve it recursively in random order and the resolver displays the values for the client. The client then chooses a value and resends the query.
- Simple routing policy does not support health checks, so the record would be returned to the client even if it is unhealthy.
- With Alias record enabled, only one AWS resource or one record can be specified in the current hosted zone.
- Simple routing can be used to create records in a private hosted zone.
Weighted Routing Policy
- Weighted routing policy helps route traffic to different resources in specified proportions (weights) e.g., 75% to one server and 25% to the other during a pilot release
- Weights can be assigned between any number from 0 to 255 inclusive.
- Weighted routing policy can be applied when there are multiple resources that perform the same function e.g., webservers serving the same site
- Weighted resource record sets allow associating multiple resources with a single DNS name.
- Weighted routing policy use cases include
- load balancing between regions
- A/B testing and piloting new versions of software
- To create a group of weighted resource record sets, two or more resource record sets can be created that has the same combination of DNS name and type, and each resource record set is assigned a unique identifier and a relative weight.
- When processing a DNS query, Route 53 searches for a resource record set or a group of resource record sets that have the specified name and type.
- Route 53 selects one from the group. The probability of any one resource record set being selected depends on its weight as a proportion of the total weight for all resource record sets in the group for e.g., suppose www.example.com has three resource record sets with weights of 1 (20%), 1 (20%), and 3 (60%)(sum = 5). On average, Route 53 selects each of the first two resource records sets one-fifth of the time and returns the third resource record set three-fifths of the time.
- Weighted routing policy supports health checks.
- Weighted routing can be used to create records in a private hosted zone.
Latency-based Routing (LBR) Policy
- Latency-based Routing Policy helps respond to the DNS query based on which data center gives the user the lowest network latency.
- Latency-based routing policy can be used when there are multiple resources performing the same function and Route 53 needs to be configured to respond to the DNS queries with the resources that provide the fastest response with the lowest latency.
- A latency resource record set can be created for the EC2 resource in each region that hosts the application. When Route 53 receives a query for the corresponding domain, it selects the latency resource record set for the EC2 region that gives the user the lowest latency. Route 53 then responds with the value associated with that resource record set for e.g., you might have web servers for example.com in the EC2 data centers in Ireland and in Tokyo. When a user browses example.com from Singapore, Route 53 will pick up the data center (Tokyo) which has the lowest latency from the user’s location
- Latency between hosts on the Internet can change over time as a result of changes in network connectivity and routing. Latency-based routing is based on latency measurements performed over a period of time, and the measurements reflect these changes for e.g. if the latency from the user in Singapore to Ireland improves, the user can be routed to Ireland
- Latency-based routing cannot guarantee users from the same geographic will be served from the same location for any compliance reason
- Latency resource record sets can be created using any record type that Route 53 supports except NS or SOA.
- Latency-based routing policy supports health checks.
- Latency-based routing can be used to create records in a private hosted zone.
Failover Routing Policy
- Failover routing policy allows active-passive failover configuration, in which one resource (primary) takes all traffic when it’s healthy and the other resource (secondary) takes all traffic when the first isn’t healthy.
- Route 53 health checking agents will monitor each location/endpoint of the application to determine its availability.
- Failover routing policy is applicable for Public hosted zones only.
- Failover routing can be used to create records in a private hosted zone.
Geolocation Routing Policy
- Geolocation routing policy helps respond to DNS queries based on the geographic location of the users i.e. location from which the DNS queries originate.
- Geolocation routing policy use cases include
- localization of content and presenting some or all of the website in the user’s language
- restrict distribution of content to only the locations in which you have distribution rights.
- balancing load across endpoints in a predictable, easy-to-manage way, so that each user location is consistently routed to the same endpoint.
- Geolocation routing policy allows geographic locations to be specified by continent, country, or by state (only in the US)
- Geolocation record sets, if created, for overlapping geographic regions for e.g. continent, and then for the country within the same continent, priority goes to the smallest geographic region, which allows some queries for a continent to be routed to one resource and queries for selected countries on that continent to a different resource
- Geolocation works by mapping IP addresses to locations, which might not be mapped to an exact geographic location.
- A default resource record set can be created to handle these queries and also the ones which do not have an explicit record set created.
- Route 53 returns a “no answer” response for queries from those locations if a default resource record set is not created.
- Two geolocation resource record sets that specify the same geographic location cannot be created.
- Route 53 supports the edns-client-subnet extension of EDNS0 (EDNS0 adds several optional extensions to the DNS protocol.) to improve the accuracy of geolocation routing.
- Geolocation routing can be used to create records in a private hosted zone. For private hosted zones, Route 53 responds to DNS queries based on the AWS Region of the VPC that the query originated from.
Geoproximity Routing Policy
- Geoproximity routing helps route traffic to the resources based on the geographic location of the users and the resources.
- Geoproximity routing can be configured with a bias to optionally choose to route more traffic or less to a given resource. A bias expands or shrinks the size of the geographic region from which traffic is routed to a resource.
- A positive bias (1 to 99) increases the size of the geographic region, routing more traffic to the resource. A negative bias (-1 to -99) shrinks the region.
- Route 53 supports specifying the resource location using the AWS Region, AWS Local Zone group, or latitude and longitude coordinates.
- Geoproximity routing is now available as a standard routing policy for DNS records in both public and private hosted zones (expanded in January 2024), in addition to being available through Route 53 Traffic Flow.
- Route 53 Traffic flow supports geoproximity routing for AWS Local Zones (since October 2023), enabling reduced latency for end users connecting to applications in their nearest Local Zone.
- Geoproximity routing supports health checks.
IP-based Routing Policy
- IP-based routing (launched June 2022) allows fine-tuning DNS routing based on the source IP address of the DNS query, using user-IP-to-endpoint mappings.
- IP-based routing gives granular control to optimize performance or reduce network costs by uploading data to Route 53 in the form of client IP to location mappings.
- IP-based routing use cases include:
- Routing end users from certain ISPs to specific endpoints to optimize network transit costs or performance.
- Adding overrides to existing Route 53 routing types, such as geolocation routing, based on knowledge of clients’ physical locations.
- IP ranges are managed using CIDR collections and CIDR locations:
- CIDR block – An IP range in CIDR notation, e.g., 192.0.2.0/24 or 2001:DB8::/32
- CIDR location – A named list of CIDR blocks, e.g., example-isp-seattle = [192.0.2.0/24, 203.0.113.0/22]
- CIDR collection – A named collection of locations that can be reused across records
- For IPv4, CIDR blocks between 1 and 24 bits are supported. For IPv6, CIDR blocks between 1 and 48 bits are supported.
- For DNS queries with a CIDR longer than the one specified in the collection, Route 53 matches it to the shorter CIDR.
- A default (“*”) location can be used to handle queries that don’t match any specified CIDR block.
- IP-based routing cannot be used for records in a private hosted zone.
- IP-based routing supports health checks.
Multivalue Routing Policy
- Multivalue routing helps return multiple values, e.g. IP addresses for the web servers, in response to DNS queries.
- Multivalue routing also helps check the health of each resource, so only the values for healthy resources are returned.
- Route 53 responds to DNS queries with up to eight healthy records and gives different answers to different DNS resolvers.
- Multivalue answer routing is not a substitute for a load balancer, but the ability to return multiple health-checkable IP addresses is a way to use DNS to improve availability and load balancing.
- To route traffic approximately randomly to multiple resources, such as web servers, one multivalue answer record can be created for each resource and, optionally, associate a Route 53 health check with each record. If a web server becomes unavailable after the resolver caches a response, client software can try another IP address in the response.
- Multivalue answer routing can be used to create records in a private hosted zone.
Route 53 Traffic Flow
- Route 53 Traffic Flow helps easily manage traffic globally through a variety of routing types combined with DNS Failover in order to enable a variety of low-latency, fault-tolerant architectures.
- Traffic Flow provides a visual editor to easily manage how the end-users are routed to the application’s endpoints – whether in a single AWS region or distributed around the globe.
- Traffic Flow introduced a new enhanced visual editor (March 2025) with a clearer sidebar-based configuration, undo/redo functionality, and a built-in JSON text editor for directly editing traffic policy documents in the browser.
- Traffic Flow routes traffic based on multiple criteria, such as endpoint health, geographic location, and latency.
- Traffic Flow’s versioning feature maintains a history of changes to the traffic policies to allow easy rollback to the previous version.
- Traffic Flow supports geoproximity routing for AWS Local Zones.
Route 53 Routing Policies in Private Hosted Zones
- Route 53 supports the following routing policies in private hosted zones:
- Simple routing
- Failover routing
- Multivalue answer routing
- Weighted routing
- Latency-based routing (supported since March 2022)
- Geolocation routing (supported since March 2022; routes based on the AWS Region of the VPC the query originates from)
- Geoproximity routing (supported since January 2024)
- IP-based routing is not supported in private hosted zones.
Route 53 Complex Routing Policies
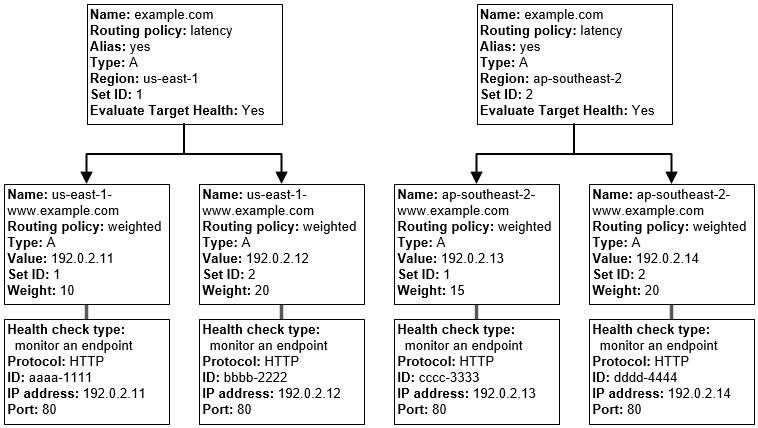
- Route 53 can be used to define more complex and nested routing policies
- A combination of alias records (such as weighted alias and failover alias) and non-alias records can be used to build a decision tree that gives you greater control over how Route 53 responds to requests.
- Resources would be created from the bottom of the tree
Route 53 Application Recovery Controller (ARC)
- Route 53 Application Recovery Controller (ARC) helps prepare for and quickly mitigate impairments for applications on AWS.
- ARC provides routing controls – simple on/off switches hosted on a highly available cluster – that can be used to control routing of client traffic in and out of application cells (regions or availability zones).
- Routing controls support failover across any AWS service that has a DNS endpoint.
- ARC supports:
- Zonal Shift – Temporarily move traffic away from an impaired Availability Zone
- Zonal Autoshift – Automatically shift traffic away from AZs with detected impairments
- Routing Control – Manually control traffic routing across regions with extreme reliability
- Safety rules can be configured to prevent simultaneous disabling of all routing controls, ensuring at least one region remains active.
- ARC routing control health checks integrate with Route 53 failover records to enable instant DNS-based failover.
Route 53 Accelerated Recovery
- Route 53 Accelerated Recovery (launched November 2025) provides a 60-minute recovery time objective (RTO) for regaining the ability to make DNS changes to public hosted zone records if AWS services in US East (N. Virginia) become unavailable.
- When enabled, Route 53 achieves built-in failover of the control plane to the Oregon Region (us-west-2).
- DNS resolution for existing records continues to function normally during any disruption; accelerated recovery specifically addresses the ability to make changes to DNS records.
- Accelerated recovery must be explicitly enabled per public hosted zone.
Route 53 Global Resolver
- Route 53 Global Resolver (GA March 2026) provides managed anycast DNS resolution for clients outside AWS VPCs, including on-premises data centers, branch offices, and remote locations.
- Global Resolver uses anycast IP addresses that automatically route DNS queries to the nearest AWS Region for optimal latency and availability.
- Key capabilities include:
- Resolution of public internet domains and private domains associated with Route 53 private hosted zones from any location
- DNS traffic filtering to prevent DNS-based data exfiltration
- Encrypted queries via DNS-over-HTTPS (DoH) and DNS-over-TLS (DoT)
- Centralized logging for compliance and security monitoring
- Multi-region deployment with automatic failover
- Available across 30+ AWS Regions with support for both IPv4 and IPv6 DNS query traffic.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- You have deployed a web application targeting a global audience across multiple AWS Regions under the domain name example.com. You decide to use Route 53 Latency-Based Routing to serve web requests to users from the region closest to the user. To provide business continuity in the event of server downtime you configure weighted record sets associated with two web servers in separate Availability Zones per region. During a DR test you notice that when you disable all web servers in one of the regions Route 53 does not automatically direct all users to the other region. What could be happening? (Choose 2 answers)
- Latency resource record sets cannot be used in combination with weighted resource record sets.
- You did not setup an http health check for one or more of the weighted resource record sets associated with the disabled web servers
- The value of the weight associated with the latency alias resource record set in the region with the disabled servers is higher than the weight for the other region.
- One of the two working web servers in the other region did not pass its HTTP health check
- You did not set “Evaluate Target Health” to “Yes” on the latency alias resource record set associated with example.com in the region where you disabled the servers.
- The compliance department within your multi-national organization requires that all data for your customers that reside in the European Union (EU) must not leave the EU and also data for customers that reside in the US must not leave the US without explicit authorization. What must you do to comply with this requirement for a web based profile management application running on EC2?
- Run EC2 instances in multiple AWS Availability Zones in single Region and leverage an Elastic Load Balancer with session stickiness to route traffic to the appropriate zone to create their profile (should be in 2 different regions – US and Europe)
- Run EC2 instances in multiple Regions and leverage Route 53’s Latency Based Routing capabilities to route traffic to the appropriate region to create their profile (Latency based routing policy would not guarantee the compliance requirement)
- Run EC2 instances in multiple Regions and leverage a third party data provider to determine if a user needs to be redirect to the appropriate region to create their profile
- Run EC2 instances in multiple AWS Availability Zones in a single Region and leverage a third party data provider to determine if a user needs to be redirect to the appropriate zone to create their profile(should be in 2 different regions – US and Europe)
- A US-based company is expanding their web presence into Europe. The company wants to extend their AWS infrastructure from Northern Virginia (us-east-1) into the Dublin (eu-west-1) region. Which of the following options would enable an equivalent experience for users on both continents?
- Use a public-facing load balancer per region to load-balance web traffic, and enable HTTP health checks.
- Use a public-facing load balancer per region to load-balance web traffic, and enable sticky sessions.
- Use Amazon Route 53, and apply a geolocation routing policy to distribute traffic across both regions
- Use Amazon Route 53, and apply a weighted routing policy to distribute traffic across both regions.
- You have been asked to propose a multi-region deployment of a web-facing application where a controlled portion of your traffic is being processed by an alternate region. Which configuration would achieve that goal?
- Route 53 record sets with weighted routing policy
- Route 53 record sets with latency based routing policy
- Auto Scaling with scheduled scaling actions set
- Elastic Load Balancing with health checks enabled
- Your company is moving towards tracking web page users with a small tracking image loaded on each page. Currently you are serving this image out of us-east, but are starting to get concerned about the time it takes to load the image for users on the west coast. What are the two best ways to speed up serving this image? Choose 2 answers
- Use Route 53’s Latency Based Routing and serve the image out of us-west-2 as well as us-east-1
- Serve the image out through CloudFront
- Serve the image out of S3 so that it isn’t being served of your web application tier
- Use EBS PIOPs to serve the image faster out of your EC2 instances
- Your API requires the ability to stay online during AWS regional failures. Your API does not store any state, it only aggregates data from other sources – you do not have a database. What is a simple but effective way to achieve this uptime goal?
- Use a CloudFront distribution to serve up your API. Even if the region your API is in goes down, the edge locations CloudFront uses will be fine.
- Use an ELB and a cross-zone ELB deployment to create redundancy across datacenters. Even if a region fails, the other AZ will stay online.
- Create a Route53 Weighted Round Robin record, and if one region goes down, have that region redirect to the other region.
- Create a Route53 Latency Based Routing Record with Failover and point it to two identical deployments of your stateless API in two different regions. Make sure both regions use Auto Scaling Groups behind ELBs. (Refer link)
- A company needs to route DNS traffic for their application based on the IP addresses of their clients. They want to optimize costs by routing traffic from a specific ISP to a particular endpoint. Which Route 53 routing policy should they use?
- Geolocation routing policy
- Latency-based routing policy
- IP-based routing policy
- Weighted routing policy
- A company uses Route 53 to manage DNS for their multi-region application. They want to ensure that during a regional AWS outage, they can still make DNS changes to their public hosted zone within 60 minutes. Which Route 53 feature should they enable?
- Route 53 Application Recovery Controller
- Route 53 Failover routing policy
- Route 53 Accelerated Recovery for public hosted zones
- Route 53 Global Resolver
- A company wants to route traffic to the geographically nearest resource and also wants to shift more traffic to a newly launched region by expanding its geographic catchment area. Which Route 53 routing policy should they use?
- Geolocation routing policy with a default record
- Latency-based routing policy
- Weighted routing policy with regional endpoints
- Geoproximity routing policy with a positive bias for the new region
- An organization with branch offices needs secure DNS resolution for both public domains and Route 53 private hosted zones from their on-premises locations. They require encrypted DNS queries and centralized logging. Which Route 53 feature best meets these requirements?
- Route 53 Resolver inbound endpoints with VPN
- Route 53 Profiles shared via AWS RAM
- Route 53 Global Resolver with DoH/DoT
- Route 53 Traffic Flow with failover
References