S3 Versioning helps to keep multiple variants of an object in the same bucket and can be used to preserve, retrieve, and restore every version of every object stored in the S3 bucket.
S3 Object Versioning can be used to protect from unintended overwrites and accidental deletions
As Versioning maintains multiple copies of the same objects as a whole and charges accrue for multiple versions for e.g. for a 1GB file with 5 copies with minor differences would consume 5GB of S3 storage space and you would be charged for the same.
Buckets can be in one of the three states
Unversioned (the default)
Versioning-enabled
Versioning-suspended
S3 Object Versioning is not enabled by default and has to be explicitly enabled for each bucket.
Versioning once enabled, cannot be disabled and can only be suspended
Versioning enabled on a bucket applies to all the objects within the bucket
Permissions are set at the version level. Each version has its own object owner; an AWS account that creates the object version is the owner. So, you can set different permissions for different versions of the same object.
Irrespective of the Versioning, each object in the bucket has a version.
For Non Versioned bucket, the version ID for each object is null
For Versioned buckets, a unique version ID is assigned to each object
With Versioning, version ID forms a key element to define the uniqueness of an object within a bucket along with the bucket name and object key
Object Retrieval
For Non Versioned bucket
An Object retrieval always returns the only object available.
For Versioned bucket
An object retrieval returns the Current latest object.
Non-Current objects can be retrieved by specifying the version ID.
Object Addition
For Non Versioned bucket
If an object with the same key is uploaded again it overwrites the object
For Versioned bucket
If an object with the same key is uploaded, the newly uploaded object becomes the current version and the previous object becomes the non-current version.
A non-current versioned object can be retrieved and restored hence protecting against accidental overwrites
Object Deletion
For Non Versioned bucket
An object is permanently deleted and cannot be recovered
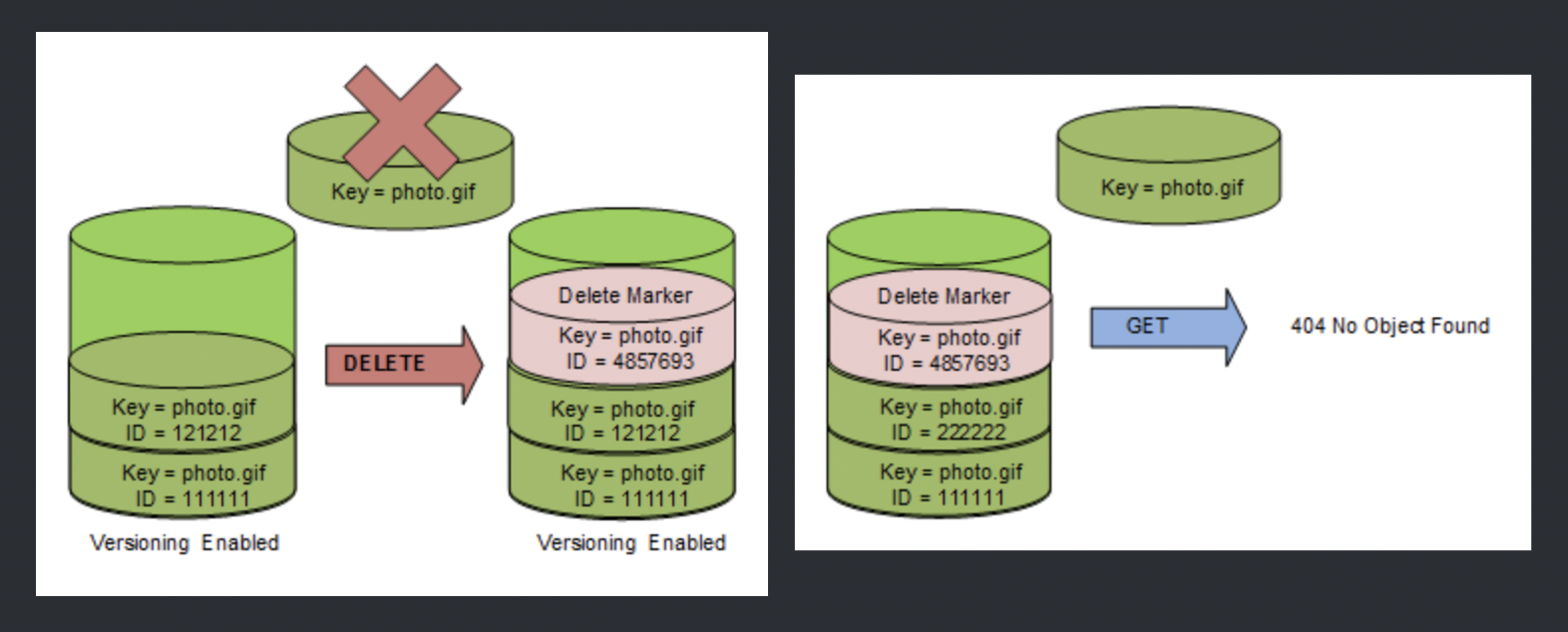
For the Versioned bucket,
All versions remain in the bucket and Amazon inserts a delete marker which becomes the Current version
A non-current versioned object can be retrieved and restored hence protecting against accidental overwrites
If an Object with a specific version ID is deleted, a permanent deletion happens and the object cannot be recovered
Delete marker
Delete Marker object does not have any data or ACL associated with it, just the key and the version ID
An object retrieval on a bucket with a delete marker as the Current version would return a 404
Only a DELETE operation is allowed on the Delete Marker object
If the Delete marker object is deleted by specifying its version ID, the previous non-current version object becomes the current version object
If a DELETE request is fired on an object with Delete Marker as the current version, the Delete marker object is not deleted but a Delete Marker is added again
Restoring Previous Versions
Copy a previous version of the object into the same bucket. The copied object becomes the current version of that object and all object versions are preserved – Recommended as it keeps all the versions.
Permanently delete the current version of the object. When you delete the current object version, you, in effect, turn the previous version into the current version of that object.
Versioning Suspended Bucket
Versioning can be suspended to stop accruing new versions of the same object in a bucket.
Existing objects in the bucket do not change and only future requests behavior changes.
An object with version ID null is added for each new object addition.
For each object addition with the same key name, the object with the version ID null is overwritten.
An object retrieval request will always return the current version of the object.
A DELETE request on the bucket would permanently delete the version ID null object and inserts a Delete Marker
A DELETE request does not delete anything if the bucket does not have an object with version ID null
A DELETE request can still be fired with a specific version ID for any previous object with version IDs stored
MFA Delete
Additional security can be enabled by configuring a bucket to enable MFA (Multi-Factor Authentication) for the deletion of objects.
MFA Delete enabled, requires additional authentication for operations
Changing the versioning state of the bucket
Permanently deleting an object version
MFA Delete can be enabled on a bucket to ensure that data in the bucket cannot be accidentally deleted
While the bucket owner, the AWS account that created the bucket (root account), and all authorized IAM users can enable versioning, but only the bucket owner (root account) can enable MFA Delete.
MFA Delete however does not prevent deletion or allow restoration.
MFA Delete cannot be enabled using the AWS Management Console. You must use the AWS Command Line Interface (AWS CLI) or the API.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Which set of Amazon S3 features helps to prevent and recover from accidental data loss?
Object lifecycle and service access logging
Object versioning and Multi-factor authentication
Access controls and server-side encryption
Website hosting and Amazon S3 policies
You use S3 to store critical data for your company Several users within your group currently have full permissions to your S3 buckets. You need to come up with a solution that does not impact your users and also protect against the accidental deletion of objects. Which two options will address this issue? Choose 2 answers
Enable versioning on your S3 Buckets
Configure your S3 Buckets with MFA delete
Create a Bucket policy and only allow read only permissions to all users at the bucket level
Enable object life cycle policies and configure the data older than 3 months to be archived in Glacier
To protect S3 data from both accidental deletion and accidental overwriting, you should
Amazon Simple Storage Service – S3 is a simple key, value object store designed for the Internet
provides unlimited storage space and works on the pay-as-you-use model. Service rates get cheaper as the usage volume increases
offers an extremely durable, highly available, and infinitely scalable data storage infrastructure at very low costs.
is Object-level storage (not Block level storage like EBS volumes) and cannot be used to host OS or dynamic websites.
S3 resources e.g. buckets and objects are private by default.
S3 Buckets & Objects
S3 Buckets
A bucket is a container for objects stored in S3
Buckets help organize the S3 namespace.
A bucket is owned by the AWS account that creates it and helps identify the account responsible for storage and data transfer charges.
Bucket names are globally unique, regardless of the AWS region in which it was created and the namespace is shared by all AWS accounts
Even though S3 is a global service, buckets are created within a region specified during the creation of the bucket.
Every object is contained in a bucket
There is no limit to the number of objects that can be stored in a bucket and no difference in performance whether a single bucket or multiple buckets are used to store all the objects
The S3 data model is a flat structure i.e. there are no hierarchies or folders within the buckets. However, logical hierarchy can be inferred using the key name prefix e.g. Folder1/Object1
Restrictions
100 buckets (soft limit) and a maximum of 1000 buckets can be created in each AWS account
Bucket names should be globally unique and DNS compliant
Bucket ownership is not transferable
Buckets cannot be nested and cannot have a bucket within another bucket
Bucket name and region cannot be changed, once created
Empty or a non-empty buckets can be deleted
S3 allows retrieval of 1000 objects and provides pagination support
Objects
Objects are the fundamental entities stored in a bucket
An object is uniquely identified within a bucket by a key name and version ID (if S3 versioning is enabled on the bucket)
Objects consist of object data, metadata, and others
Key is the object name and a unique identifier for an object
Value is actual content stored
Metadata is the data about the data and is a set of name-value pairs that describe the object e.g. content-type, size, last modified. Custom metadata can also be specified at the time the object is stored.
Version ID is the version id for the object and in combination with the key helps to uniquely identify an object within a bucket
Subresources help provide additional information for an object
Access Control Information helps control access to the objects
S3 objects allow two kinds of metadata
System metadata
Metadata such as the Last-Modified date is controlled by the system. Only S3 can modify the value.
System metadata that the user can control, e.g., the storage class, and encryption configured for the object.
User-defined metadata
User-defined metadata can be assigned during uploading the object or after the object has been uploaded.
User-defined metadata is stored with the object and is returned when an object is downloaded
S3 does not process user-defined metadata.
User-defined metadata must begin with the prefix “x-amz-meta“, otherwise S3 will not set the key-value pair as you define it
Object metadata cannot be modified after the object is uploaded and it can be only modified by performing copy operation and setting the metadata
Objects belonging to a bucket that reside in a specific AWS region never leave that region, unless explicitly copied using Cross Region Replication
Each object can be up to 5 TB in size
An object can be retrieved as a whole or a partially
With Versioning enabled, current as well as previous versions of an object can be retrieved
S3 Bucket & Object Operations
Listing
S3 allows the listing of all the keys within a bucket
A single listing request would return a max of 1000 object keys with pagination support using an indicator in the response to indicate if the response was truncated
Keys within a bucket can be listed using Prefix and Delimiter.
Prefix limits result in only those keys (kind of filtering) that begin with the specified prefix, and the delimiter causes the list to roll up all keys that share a common prefix into a single summary list result.
Retrieval
An object can be retrieved as a whole
An object can be retrieved in parts or partially (a specific range of bytes) by using the Range HTTP header.
Range HTTP header is helpful
if only a partial object is needed for e.g. multiple files were uploaded as a single archive
for fault-tolerant downloads where the network connectivity is poor
Objects can also be downloaded by sharing Pre-Signed URLs
Metadata of the object is returned in the response headers
Object Uploads
Single Operation – Objects of size 5GB can be uploaded in a single PUT operation
Multipart upload – can be used for objects of size > 5GB and supports the max size of 5TB. It is recommended for objects above size 100MB.
Pre-Signed URLs can also be used and shared for uploading objects
Objects if uploaded successfully can be verified if the request received a successful response. Additionally, returned ETag can be compared to the calculated MD5 value of the upload object
Copying Objects
Copying of objects up to 5GB can be performed using a single operation and multipart upload can be used for uploads up to 5TB
When an object is copied
user-controlled system metadata e.g. storage class and user-defined metadata are also copied.
system controlled metadata e.g. the creation date etc is reset
Copying Objects can be needed to
Create multiple object copies
Copy objects across locations or regions
Renaming of the objects
Change object metadata for e.g. storage class, encryption, etc
Updating any metadata for an object requires all the metadata fields to be specified again
Deleting Objects
S3 allows deletion of a single object or multiple objects (max 1000) in a single call
For Non Versioned buckets,
the object key needs to be provided and the object is permanently deleted
For Versioned buckets,
if an object key is provided, S3 inserts a delete marker and the previous current object becomes the non-current object
if an object key with a version ID is provided, the object is permanently deleted
if the version ID is of the delete marker, the delete marker is removed and the previous non-current version becomes the current version object
Deletion can be MFA enabled for adding extra security
Restoring Objects from Glacier
Objects must be restored before accessing an archived object
Restoration of an Object takes time and costs more. Glacier now offers expedited retrievals within minutes.
Restoration request also needs to specify the number of days for which the object copy needs to be maintained.
During this period, storage cost applies for both the archive and the copy.
Pre-Signed URLs
All buckets and objects are by default private.
Pre-signed URLs allows user to be able to download or upload a specific object without requiring AWS security credentials or permissions.
Pre-signed URL allows anyone to access the object identified in the URL, provided the creator of the URL has permission to access that object.
Pre-signed URLs creation requires the creator to provide security credentials, a bucket name, an object key, an HTTP method (GET for download object & PUT of uploading objects), and expiration date and time
Pre-signed URLs are valid only till the expiration date & time.
Multipart Upload
Multipart upload allows the user to upload a single large object as a set of parts. Each part is a contiguous portion of the object’s data.
Multipart uploads support 1 to 10000 parts and each part can be from 5MB to 5GB with the last part size allowed to be less than 5MB
Multipart uploads allow a max upload size of 5TB
Object parts can be uploaded independently and in any order. If transmission of any part fails, it can be retransmitted without affecting other parts.
After all parts of the object are uploaded and completed initiated, S3 assembles these parts and creates the object.
Using multipart upload provides the following advantages:
Improved throughput – parallel upload of parts to improve throughput
Quick recovery from any network issues – Smaller part size minimizes the impact of restarting a failed upload due to a network error.
Pause and resume object uploads – Object parts can be uploaded over time. Once a multipart upload is initiated there is no expiry; you must explicitly complete or abort the multipart upload.
Begin an upload before the final object size is known – an object can be uploaded as is it being created
Three Step process
Multipart Upload Initiation
Initiation of a Multipart upload request to S3 returns a unique ID for each multipart upload.
This ID needs to be provided for each part upload, completion or abort request and listing of parts call.
All the Object metadata required needs to be provided during the Initiation call
Parts Upload
Parts upload of objects can be performed using the unique upload ID
A part number (between 1 – 10000) needs to be specified with each request which identifies each part and its position in the object
If a part with the same part number is uploaded, the previous part would be overwritten
After the part upload is successful, S3 returns an ETag header in the response which must be recorded along with the part number to be provided during the multipart completion request
Multipart Upload Completion or Abort
On Multipart Upload Completion request, S3 creates an object by concatenating the parts in ascending order based on the part number and associates the metadata with the object
Multipart Upload Completion request should include the unique upload ID with all the parts and the ETag information
The response includes an ETag that uniquely identifies the combined object data
On Multipart upload Abort request, the upload is aborted and all parts are removed. Any new part upload would fail. However, any in-progress part upload is completed, and hence an abort request must be sent after all the parts uploads have been completed.
S3 should receive a multipart upload completion or abort request else it will not delete the parts and storage would be charged.
S3 Transfer Acceleration
S3 Transfer Acceleration enables fast, easy, and secure transfers of files over long distances between the client and a bucket.
Transfer Acceleration takes advantage of CloudFront’s globally distributed edge locations. As the data arrives at an edge location, data is routed to S3 over an optimized network path.
Transfer Acceleration will have additional charges while uploading data to S3 is free through the public Internet.
S3 Batch Operations
S3 Batch Operations help perform large-scale batch operations on S3 objects and can perform a single operation on lists of specified S3 objects.
A single job can perform a specified operation on billions of objects containing exabytes of data.
S3 tracks progress, sends notifications, and stores a detailed completion report of all actions, providing a fully managed, auditable, and serverless experience.
Batch Operations can be used with S3 Inventory to get the object list and use S3 Select to filter the objects.
Batch Operations can be used for copying objects, modify object metadata, applying ACLs, encrypting objects, transforming objects, invoke a custom lambda function, etc.
Virtual Hosted Style vs Path-Style Request
S3 allows the buckets and objects to be referred to in Path-style or Virtual hosted-style URLs
Path-style
Bucket name is not part of the domain (unless region specific endpoint used)
Endpoint used must match the region in which the bucket resides for e.g, if you have a bucket called mybucket that resides in the EU (Ireland) region with object named puppy.jpg, the correct path-style syntax URI is http://s3-eu-west-1.amazonaws.com/mybucket/puppy.jpg.
A “PermanentRedirect” error is received with an HTTP response code 301, and a message indicating what the correct URI is for the resource if a bucket is accessed outside the US East (N. Virginia) region with path-style syntax that uses either of the following:
http://s3.amazonaws.com
An endpoint for a region different from the one where the bucket resides for e.g., if you use http://s3-eu-west-1.amazonaws.com for a bucket that was created in the US West (N. California) region
Path-style requests would not be supported after after September 30, 2020
Virtual hosted-style
S3 supports virtual hosted-style and path-style access in all regions.
In a virtual-hosted-style URL, the bucket name is part of the domain name in the URL for e.g. http://bucketname.s3.amazonaws.com/objectname
S3 virtual hosting can be used to address a bucket in a REST API call by using the HTTP Host header
Benefits
attractiveness of customized URLs,
provides an ability to publish to the “root directory” of the bucket’s virtual server. This ability can be important because many existing applications search for files in this standard location.
S3 updates DNS to reroute the request to the correct location when a bucket is created in any region, which might take time.
S3 routes any virtual hosted-style requests to the US East (N.Virginia) region, by default, if the US East (N. Virginia) endpoint s3.amazonaws.com is used, instead of the region-specific endpoint (for e.g., s3-eu-west-1.amazonaws.com) and S3 redirects it with HTTP 307 redirect to the correct region.
When using virtual hosted-style buckets with SSL, the SSL wild card certificate only matches buckets that do not contain periods.To work around this, use HTTP or write your own certificate verification logic.
If you make a request to the http://bucket.s3.amazonaws.com endpoint, the DNS has sufficient information to route the request directly to the region where your bucket resides.
S3 Pricing
S3 costs vary by Region
Charges are incurred for
Storage – cost is per GB/month
Requests – per request cost varies depending on the request type GET, PUT
Data Transfer
data transfer-in is free
data transfer out is charged per GB/month (except in the same region or to Amazon CloudFront)
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
What are characteristics of Amazon S3? Choose 2 answers
Objects are directly accessible via a URL
S3 should be used to host a relational database
S3 allows you to store objects or virtually unlimited size
S3 allows you to store virtually unlimited amounts of data
S3 offers Provisioned IOPS
You are building an automated transcription service in which Amazon EC2 worker instances process an uploaded audio file and generate a text file. You must store both of these files in the same durable storage until the text file is retrieved. You do not know what the storage capacity requirements are. Which storage option is both cost-efficient and scalable?
Multiple Amazon EBS volume with snapshots
A single Amazon Glacier vault
A single Amazon S3 bucket
Multiple instance stores
A user wants to upload a complete folder to AWS S3 using the S3 Management console. How can the user perform this activity?
Just drag and drop the folder using the flash tool provided by S3
Use the Enable Enhanced Folder option from the S3 console while uploading objects
The user cannot upload the whole folder in one go with the S3 management console
Use the Enable Enhanced Uploader option from the S3 console while uploading objects (NOTE – Its no longer supported by AWS)
A media company produces new video files on-premises every day with a total size of around 100GB after compression. All files have a size of 1-2 GB and need to be uploaded to Amazon S3 every night in a fixed time window between 3am and 5am. Current upload takes almost 3 hours, although less than half of the available bandwidth is used. What step(s) would ensure that the file uploads are able to complete in the allotted time window?
Increase your network bandwidth to provide faster throughput to S3
Upload the files in parallel to S3 using mulipart upload
Pack all files into a single archive, upload it to S3, then extract the files in AWS
Use AWS Import/Export to transfer the video files
A company is deploying a two-tier, highly available web application to AWS. Which service provides durable storage for static content while utilizing lower Overall CPU resources for the web tier?
Amazon EBS volume
Amazon S3
Amazon EC2 instance store
Amazon RDS instance
You have an application running on an Amazon Elastic Compute Cloud instance, that uploads 5 GB video objects to Amazon Simple Storage Service (S3). Video uploads are taking longer than expected, resulting in poor application performance. Which method will help improve performance of your application?
Enable enhanced networking
Use Amazon S3 multipart upload
Leveraging Amazon CloudFront, use the HTTP POST method to reduce latency.
Use Amazon Elastic Block Store Provisioned IOPs and use an Amazon EBS-optimized instance
When you put objects in Amazon S3, what is the indication that an object was successfully stored?
Each S3 account has a special bucket named_s3_logs. Success codes are written to this bucket with a timestamp and checksum.
A success code is inserted into the S3 object metadata.
A HTTP 200 result code and MD5 checksum, taken together, indicate that the operation was successful.
Amazon S3 is engineered for 99.999999999% durability. Therefore there is no need to confirm that data was inserted.
You have private video content in S3 that you want to serve to subscribed users on the Internet. User IDs, credentials, and subscriptions are stored in an Amazon RDS database. Which configuration will allow you to securely serve private content to your users?
Generate pre-signed URLs for each user as they request access to protected S3 content
Create an IAM user for each subscribed user and assign the GetObject permission to each IAM user
Create an S3 bucket policy that limits access to your private content to only your subscribed users’ credentials
Create a CloudFront Origin Identity user for your subscribed users and assign the GetObject permission to this user
You run an ad-supported photo sharing website using S3 to serve photos to visitors of your site. At some point you find out that other sites have been linking to the photos on your site, causing loss to your business. What is an effective method to mitigate this?
Remove public read access and use signed URLs with expiry dates.
Use CloudFront distributions for static content.
Block the IPs of the offending websites in Security Groups.
Store photos on an EBS volume of the web server.
You are designing a web application that stores static assets in an Amazon Simple Storage Service (S3) bucket. You expect this bucket to immediately receive over 150 PUT requests per second. What should you do to ensure optimal performance?
Use multi-part upload.
Add a random prefix to the key names.
Amazon S3 will automatically manage performance at this scale. (With latest S3 performance improvements, S3 scaled automatically)
Use a predictable naming scheme, such as sequential numbers or date time sequences, in the key names
What is the maximum number of S3 buckets available per AWS Account?
Your customer needs to create an application to allow contractors to upload videos to Amazon Simple Storage Service (S3) so they can be transcoded into a different format. She creates AWS Identity and Access Management (IAM) users for her application developers, and in just one week, they have the application hosted on a fleet of Amazon Elastic Compute Cloud (EC2) instances. The attached IAM role is assigned to the instances. As expected, a contractor who authenticates to the application is given a pre-signed URL that points to the location for video upload. However, contractors are reporting that they cannot upload their videos. Which of the following are valid reasons for this behavior? Choose 2 answers { “Version”: “2012-10-17”, “Statement”: [ { “Effect”: “Allow”, “Action”: “s3:*”, “Resource”: “*” } ] }
The IAM role does not explicitly grant permission to upload the object. (The role has all permissions for all activities on S3)
The contractorsˈ accounts have not been granted “write” access to the S3 bucket. (using pre-signed urls the contractors account don’t need to have access but only the creator of the pre-signed urls)
The application is not using valid security credentials to generate the pre-signed URL.
The developers do not have access to upload objects to the S3 bucket. (developers are not uploading the objects but its using pre-signed urls)
The S3 bucket still has the associated default permissions. (does not matter as long as the user has permission to upload)