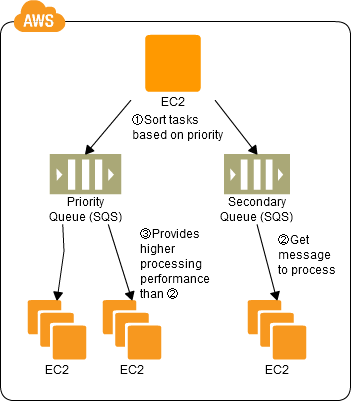
AWS SQS Standard vs FIFO Queue
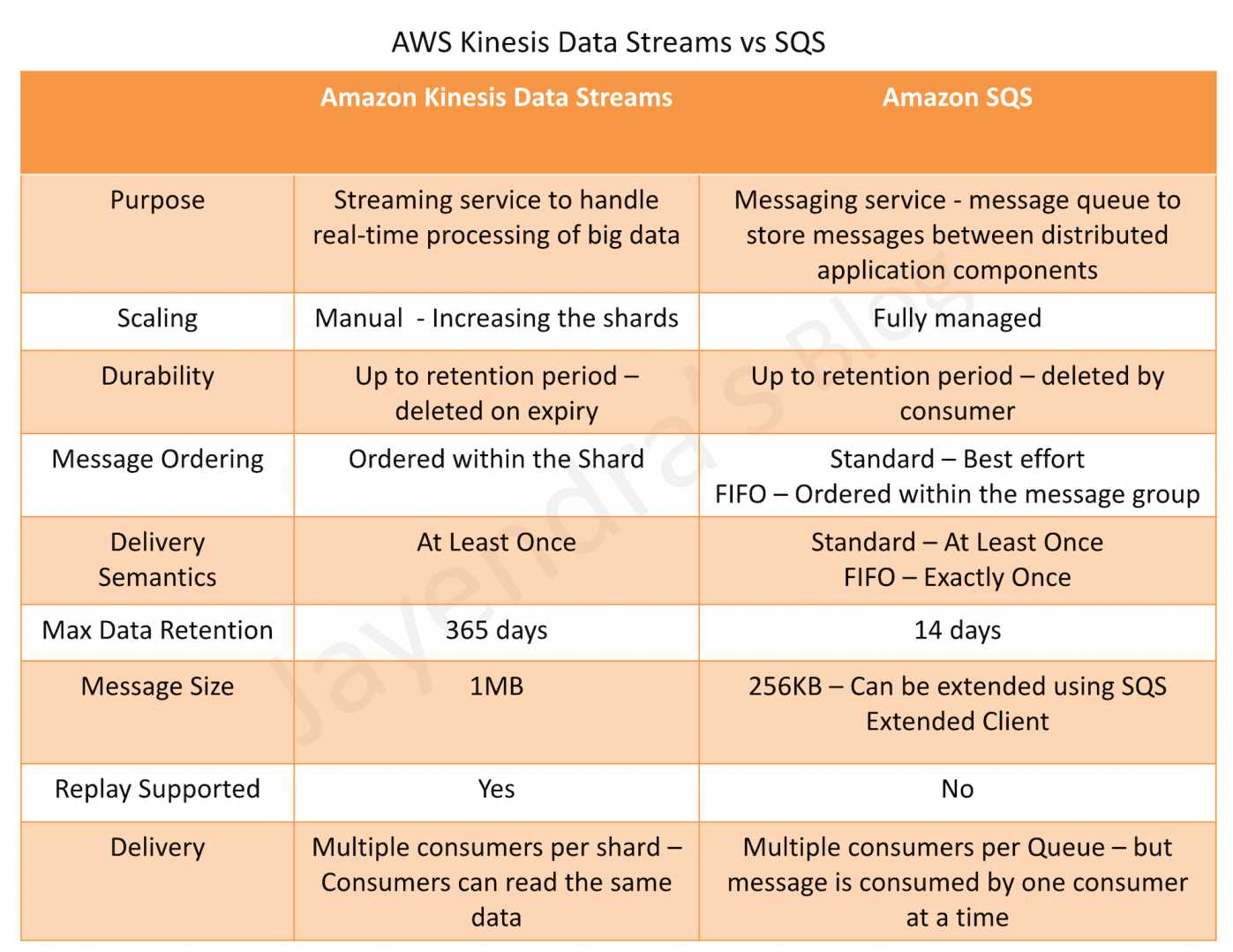
SQS offers two types of queues – Standard & FIFO queues
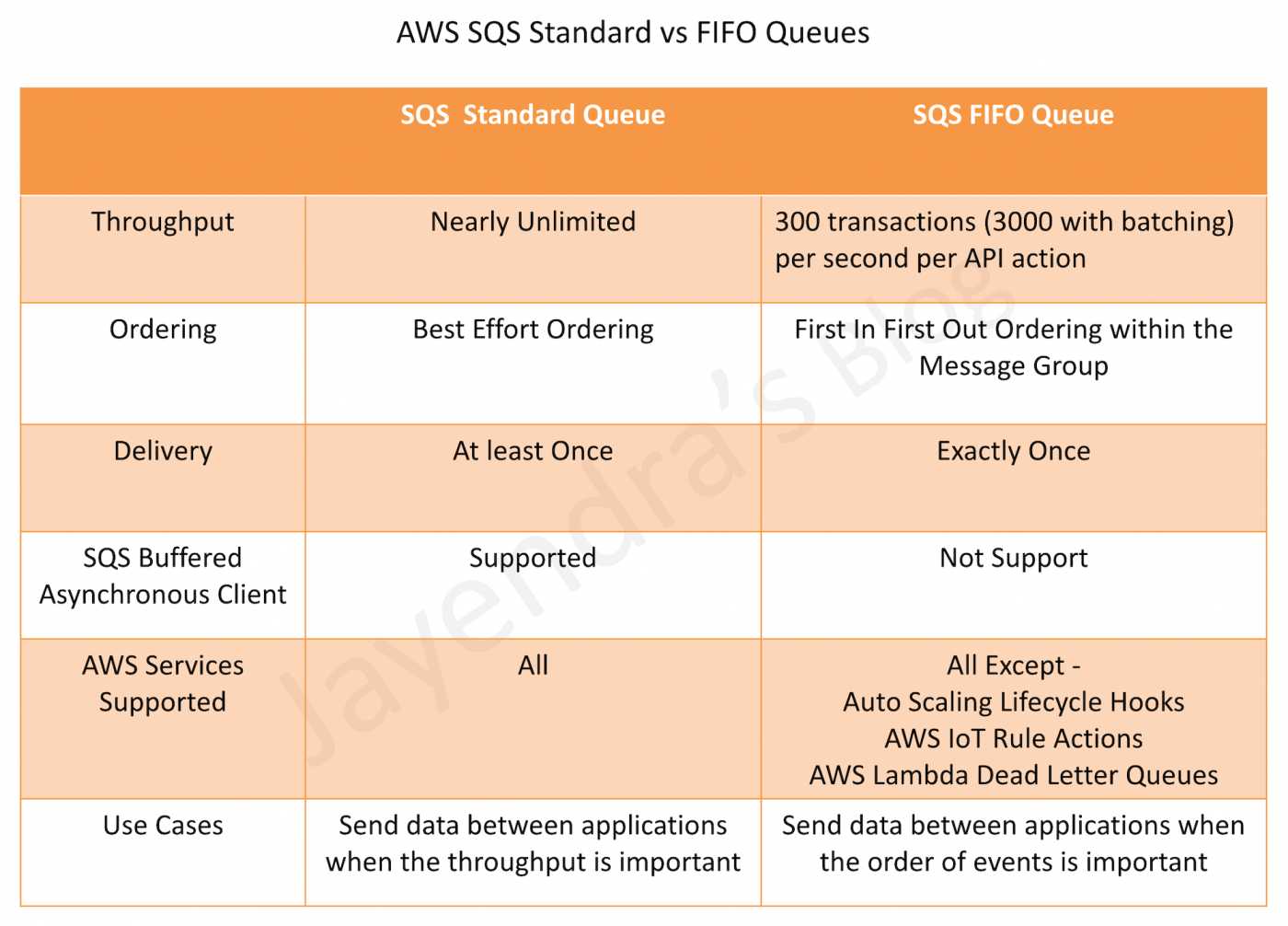
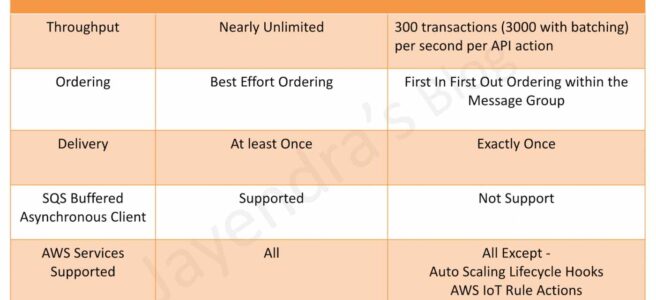
SQS Standard vs FIFO Queue Features
Message Order
- Standard queues provide best-effort ordering which ensures that messages are generally delivered in the same order as they are sent. Occasionally (because of the highly-distributed architecture that allows high throughput), more than one copy of a message might be delivered out of order
- FIFO queues offer first-in-first-out delivery and exactly-once processing: the order in which messages are sent and received is strictly preserved
Delivery
- Standard queues guarantee that a message is delivered at least once and duplicates can be introduced into the queue
- FIFO queues ensure a message is delivered exactly once and remains available until a consumer processes and deletes it; duplicates are not introduced into the queue
Transactions Per Second (TPS)
- Standard queues allow nearly-unlimited number of transactions per second
- FIFO queues are limited to 300 transactions per second per API action. It can be increased to 3000 using batching.
Regions
- Standard & FIFO queues are now available in all the regions
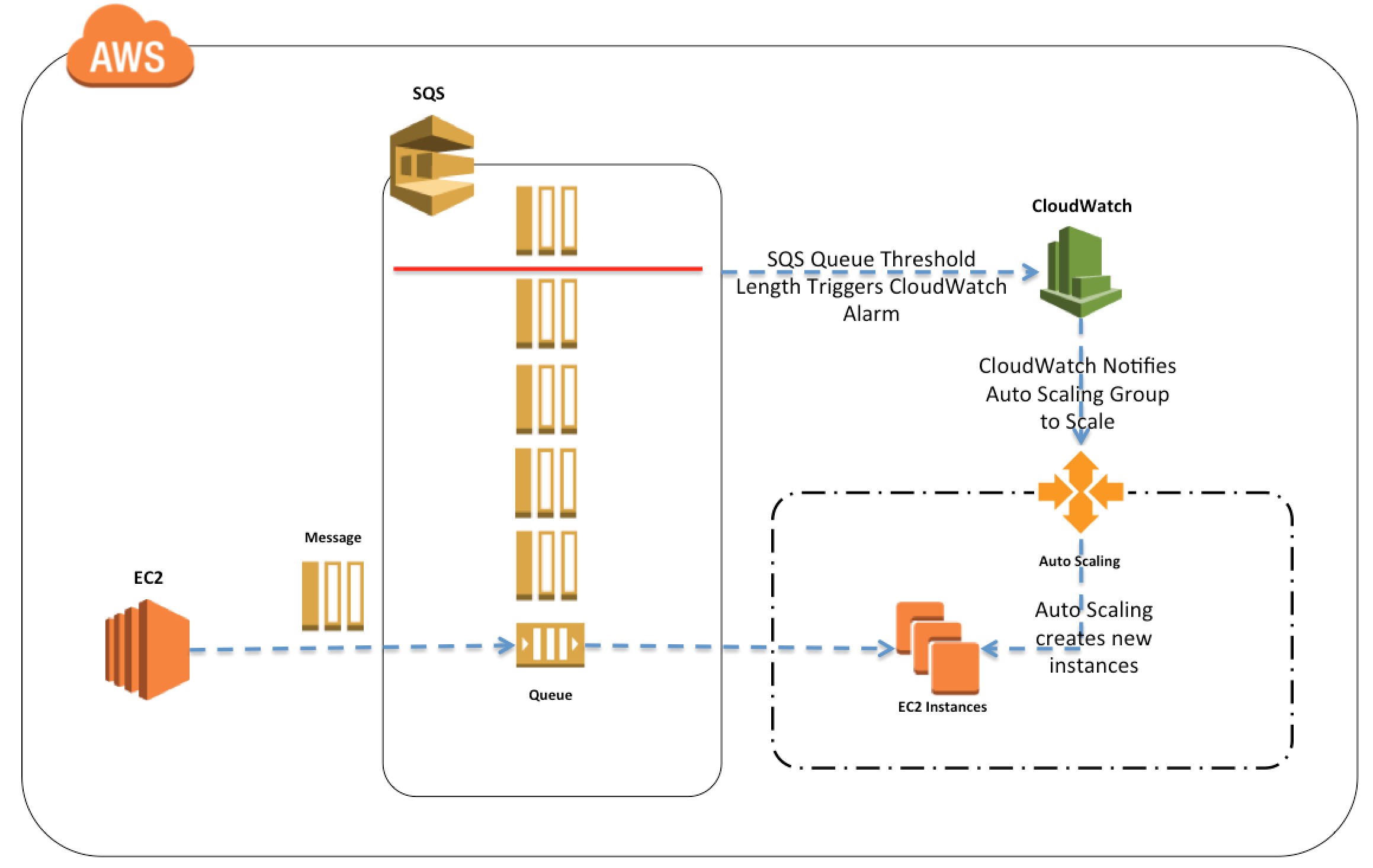
SQS Buffered Asynchronous Client
- FIFO queues aren’t currently compatible with the SQS Buffered Asynchronous Client, where messages are buffered at the client side and sent as a single request to the SQS queue to reduce cost.
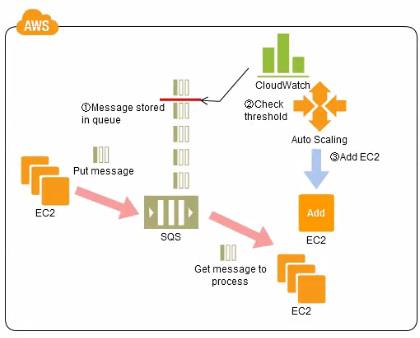
AWS Services Supported
- Standard Queues are supported by all AWS services
- FIFO Queues are currently not supported by all AWS services like
- CloudWatch Events
- S3 Event Notifications
- SNS Topic Subscriptions
- Auto Scaling Lifecycle Hooks
- AWS IoT Rule Actions
- AWS Lambda Dead Letter Queues
Use Cases
- Standard queues can be used in any scenario, as long as the application can process messages that arrive more than once and out of order
- Decouple live user requests from intensive background work: Let users upload media while resizing or encoding it.
- Allocate tasks to multiple worker nodes: Process a high number of credit card validation requests.
- Batch messages for future processing: Schedule multiple entries to be added to a database.
- FIFO queues are designed to enhance messaging between applications when the order of operations and events is critical, or where duplicates can’t be tolerated
- Ensure that user-entered commands are executed in the right order.
- Display the correct product price by sending price modifications in the right order.
- Prevent a student from enrolling in a course before registering for an account.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- A restaurant reservation application needs the ability to maintain a waiting list. When a customer tries to reserve a table, and none are available, the customer must be put on the waiting list, and the application must notify the customer when a table becomes free. What service should the Solutions Architect recommend ensuring that the system respects the order in which the customer requests are put onto the waiting list?
- Amazon SNS
- AWS Lambda with sequential dispatch
- A FIFO queue in Amazon SQS
- A standard queue in Amazon SQS
- A solutions architect is designing an application for a two-step order process. The first step is synchronous and must return to the user with little latency. The second step takes longer, so it will be implemented in a separate component. Orders must be processed exactly once and in the order in which they are received. How should the solutions architect integrate these components?
- Use Amazon SQS FIFO queues.
- Use an AWS Lambda function along with Amazon SQS standard queues.
- Create an SNS topic and subscribe an Amazon SQS FIFO queue to that topic.
- Create an SNS topic and subscribe an Amazon SQS Standard queue to that topic.