Kinesis acts as a highly available conduit to stream messages between data producers and data consumers.
Data producers can be almost any source of data: system or web log data, social network data, financial trading information, geospatial data, mobile app data, or telemetry from connected IoT devices.
Data consumers will typically fall into the category of data processing and storage applications such as Apache Hadoop, Apache Storm, S3, and ElasticSearch.
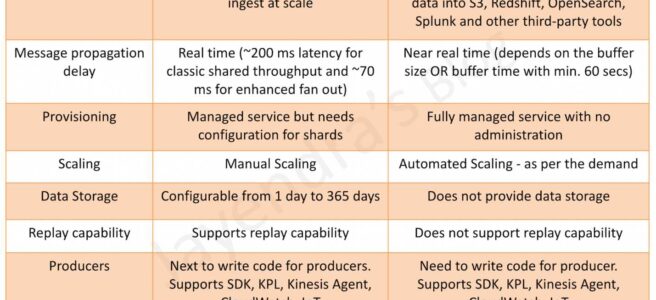
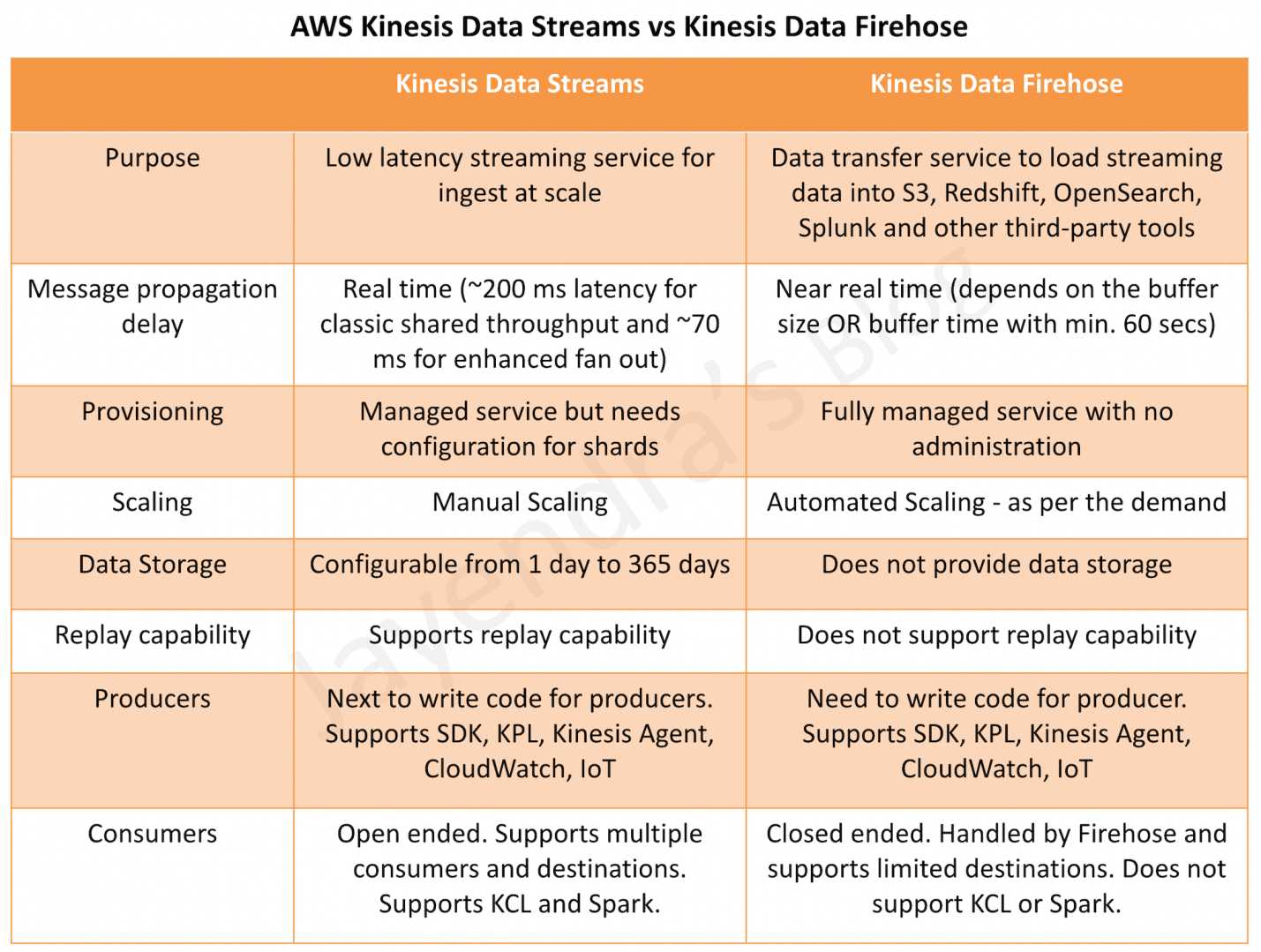
Purpose
Kinesis data streams is highly customizable and best suited for developers building custom applications or streaming data for specialized needs.
Kinesis Data Firehose handles loading data streams directly into AWS products for processing. Firehose also allows for streaming to S3, OpenSearch Service, or Redshift, where data can be copied for processing through additional services.
Provisioning & Scaling
Kinesis Data Streams needs you to configure shards, scale, and write your own custom applications for both producers and consumers. KDS requires manual scaling and provisioning.
Kinesis Data Firehose is fully managed and sends data to S3, Redshift, and OpenSearch. Scaling is handled automatically, up to gigabytes per second, and allows for batching, encrypting, and compressing.
Processing Delay
Kinesis Data Streams provides real-time processing with ~200 ms for shared throughput classic single consumer and ~70 ms for the enhanced fan-out consumer.
Kinesis Data Firehose provides near real-time processing with the lowest buffer time of 1 min.
Data Storage
Kinesis Data Streams provide data storage. Data typically is made available in a stream for 24 hours, but for an additional cost, users can gain data availability for up to 365 days.
Kinesis Data Firehose does not provide data storage.
Replay
Kinesis Data Streams supports replay capability
Kinesis Data Firehose does not support replay capability
Producers & Consumers
Kinesis Data Streams & Kinesis Data Firehose support multiple producer options including SDK, KPL, Kinesis Agent, IoT, etc.
Kinesis Data Streams support multiple consumers option including SDK, KCL, and Lambda, and can write data to multiple destinations. However, they have to be coded. Kinesis Data Firehose consumers are close-ended and support destinations like S3, Redshift, OpenSearch, and other third-party tools.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
Your organization needs to ingest a big data stream into its data lake on Amazon S3. The data may stream in at a rate of hundreds of megabytes per second. What AWS service will accomplish the goal with the least amount of management?
Amazon Kinesis Firehose
Amazon Kinesis Streams
Amazon CloudFront
Amazon SQS
Your organization is looking for a solution that can help the business with streaming data several services will require access to read and process the same stream concurrently. What AWS service meets the business requirements?
Amazon Kinesis Firehose
Amazon Kinesis Streams
Amazon CloudFront
Amazon SQS
Your application generates a 1 KB JSON payload that needs to be queued and delivered to EC2 instances for applications. At the end of the day, the application needs to replay the data for the past 24 hours. In the near future, you also need the ability for other multiple EC2 applications to consume the same stream concurrently. What is the best solution for this?
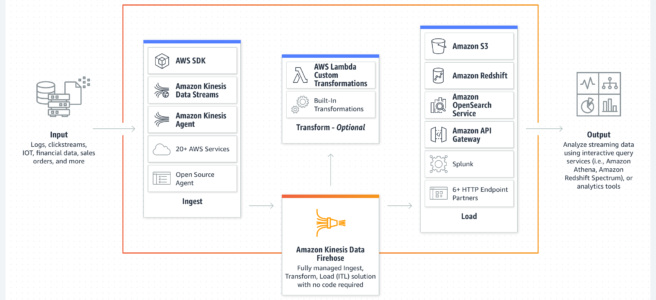
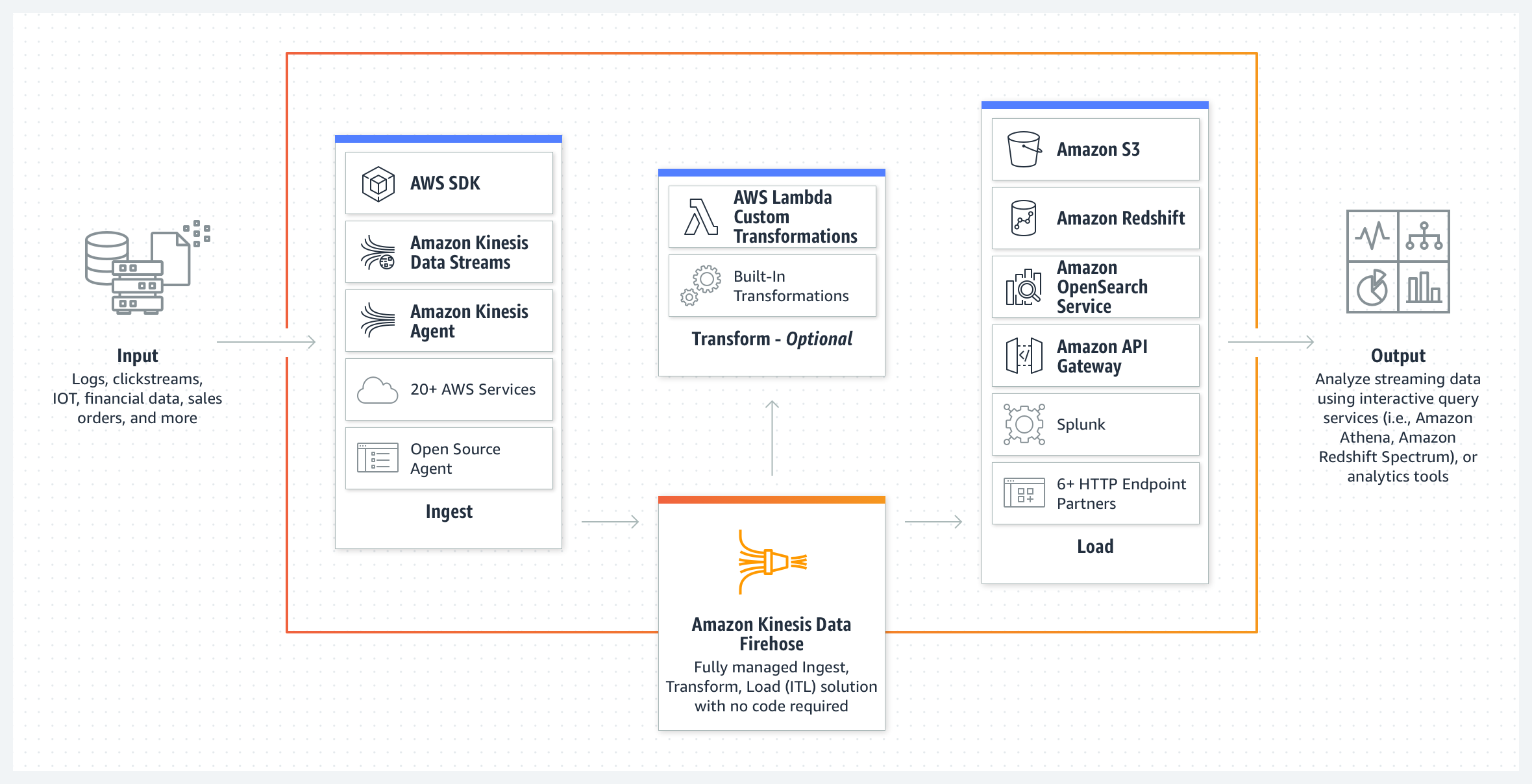
Amazon Kinesis Data Firehose is a fully managed service for delivering real-time streaming data
Kinesis Data Firehose automatically scales to match the throughput of the data and requires no ongoing administration or need to write applications or manage resources
is a data transfer solution for delivering real-time streaming data to destinations such as S3, Redshift, Elasticsearch service, and Splunk.
is NOT Real Time, but Near Real Timeas it supports batching and buffers streaming data to a certain size (Buffer Size in MBs) or for a certain period of time (Buffer Interval in seconds) before delivering it to destinations.
supports data compression, minimizing the amount of storage used at the destination. It currently supports GZIP, ZIP, and SNAPPY compression formats. Only GZIP is supported if the data is further loaded to Redshift.
supports data at rest encryption using KMS after the data is delivered to the S3 bucket.
supports multiple producers as datasource, which include Kinesis data stream, Kinesis Agent, or the Kinesis Data Firehose API using the AWS SDK, CloudWatch Logs, CloudWatch Events, or AWS IoT
supports out of box data transformation as well as custom transformation using the Lambda function to transform incoming source data and deliver the transformed data to destinations
supports source record backup with custom data transformation with Lambda, where Kinesis Data Firehose will deliver the un-transformed incoming data to a separate S3 bucket.
uses at least once semantics for data delivery. In rare circumstances such as request timeout upon data delivery attempt, delivery retry by Firehose could introduce duplicates if the previous request eventually goes through.
Underlying entity of Kinesis Data Firehose, where the data is sent
Record
Data sent by data producer to a Kinesis Data Firehose delivery stream
Maximum size of a record (before Base64-encoding) is 1024 KB.
Data producer
Producers send records to Kinesis Data Firehose delivery streams.
Buffer size and buffer interval
Kinesis Data Firehose buffers incoming streaming data to a certain size or for a certain time period before delivering it to destinations
Buffer size and buffer interval can be configured while creating the delivery stream
Buffer size is in MBs and ranges from 1MB to 128MB for the S3 destination and 1MB to 100MB for the OpenSearch Service destination.
Buffer interval is in seconds and ranges from 60 secs to 900 secs
Firehose raises buffer size dynamically to catch up and make sure that all data is delivered to the destination, if data delivery to the destination is falling behind data writing to the delivery stream
Buffer size is applied before compression.
Destination
A destination is the data store where the data will be delivered.
supports S3, Redshift, Elasticsearch, and Splunk as destinations.
A user is designing a new service that receives location updates from 3600 rental cars every hour. The cars location needs to be uploaded to an Amazon S3 bucket. Each location must also be checked for distance from the original rental location. Which services will process the updates and automatically scale?
Amazon EC2 and Amazon EBS
Amazon Kinesis Firehose and Amazon S3
Amazon ECS and Amazon RDS
Amazon S3 events and AWS Lambda
You need to perform ad-hoc SQL queries on massive amounts of well-structured data. Additional data comes in constantly at a high velocity, and you don’t want to have to manage the infrastructure processing it if possible. Which solution should you use?
Kinesis Firehose and RDS
EMR running Apache Spark
Kinesis Firehose and Redshift
EMR using Hive
Your organization needs to ingest a big data stream into their data lake on Amazon S3. The data may stream in at a rate of hundreds of megabytes per second. What AWS service will accomplish the goal with the least amount of management?
Amazon Kinesis Firehose
Amazon Kinesis Streams
Amazon CloudFront
Amazon SQS
A startup company is building an application to track the high scores for a popular video game. Their Solution Architect is tasked with designing a solution to allow real-time processing of scores from millions of players worldwide. Which AWS service should the Architect use to provide reliable data ingestion from the video game into the datastore?
AWS Data Pipeline
Amazon Kinesis Firehose
Amazon DynamoDB Streams
Amazon Elasticsearch Service
A company has an infrastructure that consists of machines which keep sending log information every 5 minutes. The number of these machines can run into thousands and it is required to ensure that the data can be analyzed at a later stage. Which of the following would help in fulfilling this requirement?
Use Kinesis Firehose with S3 to take the logs and store them in S3 for further processing.
Launch an Elastic Beanstalk application to take the processing job of the logs.
Launch an EC2 instance with enough EBS volumes to consume the logs which can be used for further processing.
Use CloudTrail to store all the logs which can be analyzed at a later stage.