AWS Glue
- AWS Glue is a fully-managed, ETL i.e extract, transform, and load service that automates the time-consuming steps of data preparation for analytics
- is serverless and supports pay-as-you-go model. There is no infrastructure to provision or manage.
- handles provisioning, configuration, and scaling of the resources required to run the ETL jobs on a fully managed, scale-out Apache Spark environment.
- makes it simple and cost-effective to categorize the data, clean it, enrich it, and move it reliably between various data stores and streams.
- also helps setup, orchestrate, and monitor complex data flows.
- help automate much of the undifferentiated heavy lifting involved with discovering, categorizing, cleaning, enriching, and moving data, so more time can be spent on analyzing the data.
- also supports custom Scala or Python code and import custom libraries and Jar files into the AWS Glue ETL jobs to access data sources not natively supported by AWS Glue.
- supports server side encryption for data at rest and SSL for data in motion.
- provides development endpoints to edit, debug, and test the code it generates.
- AWS Glue natively supports data stored in
- RDS (Aurora, MySQL, Oracle, PostgreSQL, SQL Server)
- Redshift
- DynamoDB
- S3
- MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases in the Virtual Private Cloud (VPC) running on EC2.
- Data streams from MSK, Kinesis Data Streams, and Apache Kafka.
- Glue ETL engine to Extract, Transform, and Load data that can automatically generate Scala or Python code.
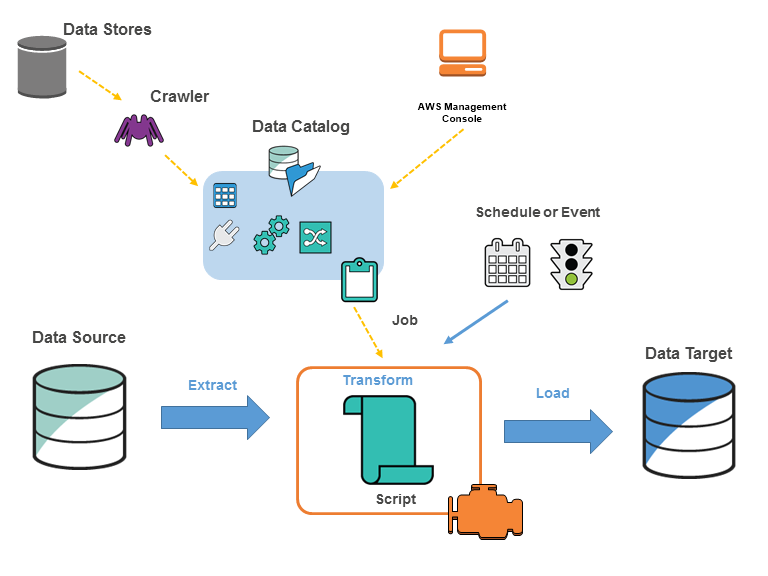
- Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
- Glue crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
- AWS Glue Streaming ETL enables performing ETL operations on streaming data using continuously-running jobs.
- Glue Flexible scheduler that handles dependency resolution, job monitoring, and retries.
- Glue Studio offers a graphical interface for authoring AWS Glue jobs to process data allowing you to define the flow of the data sources, transformations, and targets in the visual interface and generating Apache Spark code on your behalf.
- Glue Data Quality helps reduces manual data quality efforts by automatically measuring and monitoring the quality of data in data lakes and pipelines.
- Glue DataBrew is a visual data preparation tool that makes it easy for data analysts and data scientists to prepare data with an interactive, point-and-click visual interface without writing code. It helps to visualize, clean, and normalize data directly from the data lake, data warehouses, and databases, including S3, Redshift, Aurora, and RDS.
AWS Glue Data Catalog
- AWS Glue Data Catalog is a central repository and persistent metadata store to store structural and operational metadata for all the data assets.
- AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep track of data in data silos, and use that metadata to query and transform the data.
- For a given data set, Data Catalog can store its table definition, physical location, add business-relevant attributes, as well as track how this data has changed over time.
- Data Catalog is Apache Hive Metastore compatible and is a drop-in replacement for the Hive Metastore for Big Data applications running on EMR.
- Data Catalog also provides out-of-box integration with Athena, EMR, and Redshift Spectrum.
- Table definitions once added to the Glue Data Catalog, are available for ETL and also readily available for querying in Athena, EMR, and Redshift Spectrum to provide a common view of the data between these services.
- Data Catalog supports bulk import of the metadata from existing persistent Apache Hive Metastore by using our import script.
- Data Catalog provides comprehensive audit and governance capabilities, with schema change tracking and data access controls, which helps ensure that data is not inappropriately modified or inadvertently shared
- Each AWS account has one AWS Glue Data Catalog per region.
AWS Glue Crawlers
- AWS Glue crawler connects to a data store, progresses through a prioritized list of classifiers to extract the schema of the data and other statistics, and then populates the Data Catalog with this metadata.
- Glue crawlers scan various data stores to automatically infer schemas and partition structures to populate the Data Catalog with corresponding table definitions and statistics.
- Glue crawlers can be scheduled to run periodically so that the metadata is always up-to-date and in-sync with the underlying data.
- Crawlers automatically add new tables, new partitions to existing tables, and new versions of table definitions.
Dynamic Frames
- AWS Glue is designed to work with semi-structured data and introduces a dynamic frame component, which can be used in the ETL scripts.
- Dynamic frame is a distributed table that supports nested data such as structures and arrays.
- Each record is self-describing, designed for schema flexibility with semi-structured data. Each record contains both data and the schema that describes that data.
- A Dynamic Frame is similar to an Apache Spark dataframe, which is a data abstraction used to organize data into rows and columns, except that each record is self-describing so no schema is required initially.
- Dynamic frames provide schema flexibility and a set of advanced transformations specifically designed for dynamic frames.
- Conversion can be done between Dynamic frames and Spark dataframes, to take advantage of both AWS Glue and Spark transformations to do the kinds of analysis needed.
AWS Glue Streaming ETL
- AWS Glue enables performing ETL operations on streaming data using continuously-running jobs.
- AWS Glue streaming ETL is built on the Apache Spark Structured Streaming engine, and can ingest streams from Kinesis Data Streams and Apache Kafka using Amazon Managed Streaming for Apache Kafka.
- Streaming ETL can clean and transform streaming data and load it into S3 or JDBC data stores.
- Use Streaming ETL in AWS Glue to process event data like IoT streams, clickstreams, and network logs.
Glue Job Bookmark
- Glue Job Bookmark tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run.
- Job bookmarks help Glue maintain state information and prevent the reprocessing of old data.
- Job bookmarks help process new data when rerunning on a scheduled interval
- Job bookmark is composed of the states for various elements of jobs, such as sources, transformations, and targets. for e.g, an ETL job might read new partitions in an S3 file. Glue tracks which partition the job has processed successfully to prevent duplicate processing and duplicate data in the job’s target data store.
Glue Databrew
- Glue DataBrew is a visual data preparation tool that enables users to clean and normalize data without writing any code.
- is serverless, and can help explore and transform terabytes of raw data without needing to create clusters or manage any infrastructure.
- helps reduce the time it takes to prepare data for analytics and machine learning (ML).
- provides 250 ready-made transformations to automate data preparation tasks, such as filtering anomalies, converting data to standard formats, and correcting invalid values.
- business analysts, data scientists, and data engineers can more easily collaborate to get insights from raw data.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- An organization is setting up a data catalog and metadata management environment for their numerous data stores currently running on AWS. The data catalog will be used to determine the structure and other attributes of data in the data stores. The data stores are composed of Amazon RDS databases, Amazon Redshift, and CSV files residing on Amazon S3. The catalog should be populated on a scheduled basis, and minimal administration is required to manage the catalog. How can this be accomplished?
- Set up Amazon DynamoDB as the data catalog and run a scheduled AWS Lambda function that connects to data sources to populate the database.
- Use an Amazon database as the data catalog and run a scheduled AWS Lambda function that connects to data sources to populate the database.
- Use AWS Glue Data Catalog as the data catalog and schedule crawlers that connect to data sources to populate the database.
- Set up Apache Hive metastore on an Amazon EC2 instance and run a scheduled bash script that connects to data sources to populate the metastore.
Great work Jayendra.
Thanks Suresh