Best Practices for Using Amazon EMR
Amazon has made working with Hadoop a lot easier. You can launch an EMR cluster in minutes for big data processing, machine learning, and real-time stream processing with the Apache Hadoop ecosystem. You can use the Management Console or the command line to start several nodes with ease.
The EMR pricing has now changed from pay-per-hour to pay-per-second, which results in lower costs and you no longer have to worry about the hourly boundary.
EMR makes a whole bunch of the latest versions of open source software available to you. Currently, there are 19 open source projects and new releases are made every 4 to 6 weeks, so the latest versions of the open source projects are available. This is very useful, especially for rapidly evolving open source projects such as Apache Spark where each release contains critical bug fixes and features. However, you are not forced to upgrade; a new release is made available if you choose to use it. With EMR, you can spin up a bunch of instances and you could process massive volumes of data residing on S3 at a reasonable cost.
A variety of cluster management options are supported, including YARN. You can run the following:
- HBase
- Presto (low latency, distributed SQL engine)
- Spark
- Tez
- ganglia
- Zeppellin
- Notebooks
- SQL editors
AWS Connectors
Additionally, connectors to different AWS services are also available; for example, you can use Spark to load Redshift (using the Redshift connector, which Redshift commands under the hood to get a good throughput). You can access DynamoDB for analytics applications, Sqoop to access relational data, and so on.
AWS Glue
One particularly interesting connector is AWS Glue. AWS Glue comprises three main components:
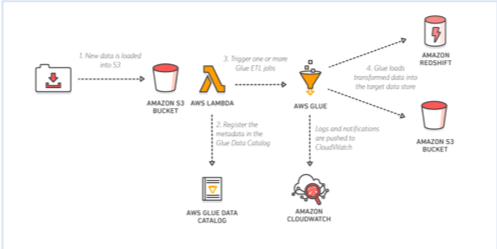
- ETL service: This lets you drag things around to create serverless ETL pipelines.
- AWS Glue Data Catalog: This is a fully managed Hive metastore-compliant service. Earlier, the systems ran an external Hive metastore database in RDS or Aurora. This was great. If you shut down your cluster, all your metadata was persisted so you didn’t have to recreate your tables with extra durability and availability (in case something happened to your metastore with MySQL on the master node). With Glue, all that is fully managed. You have an intelligent metastore—you don’t have to write DDL to create a table; you can just make Glue crawl your data, infer what the schema is, and create those tables for you. You can also make it add partitions, which can be painful otherwise—if you are constantly updating your Hive tables, you need a process to load that partition in—Glue catalog can do it for you. It also supports a variety of complex data types.
- Crawlers: The crawlers let you crawl the data to infer the schema.
AWS Glue is a managed service, so you spend less time monitoring. As a fully managed service, it is also responsible for replacing unhealthy nodes and autoscaling. Enabling security options in AWS Glue is pretty easy. It supports full customization and control, and you don’t have to waste time creating and configuring the cluster. In most cases, the default settings are good enough, but even if you wanted to change them or install custom components, you have root access over all the boxes, so you can make any changes you need.
Common EMR use cases
Using HBase for random access at a massive scale involves a lot of customers who are running HBase with HDFS. Now there is support for HBase using S3 object store for HFiles. Also, there is the ability to use the Read Replica HBase cluster in another AZ. Shifting to S3 can save you 50% or higher on storage costs. Instead of sizing the cluster for HDFS, they can now size it for the amount of processing power required for the HBase Region Servers. The S3 option is also good for load balancing and disaster recovery across AZs. As S3 is available across a region, you don’t have to replicate the data twice; that is, you don’t need two full HDFS clusters. Now you can set up a smaller cluster for the Read Replicas that point to the same HFiles and you can drive the read traffic through there.
Real-time and batch processing involves utilizing EMR; you can use Kinesis for pushing data to Spark. Use Spark Streaming for real-time analytics or processing data on-the-fly and then dump that data into S3. If you don’t have real-time processing use cases, then Kinesis Firehose is a great alternative too. The data can be cataloged in the Glue Data Catalog and then you can have the data accessible via a variety of different analytical engines. EMR supports several analytical engines including Hive, Tez, and Spark. Once the data is in the Data Catalog on S3, you can use Athena (serverless SQL queries), Glue ETL (serverless ETL), and Redshift Spectrum.
Data exploration with Spark using Zeppelin or Jupyter notebook allows you to arm your data scientists with a way to explore large amounts of data (instead of using one node, you can now spread the data across the cluster). This also makes it easier to move it to production.
There is a big rise in the use of Presto for ad hoc SQL queries (in combination with Athena). They approach the same thing from two different angles. Presto gives you advanced configurations and a way to build exactly what you need for your use case but you have to deal with the cluster management versus Athena where you just go to the console and start writing SQL. Now, many BI tools support Presto as well for supporting low latency dashboards. You can also perform traditional batch processing workloads using Spark.
Deep learning with GPU instances is where you can launch GPU hardware for EMR. There’s support for MxNet. You can do end-to-end data engineering work. Support for TensorFlow is coming.
Typical ML projects implement a multi-step process, including ETL, feature engineering, model training, model evaluation, model deployment, and model scoring and updates. Such pipelines need to support batch model training and real-time ML model serving. Using Apache Spark for implementing ML pipelines is very popular as it supports each step in an ML pipeline, scales for small and large jobs, good ML libraries, and has an active user base.
There are several options for deploying Spark on AWS. For example, you can use EC2 as it can support for batch/streaming, integrates with tooling, spin up/down clusters, larger/smaller clusters. Additionally, it also has support for different versions of Hadoop and Spark. However, using EC2 for Spark deployment places a huge management burden on us. Hence, EMR can be a simpler and better alternative here. It is simple to provision and you can use a wizard (and then generate the commands for the command line from it if required). You can create tags for cost management and send logs to S3.
Lowering EMR costs
If you are paying for Hadoop nodes that are not doing anything, then you are just burning money. There are ways you can batch up your workloads. Take an inventory of the jobs you have and tweak them to run in a batch mode and shutdown the cluster in-between those times. You can separate out clusters with auto-scaling instead of sizing and running it for all your workloads. You should shut down the cluster when you can, to stop paying for it unnecessarily. You can use Amazon Linux AMI with preinstalled customizations for faster cluster creation and use auto-scaling to minimize costs for long-running clusters.