AWS EMR – Elastic Map Reduce
- Amazon EMR – Elastic Map Reduce is a web service that utilizes a hosted Hadoop framework running on the web-scale infrastructure of EC2 and S3.
- enables businesses, researchers, data analysts, and developers to easily and cost-effectively process vast amounts of data.
- uses Apache Hadoop as its distributed data processing engine, which is an open-source, Java software that supports data-intensive distributed applications running on large clusters of commodity hardware
- provides data processing, interactive analysis, and machine learning using open-source frameworks such as Apache Spark, Hive, and Presto.
- is ideal for problems that necessitate fast and efficient processing of large amounts of data.
- helps focus on crunching, transforming, and analyzing data without having to worry about time-consuming set-up, the management, or tuning of Hadoop clusters, the compute capacity, or open-source applications.
- can help perform data-intensive tasks for applications such as web indexing, data mining, log file analysis, machine learning, financial analysis, scientific simulation, bioinformatics research, etc
- provides web service interface to launch the clusters and monitor processing-intensive computation on clusters.
- workloads can be deployed using EC2, Elastic Kubernetes Service (EKS), or on-premises AWS Outposts.
- seamlessly supports On-Demand, Spot, and Reserved Instances.
- EMR launches all nodes for a given cluster in the same AZ, which improves performance as it provides a higher data access rate.
- EMR supports different EC2 instance types including Standard, High CPU, High Memory, Cluster Compute, High I/O, and High Storage.
- EMR charges on hourly increments i.e. once the cluster is running, charges apply the entire hour.
- EMR integrates with CloudTrail to record AWS API calls
- EMR Serverless helps run big data frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters.
- EMR Studio is an IDE that helps data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark.
- EMR Notebooks provide a managed environment, based on Jupyter Notebook, that helps prepare and visualize data, collaborate with peers, build applications, and perform interactive analysis using EMR clusters.
EMR Architecture
- EMR uses industry-proven, fault-tolerant Hadoop software as its data processing engine.
- Hadoop is an open-source, Java software that supports data-intensive distributed applications running on large clusters of commodity hardware
- Hadoop splits the data into multiple subsets and assigns each subset to more than one EC2 instance. So, if an EC2 instance fails to process one subset of data, the results of another Amazon EC2 instance can be used.
- EMR consists of Master node, one or more Slave nodes
- Master Node Or Primary Node
- Master node or Primary node manages the cluster by running software components to coordinate the distribution of data and tasks among other nodes for processing.
- Primary node tracks the status of tasks and monitors the health of the cluster.
- Every cluster has a primary node, and it’s possible to create a single-node cluster with only the primary node.
- EMR currently does not support automatic failover of the master nodes or master node state recovery
- If master node goes down, the EMR cluster will be terminated and the job needs to be re-executed.
- Slave Nodes – Core nodes and Task nodes
- Core nodes
- with software components that host persistent data using Hadoop Distributed File System (HDFS) and run Hadoop tasks
- Multi-node clusters have at least one core node.
- can be increased in an existing cluster
- Task nodes
- only run Hadoop tasks and do not store data in HDFS.
- can be increased or decreased in an existing cluster.
- EMR is fault tolerant for slave failures and continues job execution if a slave node goes down.
- Currently, EMR does not automatically provision another node to take over failed slaves
- Core nodes
- Master Node Or Primary Node
- EMR supports Bootstrap actions which allow
- users a way to run custom set-up prior to the execution of the cluster.
- can be used to install software or configure instances before running the cluster
EMR Storage
- Hadoop Distributed File System (HDFS)
- HDFS is a distributed, scalable file system for Hadoop.
- HDFS distributes the data it stores across instances in the cluster, storing multiple copies of data on different instances to ensure that no data is lost if an individual instance fails.
- HDFS is ephemeral storage that is reclaimed when you terminate a cluster.
- HDFS is useful for caching intermediate results during MapReduce processing or for workloads that have significant random I/O.
- EMR File System – EMRFS
- EMR File System (EMRFS) helps extend Hadoop to add the ability to directly access data stored in S3 as if it were a file system like HDFS.
- You can use either HDFS or S3 as the file system in your cluster. Most often, S3 is used to store input and output data and intermediate results are stored in HDFS.
- Local file system
- Local file system refers to a locally connected EC2 pre-attached disk instance store storage.
- Data on instance store volumes persists only during the lifecycle of its Amazon EC2 instance.
- Storing data on S3 provides several benefits
- inherent features high availability, durability, lifecycle management, data encryption, and archival of data to Glacier
- cost-effective as storing data in S3 is cheaper as compared to HDFS with the replication factor
- ability to use Transient EMR cluster and shutdown the clusters after the job is completed, with data being maintained in S3
- ability to use Spot instances and not having to worry about losing the spot instances at any time.
- provides data durability from any HDFS node failures, where node failures exceed the HDFS replication factor
- data ingestion with high throughput data stream to S3 is much easier than ingesting to HDFS
EMR Security
- EMR cluster starts with different security groups for Master and Cluster nodes
- Master security group
- has a port open for communication with the service.
- has an SSH port open to allow direct SSH into the instances, using the key specified at the startup.
- Cluster security group
- only allows interaction with the master instance
- SSH to the slave nodes can be done by doing SSH to the master node and then to the slave node
- Security groups can be configured with different access rules
- Master security group
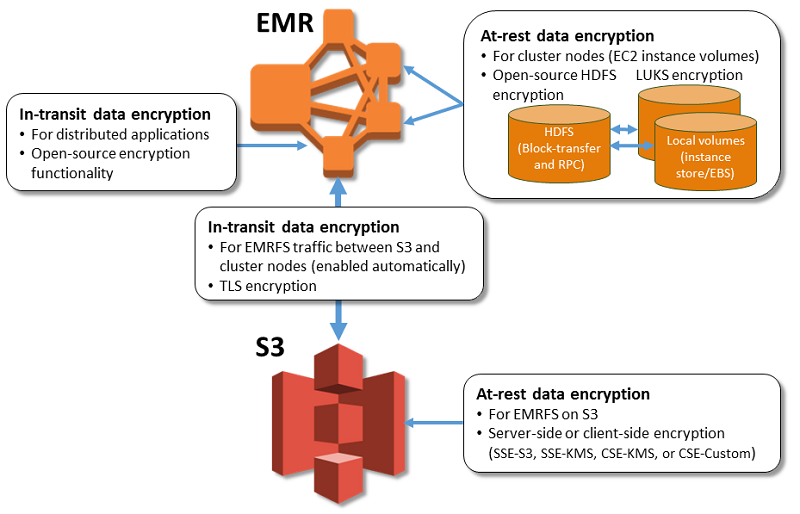
- EMR always uses HTTPS to send data between S3 and EC2.
- EMR enables the use of security configuration
- which helps to encrypt data at rest, data in transit, or both
- can be used to specify settings for S3 encryption with EMR file system (EMRFS), local disk encryption, and in-transit encryption
- is stored in EMR rather than the cluster configuration making it reusable
- gives the flexibility to choose from several options, including keys managed by AWS KMS, keys managed by S3, and keys and certificates from custom providers that you supply.
- At-rest Encryption for S3 with EMRFS
- EMRFS supports Server-side (SSE-S3, SSE-KMS) and Client-side encryption (CSE-KMS or CSE-Custom)
- S3 SSE and CSE encryption with EMRFS are mutually exclusive; either one can be selected but not both
- Transport layer security (TLS) encrypts EMRFS objects in-transit between EMR cluster nodes & S3
- At-rest Encryption for Local Disks
- Open-source HDFS Encryption
- HDFS exchanges data between cluster instances during distributed processing, and also reads from and writes data to instance store volumes and the EBS volumes attached to instances
- Open-source Hadoop encryption options are activated
- Secure Hadoop RPC is set to “Privacy”, which uses Simple Authentication Security Layer (SASL).
- Data encryption on HDFS block data transfer is set to true and is configured to use AES 256 encryption.
- EBS Volume Encryption
- EBS Encryption
- EBS encryption option encrypts the EBS root device volume and attached storage volumes.
- EBS encryption option is available only when you specify AWS KMS as your key provider.
- LUKS
- EC2 instance store volumes (except boot/root volumes) and the attached EBS volumes can be encrypted using LUKS.
- EBS Encryption
- Open-source HDFS Encryption
- In-Transit Data Encryption
- Encryption artifacts used for in-transit encryption in one of two ways:
- either by providing a zipped file of certificates that you upload to S3,
- or by referencing a custom Java class that provides encryption artifacts
- Encryption artifacts used for in-transit encryption in one of two ways:
- EMR block public access prevents a cluster in a public subnet from launching when any security group associated with the cluster has a rule that allows inbound traffic from anywhere (public access) on a port, unless the port has been specified as an exception.
- EMR Runtime Roles help manage access control for each job or query individually, instead of sharing the EMR instance profile of the cluster.
- EMR IAM service roles help perform actions on your behalf when provisioning cluster resources, running applications, dynamically scaling resources, and creating and running EMR Notebooks.
- SSH clients can use an EC2 key pair or Kerberos to authenticate to cluster instances.
- Lake Formation based access control can be applied to Spark, Hive, and Presto jobs that you submit to the EMR clusters.
EMR Cluster Types
- EMR has two cluster types, transient and persistent
- Transient EMR Clusters
- Transient EMR clusters are clusters that shut down when the job or the steps (series of jobs) are complete
- Transient EMT clusters can be used in situations
- where total number of EMR processing hours per day < 24 hours and its beneficial to shut down the cluster when it’s not being used.
- using HDFS as your primary data storage.
- job processing is intensive, iterative data processing.
- Persistent EMR Clusters
- Persistent EMR clusters continue to run after the data processing job is complete
- Persistent EMR clusters can be used in situations
- frequently run processing jobs where it’s beneficial to keep the cluster running after the previous job.
- processing jobs have an input-output dependency on one another.
- In rare cases when it is more cost effective to store the data on HDFS instead of S3
EMR Serverless
- EMR Serverless helps run big data frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters.
- currently supports Apache Spark and Apache Hive engines.
- automatically determines the resources that the application needs and gets these resources to process the jobs, and releases the resources when the jobs finish.
- minimum and maximum number of concurrent workers and the vCPU and memory configuration for workers can be specified.
- supports multiple AZs and provides resilience to AZ failures.
- An EMR Serverless application internally uses workers to execute your workloads and it offers two options for workers
- On-demand workers
- are launched only when needed for a job and are released automatically when the job is complete.
- scales the application up or down based on the workload, so you don’t have to worry about over- or under-provisioning resources.
- takes up to 120 seconds to determine the required resources and provision them.
- distributes jobs across multiple AZs by default, but each job runs only in one AZ.
- automatically runs your job in another healthy AZ, if an AZ fails.
- Pre-initialized workers
- are an optional feature where you can keep workers ready to respond in seconds.
- It effectively creates a warm pool of workers for an application which allows jobs to start instantly, making it ideal for iterative applications and time-sensitive jobs.
- submits job in an healthy AZ from the specified subnets. Application needs to be restarted to switch to another healthy AZ, if an AZ becomes impaired.
- On-demand workers
EMR Studio
- EMR Studio is an IDE that helps data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark.
- is a fully managed application with single sign-on, fully managed Jupyter Notebooks, automated infrastructure provisioning, and the ability to debug jobs without logging into the AWS Console or cluster.
EMR Notebooks
- EMR Notebooks provide a managed environment, based on Jupyter Notebook, that allows data scientists, analysts, and developers to prepare and visualize data, collaborate with peers, build applications, and perform interactive analysis using EMR clusters.
- AWS recommends using EMR Studio instead of EMR Notebooks now.
- Users can create serverless notebooks directly from the console, attach them to an existing shared EMR cluster, or provision a cluster directly from the console and build Spark applications and run interactive queries.
- Notebooks are auto-saved to S3 buckets, and can be retrieved from the console to resume work.
- Notebooks can be detached and attached to new clusters.
- Notebooks are prepackaged with the libraries found in the Anaconda repository, allowing you to import and use these libraries in the notebooks code and use them to manipulate data and visualize results.
EMR Best Practices
- Data Migration
- Two tools – S3DistCp and DistCp – can be used to move data stored on the local (data center) HDFS storage to S3, from S3 to HDFS and between S3 and local disk (non HDFS) to S3
- AWS Import/Export and Direct Connect can also be considered for moving data
- Data Collection
- Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, & moving large amounts of log data
- Flume agents can be installed on the data sources (web-servers, app servers etc) and data shipped to the collectors which can then be stored in persistent storage like S3 or HDFS
- Data Aggregation
- Data aggregation refers to techniques for gathering individual data records (for e.g. log records) and combining them into a large bundle of data files i.e. creating a large file from small files
- Hadoop, on which EMR runs, generally performs better with fewer large files compared to many small files
- Hadoop splits the file on HDFS on multiple nodes, while for the data in S3 it uses the HTTP Range header query to split the files which helps improve performance by supporting parallelization
- Log collectors like Flume and Fluentd can be used to aggregate data before copying it to the final destination (S3 or HDFS)
- Data aggregation has following benefits
- Improves data ingest scalability by reducing the number of times needed to upload data to AWS
- Reduces the number of files stored on S3 (or HDFS), which inherently helps provide better performance when processing data
- Provides a better compression ratio as compressing large, highly compressible files is often more effective than compressing a large number of smaller files.
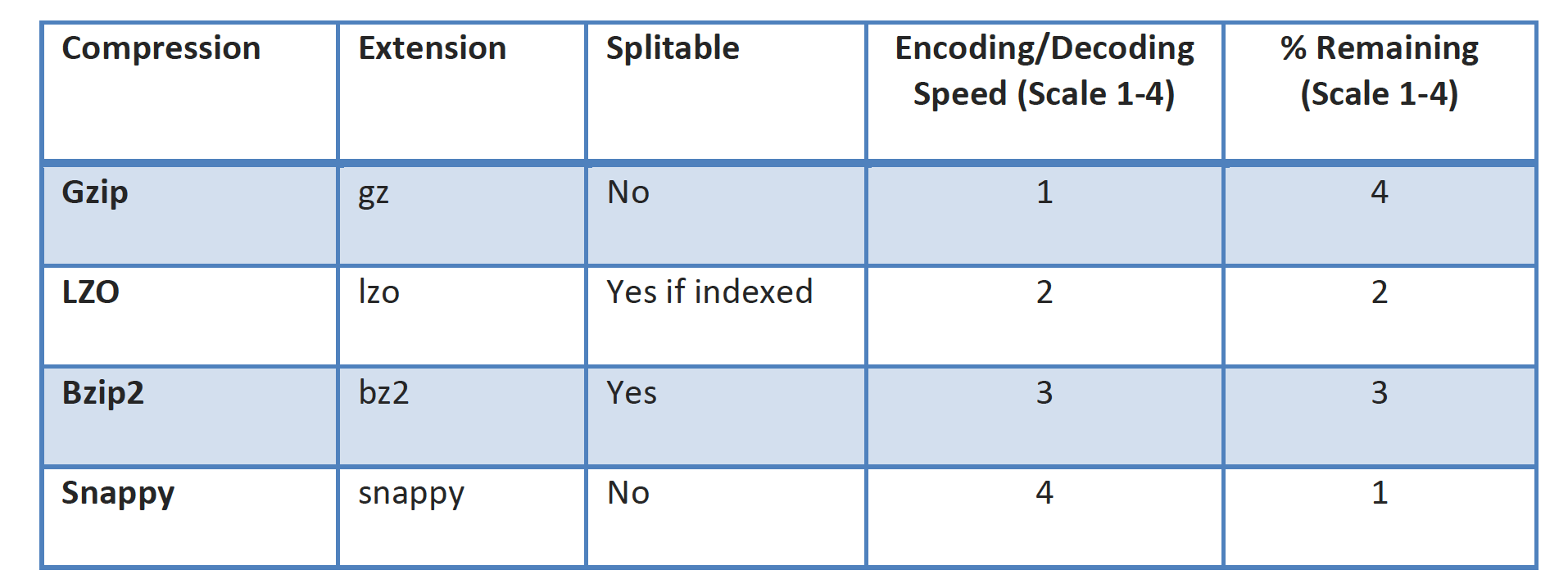
- Data compression
- Data compression can be used at the input as well as intermediate outputs from the mappers
- Data compression helps
- Lower storage costs
- Lower bandwidth cost for data transfer
- Better data processing performance by moving less data between data storage location, mappers, and reducers
- Better data processing performance by compressing the data that EMR writes to disk, i.e. achieving better performance by writing to disk less frequently
- Data Compression can have an impact on Hadoop data splitting logic as some of the compression techniques like gzip do not support it
- Data Partitioning
- Data partitioning helps in data optimizations and lets you create unique buckets of data and eliminate the need for a data processing job to read the entire data set
- Data can be partitioned by
- Data type (time series)
- Data processing frequency (per hour, per day, etc.)
- Data access and query pattern (query on time vs. query on geo location)
- Cost Optimization
- AWS offers different pricing models for EC2 instances
- On-Demand instances
- are a good option if using transient EMR jobs or if the EMR hourly usage is less than 17% of the time
- Reserved instances
- are a good option for persistent EMR cluster or if the EMR hourly usage is more than 17% of the time as is more cost effective
- Spot instances
- can be a cost effective mechanism to add compute capacity
- can be used where the data is persists on S3
- can be used to add extra task capacity with Task nodes, and
- is not suited for Master node, as if it is lost the cluster is lost and Core nodes (data nodes) as they host data and if lost needs to be recovered to rebalance the HDFS cluster
- On-Demand instances
- Architecture pattern can be used,
- Run master node on On-Demand or Reserved Instances (if running persistent EMR clusters).
- Run a portion of the EMR cluster on core nodes using On-Demand or Reserved Instances and
- the rest of the cluster on task nodes using Spot Instances.
- AWS offers different pricing models for EC2 instances

AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- You require the ability to analyze a large amount of data, which is stored on Amazon S3 using Amazon Elastic Map Reduce. You are using the cc2.8xlarge instance type, who’s CPUs are mostly idle during processing. Which of the below would be the most cost efficient way to reduce the runtime of the job? [PROFESSIONAL]
- Create smaller files on Amazon S3.
- Add additional cc2.8xlarge instances by introducing a task group.
- Use smaller instances that have higher aggregate I/O performance.
- Create fewer, larger files on Amazon S3.
- A customer’s nightly EMR job processes a single 2-TB data file stored on Amazon Simple Storage Service (S3). The Amazon Elastic Map Reduce (EMR) job runs on two On-Demand core nodes and three On-Demand task nodes. Which of the following may help reduce the EMR job completion time? Choose 2 answers
- Use three Spot Instances rather than three On-Demand instances for the task nodes.
- Change the input split size in the MapReduce job configuration.
- Use a bootstrap action to present the S3 bucket as a local filesystem.
- Launch the core nodes and task nodes within an Amazon Virtual Cloud.
- Adjust the number of simultaneous mapper tasks.
- Enable termination protection for the job flow.
- Your department creates regular analytics reports from your company’s log files. All log data is collected in Amazon S3 and processed by daily Amazon Elastic Map Reduce (EMR) jobs that generate daily PDF reports and aggregated tables in CSV format for an Amazon Redshift data warehouse. Your CFO requests that you optimize the cost structure for this system. Which of the following alternatives will lower costs without compromising average performance of the system or data integrity for the raw data? [PROFESSIONAL]
- Use reduced redundancy storage (RRS) for PDF and CSV data in Amazon S3. Add Spot instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift. (Only Spot instances impacts performance)
- Use reduced redundancy storage (RRS) for all data in S3. Use a combination of Spot instances and Reserved Instances for Amazon EMR jobs. Use Reserved instances for Amazon Redshift (Combination of the Spot and reserved with guarantee performance and help reduce cost. Also, RRS would reduce cost and guarantee data integrity, which is different from data durability)
- Use reduced redundancy storage (RRS) for all data in Amazon S3. Add Spot Instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift (Only Spot instances impacts performance)
- Use reduced redundancy storage (RRS) for PDF and CSV data in S3. Add Spot Instances to EMR jobs. Use Spot Instances for Amazon Redshift. (Spot instances impacts performance and Spot instance not available for Redshift)
- A research scientist is planning for the one-time launch of an Elastic MapReduce cluster and is encouraged by her manager to minimize the costs. The cluster is designed to ingest 200TB of genomics data with a total of 100 Amazon EC2 instances and is expected to run for around four hours. The resulting data set must be stored temporarily until archived into an Amazon RDS Oracle instance. Which option will help save the most money while meeting requirements? [PROFESSIONAL]
- Store ingest and output files in Amazon S3. Deploy on-demand for the master and core nodes and spot for the task nodes.
- Optimize by deploying a combination of on-demand, RI and spot-pricing models for the master, core and task nodes. Store ingest and output files in Amazon S3 with a lifecycle policy that archives them to Amazon Glacier. (Master and Core must be RI or On Demand. Cannot be Spot)
- Store the ingest files in Amazon S3 RRS and store the output files in S3. Deploy Reserved Instances for the master and core nodes and on-demand for the task nodes. (Need better durability for ingest file. Spot instances can be used for task nodes for cost saving. RI will not provide cost saving in this case)
- Deploy on-demand master, core and task nodes and store ingest and output files in Amazon S3 RRS (Input should be in S3 standard, as re-ingesting the input data might end up being more costly then holding the data for limited time in standard S3)
- Your company sells consumer devices and needs to record the first activation of all sold devices. Devices are not activated until the information is written on a persistent database. Activation data is very important for your company and must be analyzed daily with a MapReduce job. The execution time of the data analysis process must be less than three hours per day. Devices are usually sold evenly during the year, but when a new device model is out, there is a predictable peak in activation’s, that is, for a few days there are 10 times or even 100 times more activation’s than in average day. Which of the following databases and analysis framework would you implement to better optimize costs and performance for this workload? [PROFESSIONAL]
- Amazon RDS and Amazon Elastic MapReduce with Spot instances.
- Amazon DynamoDB and Amazon Elastic MapReduce with Spot instances.
- Amazon RDS and Amazon Elastic MapReduce with Reserved instances.
- Amazon DynamoDB and Amazon Elastic MapReduce with Reserved instances