Google Cloud Spanner
🆕 Major Updates (2024-2026)
- Spanner Editions (2024): New tier-based pricing – Standard, Enterprise, and Enterprise Plus editions replacing legacy pricing.
- Multi-Model Database (2024-2025): Spanner Graph, Full-Text Search, and Vector Search capabilities added.
- Spanner Omni (2026 Preview): Run Spanner on-premises, across clouds, or on a laptop.
- Columnar Engine (2025): Real-time analytics on operational data without impacting transactional workloads.
- Managed Autoscaler (2025 GA): Automatic scaling with independent read-only replica scaling.
- Tiered Storage (2025 GA): SSD and HDD storage tiers within same instance (~80% cost reduction for cold data).
- Cloud Spanner is a fully managed, mission-critical relational database service
- Cloud Spanner provides a scalable online transaction processing (OLTP) database with high availability and strong consistency at a global scale.
- Cloud Spanner provides traditional relational semantics like schemas, ACID transactions and SQL interface
- Cloud Spanner provides Automatic, Synchronous replication within and across regions for high availability (99.999%)
- Spanner now handles over 6 billion queries per second at peak and more than 17 exabytes of data
- Cloud Spanner benefits
- OLTP (Online Transactional Processing)
- Global scale
- Relational data model
- ACID/Strong or External consistency
- Low latency
- Fully managed and highly available
- Automatic replication
- Multi-model support – relational, graph, key-value, vector, and full-text search in a single database
- AI-ready – built-in vector search, ML predictions, and Vertex AI integrations
Spanner Editions
- Spanner offers editions, a tier-based pricing model introduced in 2024 that provides different capabilities at different price points.
- Standard Edition
- Comprehensive suite of established capabilities (all GA features prior to September 2024)
- Regional instance configurations only
- 99.99% availability SLA
- Relational (GoogleSQL, PostgreSQL) and Key-value support
- BigQuery federation, Data Boost, Reverse ETL
- Standard backups, 7-day PITR, Scheduled backups
- Enterprise Edition
- Builds on Standard edition with multi-model capabilities
- Regional instance configurations with optional custom read-only replicas
- 99.99% availability SLA
- Adds Spanner Graph, Full-text search, Vector Search (KNN & ANN)
- Managed autoscaler, Tiered storage, Locality groups
- Columnar engine for analytics
- Incremental backups
- Enterprise Plus Edition
- Designed for most demanding workloads
- Multi-region and dual-region instance configurations
- Up to 99.999% availability SLA
- All Enterprise features plus geo-partitioning
- Committed Use Discounts (CUDs): 20% for 1-year, 40% for 3-year commitments across all editions
- Free trial instance available (defaults to Enterprise edition on upgrade)
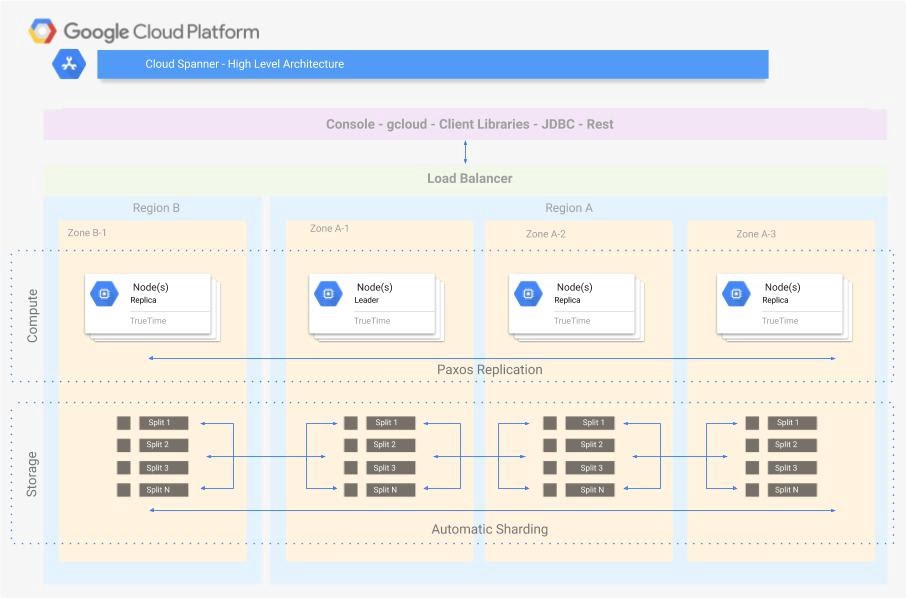
Cloud Spanner Architecture
 Instance
Instance
- Cloud Spanner Instance determines the location and the allocation of resources
- Instance creation includes two important choices
- Instance configuration
- determines the geographic placement i.e. location and replication of the databases
- Location can be regional, dual-region, or multi-regional
- cannot be changed once selected during the creation (but instances can be moved using the Move Instance feature)
- Compute capacity (nodes or processing units)
- determines the amount of the instance’s serving and storage resources
- measured in processing units (PUs) or nodes, with 1000 PUs = 1 node
- minimum of 100 PUs for granular instances, scaling in batches of 100 PUs
- can be updated manually or via managed autoscaler
- Instance configuration
- Cloud Spanner distributes an instance across zones of one or more regions to provide high performance and high availability
- Cloud Spanner instances have:
- At least three read-write replicas of the database each in a different zone
- Each zone is a separate isolation fault domain
- Paxos distributed consensus protocol used for writes/transaction commits
- Synchronous replication of writes to all zones across all regions
- Database is available even if one zone fails (99.999% availability SLA for multi-region and 99.99% availability SLA for regional)
Regional vs Dual-Region vs Multi-Regional
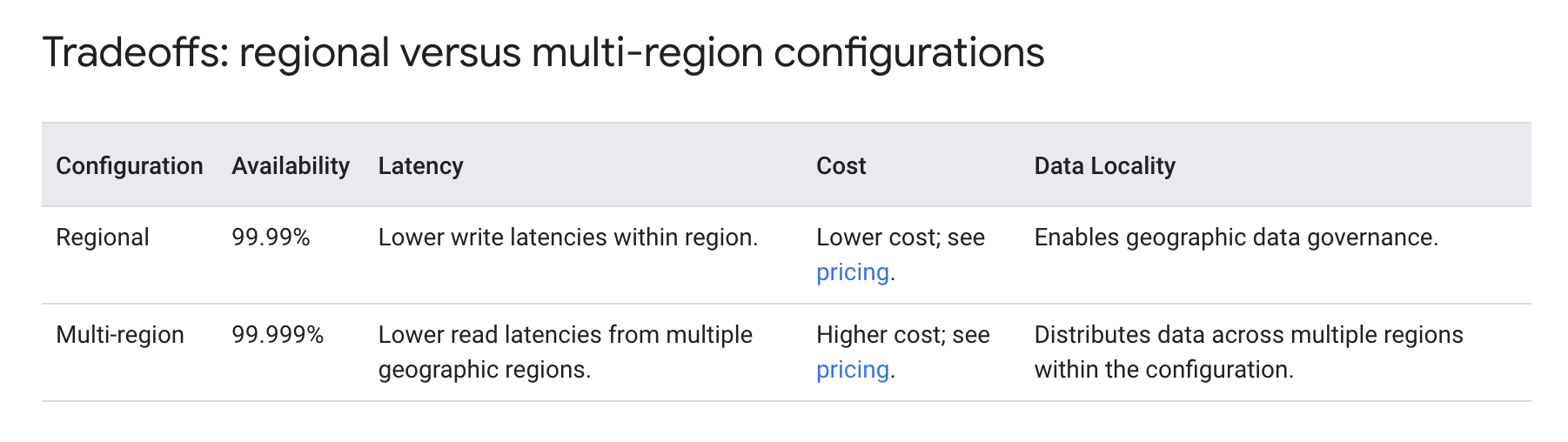
- Regional Configuration
- Cloud Spanner maintains 3 read-write replicas, each within a different Google Cloud zone in that region.
- Each read-write replica contains a full copy of the operational database that is able to serve read-write and read-only requests.
- Cloud Spanner uses replicas in different zones so that if a single-zone failure occurs, the database remains available.
- Every Cloud Spanner mutation requires a write quorum that’s composed of a majority of voting replicas. Write quorums are formed from two out of the three replicas in regional configurations.
- Provides 99.99% availability
- Available in Standard, Enterprise, and Enterprise Plus editions
- Dual-Region Configuration (New – 2024)
- Provides five 9s (99.999%) of availability with only two regions
- Helps meet local residency requirements in geographies with only two regions
- Zero recovery-point objective (RPO) guarantees
- Available only in Enterprise Plus edition
- Multi-Regional Configuration
- Multi-region configurations allow replicating the database’s data not just in multiple zones, but in multiple zones across multiple regions
- Additional replicas enable reading data with low latency from multiple locations close to or within the regions in the configuration.
- As the quorum (read-write) replicas are spread across more than one region, additional network latency is incurred when these replicas communicate with each other to vote on writes.
- Multi-region configurations enable the application to achieve faster reads in more places at the cost of a small increase in write latency.
- Provides 99.999% availability
- Multi-regional makes use of Paxos-based replication, TrueTime and leader election, to provide global consistency and higher availability
- Available only in Enterprise Plus edition
Geo-Partitioning (New – 2024)
- Partition table data at the row-level across the globe
- Serves data closer to users for reduced application latency
- Provides data residency benefits – store sensitive data within specific geographic jurisdictions
- Optimizes costs by placing data in appropriate regions
- Available only in Enterprise Plus edition
Replication
- Cloud Spanner automatically gets replication at the byte level from the underlying distributed filesystem.
- Cloud Spanner also performs data replication to provide global availability and geographic locality, with fail-over between replicas being transparent to the client.
- Cloud Spanner creates multiple copies, or “replicas,” of the rows, then stores these replicas in different geographic areas.
- Cloud Spanner uses a synchronous, Paxos distributed consensus protocol, in which voting replicas take a vote on every write request to ensure transactions are available in sufficient replicas before being committed.
- Globally synchronous replication gives the ability to read the most up-to-date data from any Cloud Spanner read-write or read-only replica.
- Cloud Spanner creates replicas of each database split
- A split holds a range of contiguous rows, where the rows are ordered by the primary key.
- All of the data in a split is physically stored together in the replica, and Cloud Spanner serves each replica out of an independent failure zone.
- A set of splits is stored and replicated using Paxos.
- Within each Paxos replica set, one replica is elected to act as the leader.
- Leader replicas are responsible for handling writes, while any read-write or read-only replica can serve a read request without communicating with the leader (though if a strong read is requested, the leader will typically be consulted to ensure that the read-only replica has received all recent mutations)
- Cloud Spanner automatically reshards data into splits and automatically migrates data across machines (even across datacenters) to balance load, and in response to failures.
- Spanner’s sharding considers the parent child relationships in interleaved tables and related data is migrated together to preserve query performance
- Read Leases (New – 2025): Read leases can improve read latency for strongly consistent data in multi-region configurations by trading off some write performance for common read-mostly workloads
Cloud Spanner Data Model
- A Cloud Spanner Instance can contain one or more databases
- A Cloud Spanner database can contain one or more tables
- Tables look like relational database tables in that they are structured with rows, columns, and values, and they contain primary keys
- Every table must have a primary key, and that primary key can be composed of zero or more columns of that table
- Supports both GoogleSQL and PostgreSQL dialects
- Parent-child relationships in Cloud Spanner
- Table Interleaving
- Table interleaving is a good choice for many parent-child relationships where the child table’s primary key includes the parent table’s primary key columns
- Child rows are colocated with the parent rows significantly improving the performance
- Primary key column(s) of the parent table must be the prefix of the primary key of the child table
- Foreign Keys
- Foreign keys are similar to traditional databases.
- They are not limited to primary key columns, and tables can have multiple foreign key relationships, both as a parent in some relationships and a child in others.
- The foreign key relationship does not guarantee data co-location
- Table Interleaving
- Cloud Spanner automatically creates an index for each table’s primary key
- Secondary indexes can be created for other columns
- Named Schemas (New – 2025): Organize and encapsulate database objects using named schema support
Multi-Model Capabilities (New – 2024/2025)
- Spanner evolved into a multi-model database supporting multiple data models within a single instance without data movement
- Spanner Graph
- Native graph database capabilities using GQL (Graph Query Language)
- Supports schemaless data for iterative development
- Build graphs on named schema objects and SQL views
- Graph algorithms support for connected data analysis
- Interoperable with SQL – combine graph and relational queries
- Available in Enterprise and Enterprise Plus editions
- Full-Text Search
- Built-in full-text search with tokenization and search indexes
- Enhanced query mode with automatic synonym matching and spell correction
- JSON indexing for accelerated queries over JSON data
- Fuzzy search, faceted search, and substring search support
- Available in Enterprise and Enterprise Plus editions
- Vector Search
- Exact K-Nearest Neighbors (KNN) search
- Approximate Nearest Neighbors (ANN) search using Google’s ScaNN algorithm (GA in 2025)
- Scales to more than 10 billion vectors
- Combine vector searches with SQL and graph GQL queries for RAG applications
- Available in Enterprise and Enterprise Plus editions
- Key-Value (Cassandra Interface)
- Cassandra interface allows using familiar CQL tools and syntax
- Lift and shift Cassandra applications with virtually no changes
- Available in all editions
Spanner AI Integration (New – 2024/2025)
- Vector Embeddings: Generate and store vector embeddings directly in Spanner with Vertex AI integration
- ML.PREDICT: Natural language queries using ML predictions via SQL
- MCP Toolbox for Databases: Build agentic AI applications with Spanner
- Agent Development Kit (ADK): Integration with Google’s ADK for Spanner
- Vertex RAG Engine: Use Spanner as a RAG-managed database for data indexing and retrieval
- LangChain & LlamaIndex: Framework integrations for LLM-powered applications
- Conversational Data Agents: Build data agents with conversational analytics
- Key AI use cases: product search and recommendations, fraud detection, identity resolution, autonomous network operations
Cloud Spanner Scaling
- Increase the compute capacity of the instance to scale up the server and storage resources in the instance.
- Each node (1000 PUs) provides up to 4TB of data storage (increased from 2TB in 2022)
- Nodes provide additional compute resources to increase throughput
- Increasing compute capacity does not increase the replica count but gives each replica more CPU and RAM, which increases the replica’s throughput (that is, more reads and writes per second can occur).
- Start with as little as 100 processing units for granular instances (as low as $65/month)
- Managed Autoscaler (GA – 2025)
- Automatically scales compute capacity based on workload levels
- Define minimum and maximum compute capacity limits
- Supports independent scaling of read-only replicas from read-write replicas
- Available in Enterprise and Enterprise Plus editions
- Manual Split Points (New – 2025): Pre-split data to handle anticipated traffic spikes (e.g., flash sales, game launches)
- Tiered Storage (GA – 2025)
- Store data across SSD and HDD within the same instance
- Older data automatically moves to lower cost HDD storage (~80% cheaper)
- No API changes required to access data on different tiers
- Available in Enterprise and Enterprise Plus editions
Spanner Analytics & BigQuery Integration (New – 2024/2025)
- Columnar Engine (Preview – 2025)
- Analyze vast amounts of operational data in real-time
- Maintains global consistency, high availability, and strong transactional guarantees
- Does not impact transactional workloads
- Available in Enterprise and Enterprise Plus editions
- BigQuery Integration
- External Datasets (GA): Query live Spanner data directly in BigQuery with zero ETL
- Materialized Views: Ultra-fast reporting using pre-computed query results on Spanner data
- Reverse ETL: Export/stream computed insights from BigQuery to Spanner
- Apache Iceberg Support: Join live Spanner data with Iceberg tables in BigQuery
- Data Boost: Independent compute resources for analytics queries without impacting operational workloads
Cloud Spanner Backup & PITR
- Cloud Spanner Backup and Restore helps create backups of Cloud Spanner databases on demand, and restore them to provide protection against operator and application errors that result in logical data corruption.
- Backups are highly available, encrypted, and can be retained for up to a year from the time they are created.
- Cloud Spanner point-in-time recovery (PITR) provides protection against accidental deletion or writes.
- PITR works by letting you configure a database’s
version_retention_periodto retain all versions of data and schema, from a minimum of 1 hour up to a maximum of 7 days. - Scheduled Backups (New – 2024): Configure automatic backup schedules for databases
- Incremental Backups (New – 2024): Only back up changes since last backup, reducing cost and time (Enterprise/Enterprise Plus editions)
- Default Backup Schedules (New – 2025): Automatic recovery baseline from the moment a database is created
- Schema Object Drop Protection (New – 2025): Safeguard against accidental deletion of critical tables, indexes, and columns
Performance & Isolation (New – 2025)
- Repeatable Read Isolation (Preview): Reduces locking overhead for workloads with low read-write contention
- Query Optimizer v8: Automated enhancements optimizing join strategies and index usage
- Index Advisor: Analyzes query patterns and proactively suggests new indexes or identifies unused ones
- Schema Recommendations (Preview): Scans schema design for anti-patterns like hotspot-prone primary keys
- Leader-Aware Routing: Routes requests to the nearest leader replica for reduced latency
- Multiplexed Sessions: Enabled by default in major SDKs for improved throughput and resource utilization
- Spanner CLI: Bundled with gcloud for running SQL, managing sessions, and automating scripts
Spanner Omni (Preview – 2026)
- Downloadable version of Spanner that runs in your own environment
- Deploy on-premises data centers, across public clouds, or on a developer laptop
- Brings Spanner’s unlimited scalability, high availability, strong consistency, and security anywhere
- Supports connected, hybrid, multicloud, multiregion, and air-gapped configurations
- Scales from a single machine to clusters of thousands of servers
- Full multi-model capabilities available in Spanner Omni
Cloud Spanner Best Practices
- Design a schema that prevents hotspots and other performance issues.
- For optimal write latency, place compute resources for write-heavy workloads within or close to the default leader region.
- For optimal read performance outside of the default leader region, use staleness of at least 15 seconds.
- To avoid single-region dependency for the workloads, place critical compute resources in at least two regions.
- Provision enough compute capacity to keep high priority total CPU utilization under
- 65% in each region for regional configuration
- 45% in each region for multi-regional configuration
- Use the managed autoscaler to automatically adjust capacity based on workload patterns
- Use tiered storage for cost optimization of historical/cold data
- Use manual split points to pre-split data before anticipated traffic spikes
- Leverage the Index Advisor and Schema Recommendations for performance optimization
GCP Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- GCP services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- GCP exam questions are not updated to keep up the pace with GCP updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your customer has implemented a solution that uses Cloud Spanner and notices some read latency-related performance issues on one table. This table is accessed only by their users using a primary key. The table schema is shown below. You want to resolve the issue. What should you do?
- Remove the profile_picture field from the table.
- Add a secondary index on the person_id column.
- Change the primary key to not have monotonically increasing values.
- Create a secondary index using the following Data Definition Language (DDL) CREATE INDEX person_id_ix ON Persons (
person_id, firstname, lastname ) STORING ( profile_picture )
- You are building an application that stores relational data from users. Users across the globe will use this application. Your CTO is concerned about the scaling requirements because the size of the user base is unknown. You need to implement a database solution that can scale with your user growth with minimum configuration changes. Which storage solution should you use?
- Cloud SQL
- Cloud Spanner
- Cloud Firestore
- Cloud Datastore
- A financial organization wishes to develop a global application to store transactions happening from different part of the world. The storage system must provide low latency transaction support and horizontal scaling. Which GCP service is appropriate for this use case?
- Bigtable
- Datastore
- Cloud Storage
- Cloud Spanner
- A company needs to run similarity searches on product embeddings for their recommendation engine while maintaining strong transactional consistency across multiple regions. Which Spanner capability should they use?
- Full-text search with search indexes
- Vector search with ANN using ScaNN algorithm
- Spanner Graph with GQL queries
- BigQuery federation with Data Boost
- Your organization wants to use Cloud Spanner with 99.999% availability SLA and geo-partitioning to meet data residency requirements. Which Spanner edition should you select?
- Standard edition
- Enterprise edition
- Enterprise Plus edition
- Any edition with multi-region configuration
- You need to migrate an existing Apache Cassandra application to Cloud Spanner with minimal application code changes. What should you use?
- Spanner Migration Tool (SMT)
- Dataflow with Spanner connector
- Spanner Cassandra interface with CQL compatibility
- Manual schema translation and data import
- Your team wants to analyze real-time operational data in Spanner without impacting transactional workloads. Which feature should you enable?
- Data Boost
- BigQuery external datasets
- Spanner columnar engine
- Change streams with Dataflow
- A retail company expects a flash sale that will cause a 10x traffic spike on their Spanner database. What feature can help prepare for this anticipated load?
- Managed autoscaler with higher maximum limits
- Manual split points to pre-split data for anticipated traffic
- Adding more processing units ahead of time
- Enabling read leases for all tables