AWS Blue Green Deployment
- Blue/green deployments provide near zero-downtime release and rollback capabilities.
- Blue/green deployment works by shifting traffic between two identical environments that are running different versions of the application
- Blue environment represents the current application version serving production traffic.
- In parallel, the green environment is staged running a different version of your application.
- After the green environment is ready and tested, production traffic is redirected from blue to green.
- If any problems are identified, you can roll back by reverting traffic back to the blue environment.
NOTE: Advanced Topic required for DevOps Professional Exam Only
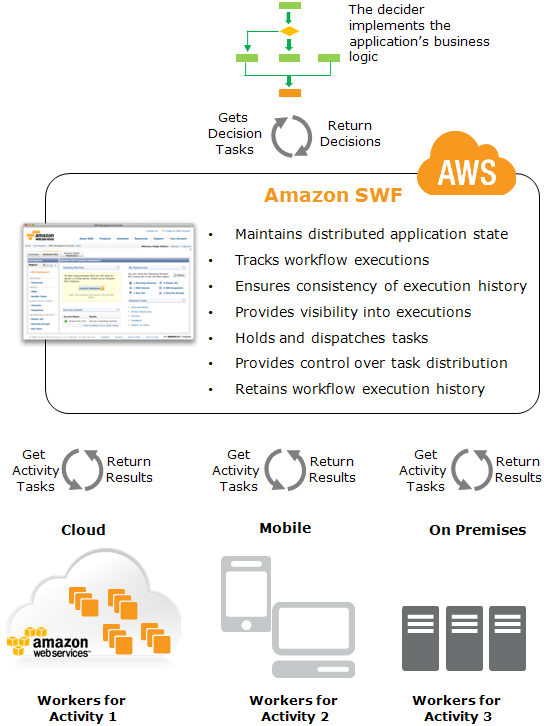
AWS Services
Route 53
- Route 53 is a highly available and scalable authoritative DNS service that route user requests
- Route 53 with its DNS service allows administrators to direct traffic by simply updating DNS records in the hosted zone
- TTL can be adjusted for resource records to be shorter which allow record changes to propagate faster to clients
Elastic Load Balancing
- Elastic Load Balancing distributes incoming application traffic across EC2 instances
- Elastic Load Balancing scales in response to incoming requests, performs health checking against Amazon EC2 resources, and naturally integrates with other AWS tools, such as Auto Scaling.
- ELB also helps perform health checks of EC2 instances to route traffic only to the healthy instances
Auto Scaling
- Auto Scaling allows different versions of launch configuration, which define templates used to launch EC2 instances, to be attached to an Auto Scaling group to enable blue/green deployment.
- Auto Scaling’s termination policies and Standby state enable blue/green deployment
- Termination policies in Auto Scaling groups to determine which EC2 instances to remove during a scaling action.
- Auto Scaling also allows instances to be placed in Standby state, instead of termination, which helps with quick rollback when required
- Auto Scaling with Elastic Load Balancing can be used to balance and scale the traffic
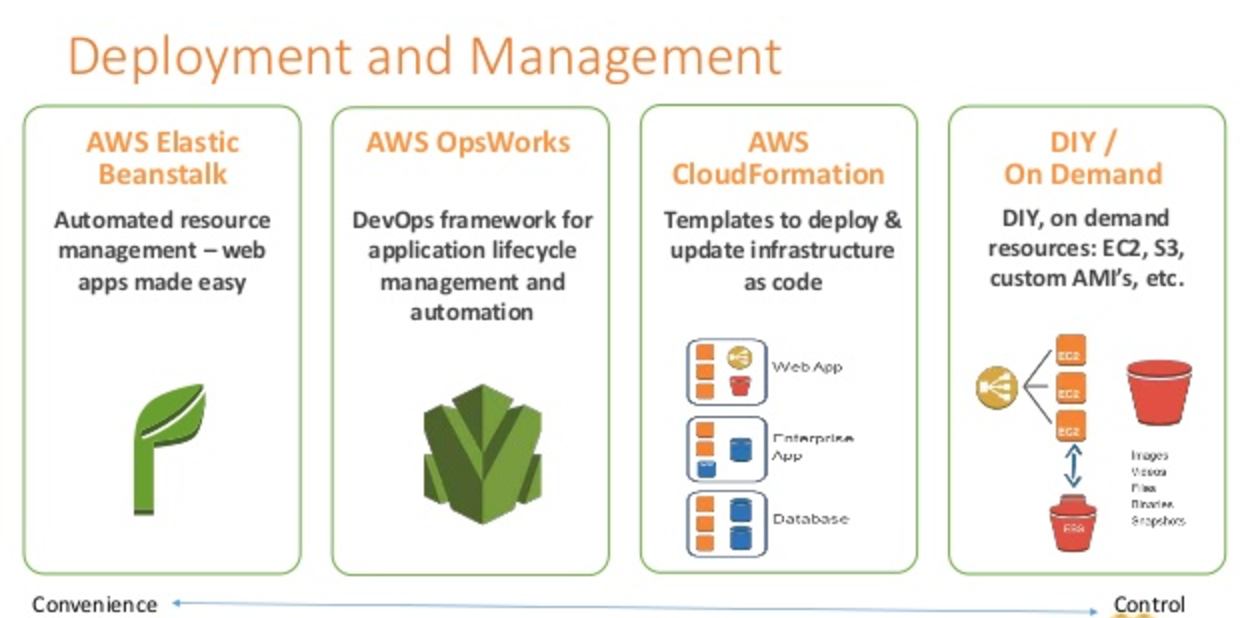
Elastic Beanstalk
- Elastic Beanstalk makes it easy to run multiple versions of the application and provides capabilities to swap the environment URLs, facilitating blue/green deployment.
- Elastic Beanstalk supports Auto Scaling and Elastic Load Balancing, both of which enable blue/green deployment
OpsWorks
- OpsWorks has the concept of stacks, which are logical groupings of AWS resources with a common purpose & should be logically managed together
- Stacks are made of one or more layers with each layer represents a set of EC2 instances that serve a particular purpose, such as serving applications or hosting a database server.
- OpsWorks simplifies cloning entire stacks when preparing for blue/green environments.
CloudFormation
- CloudFormation helps describe the AWS resources through JSON formatted templates and provides automation capabilities for provisioning blue/green environments and facilitating updates to switch traffic, whether through Route 53 DNS, Elastic Load Balancing, etc
- CloudFormation provides infrastructure as code strategy, where infrastructure is provisioned and managed using code and software development techniques, such as version control and continuous integration, in a manner similar to how application code is treated
CloudWatch
- CloudWatch monitoring can provide early detection of application health in blue/green deployments
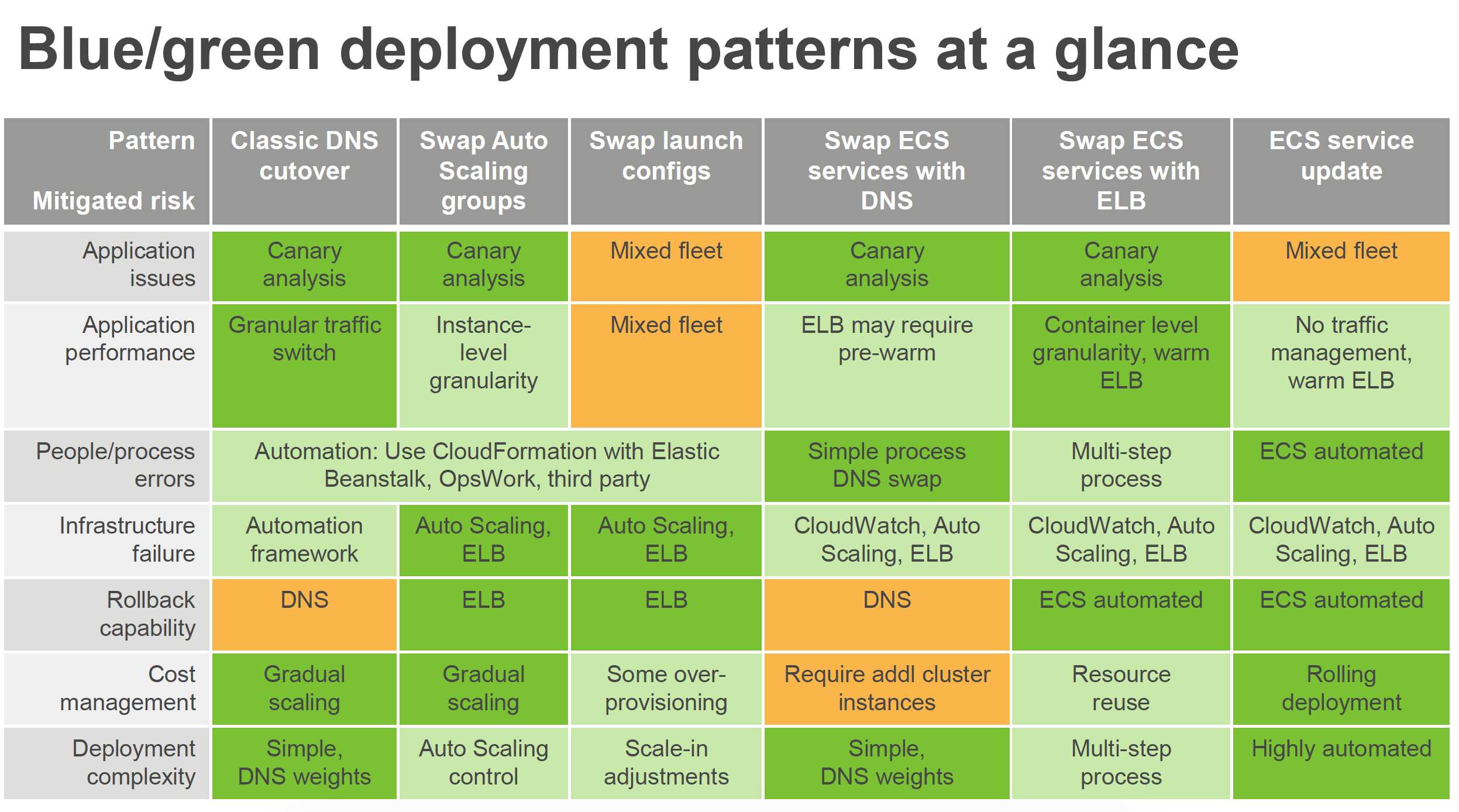
Deployment Techniques
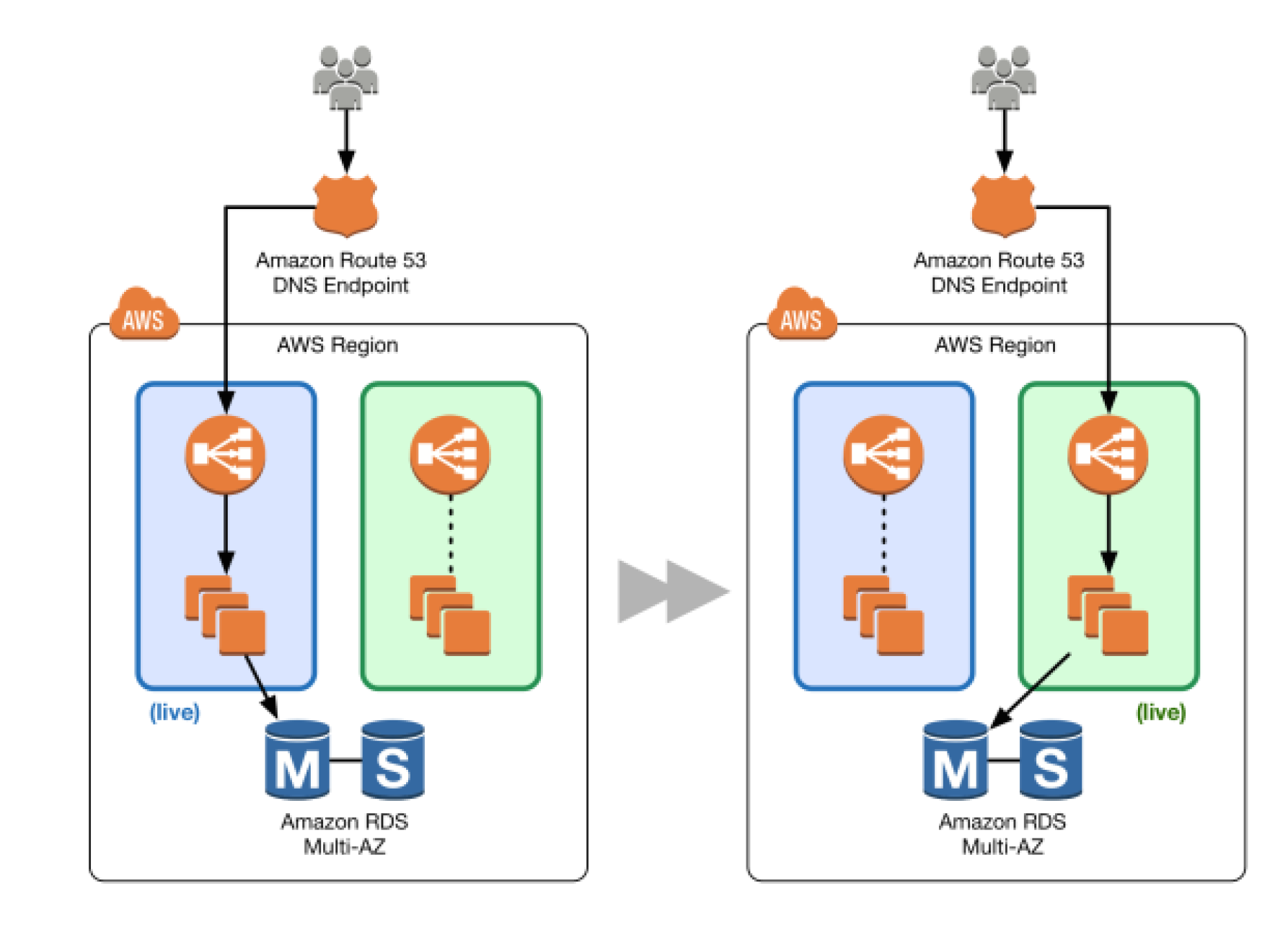
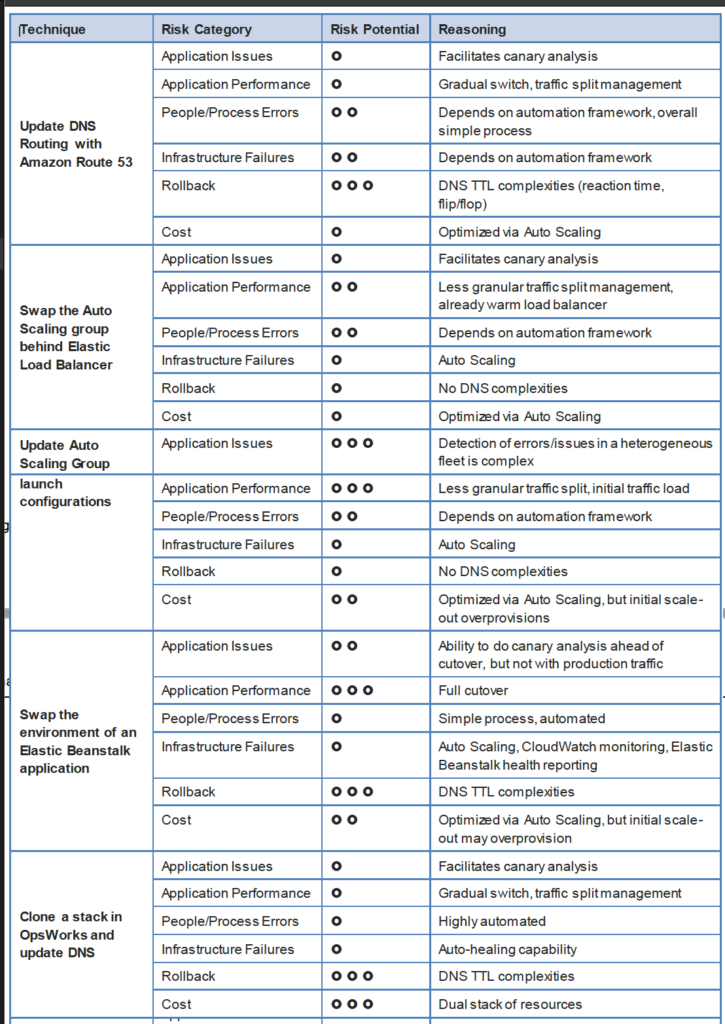
DNS Routing using Route 53
- Route 53 DNS service can help switch traffic from the blue environment to the green and vice versa, if rollback is necessary
- Route 53 can help either switch the traffic completely or through a weighted distribution
- Weighted distribution
- helps distribute percentage of traffic to go to the green environment and gradually update the weights until the green environment carries the full production traffic
- provides the ability to perform canary analysis where a small percentage of production traffic is introduced to a new environment
- helps manage cost by using auto scaling for instances to scale based on the actual demand
- Route 53 can handle Public or Elastic IP address, Elastic Load Balancer, Elastic Beanstalk environment web tiers etc.
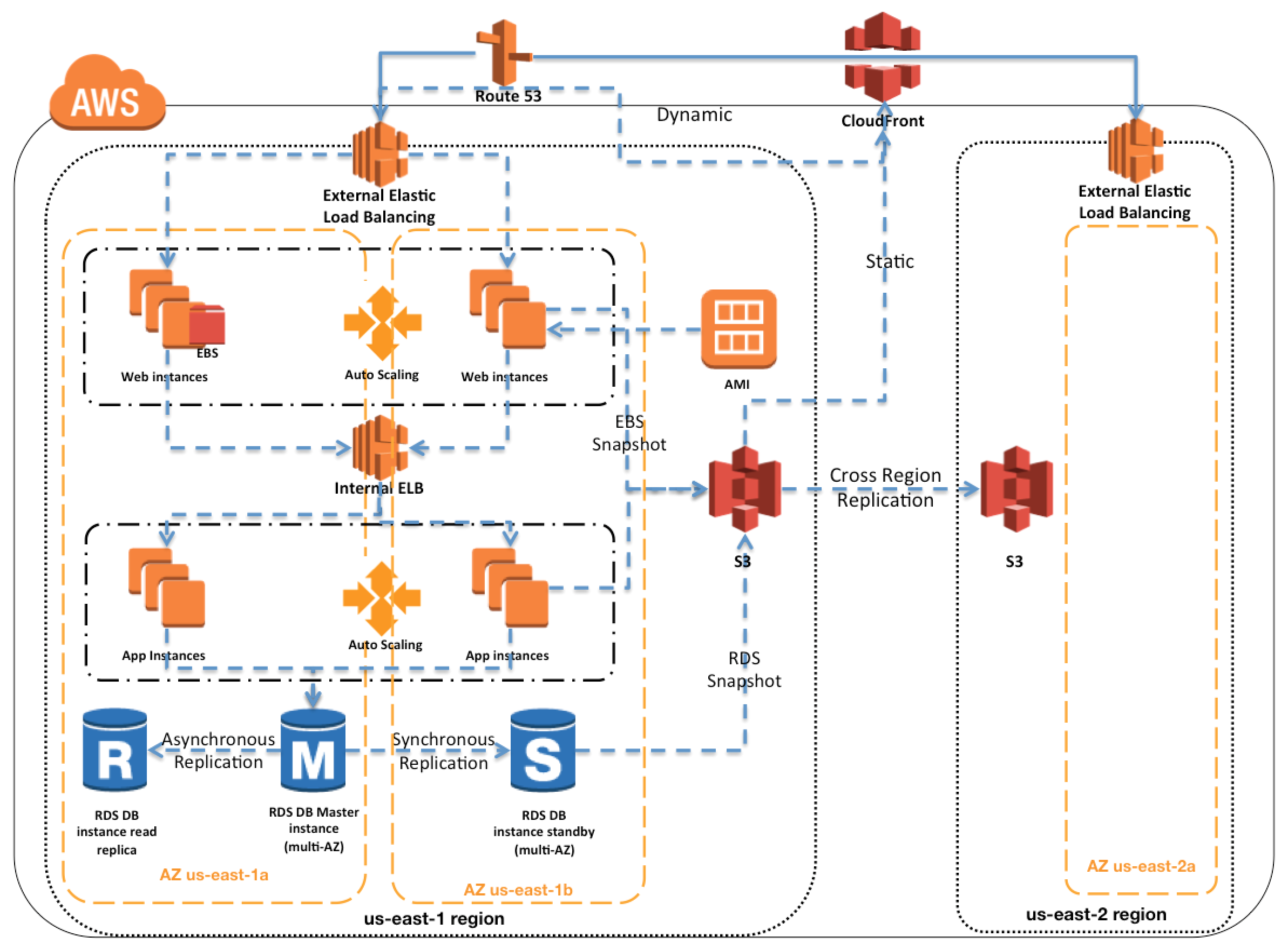
Auto Scaling Group Swap Behind Elastic Load Balancer
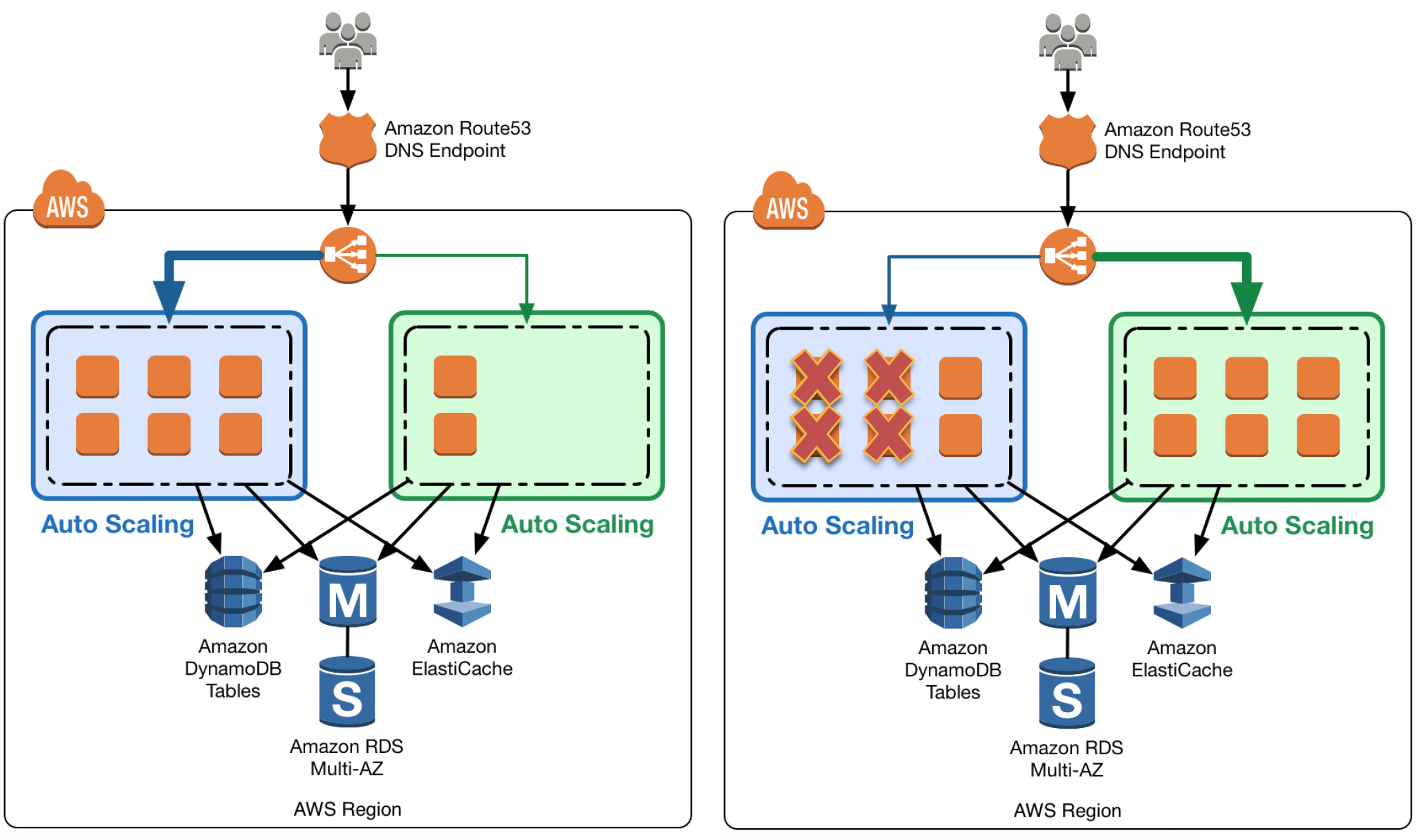
- Elastic Load Balancing with Auto Scaling to manage EC2 resources as per the demand can be used for Blue Green deployments
- Multiple Auto Scaling groups can be attached to the Elastic Load Balancer
- Green ASG can be attached to an existing ELB while Blue ASG is already attached to the ELB to serve traffic
- ELB would start routing requests to the Green Group as for HTTP/S listener it uses a least outstanding requests routing algorithm
- Green group capacity can be increased to process more traffic while the Blue group capacity can be reduced either by terminating the instances or by putting the instances in a standby mode
- Standby is a good option because if roll back to the blue environment needed, blue server instances can be put back in service and they’re ready to go
- If no issues with the Green group, the blue group can be decommissioned by adjusting the group size to zero
Update Auto Scaling Group Launch Configurations
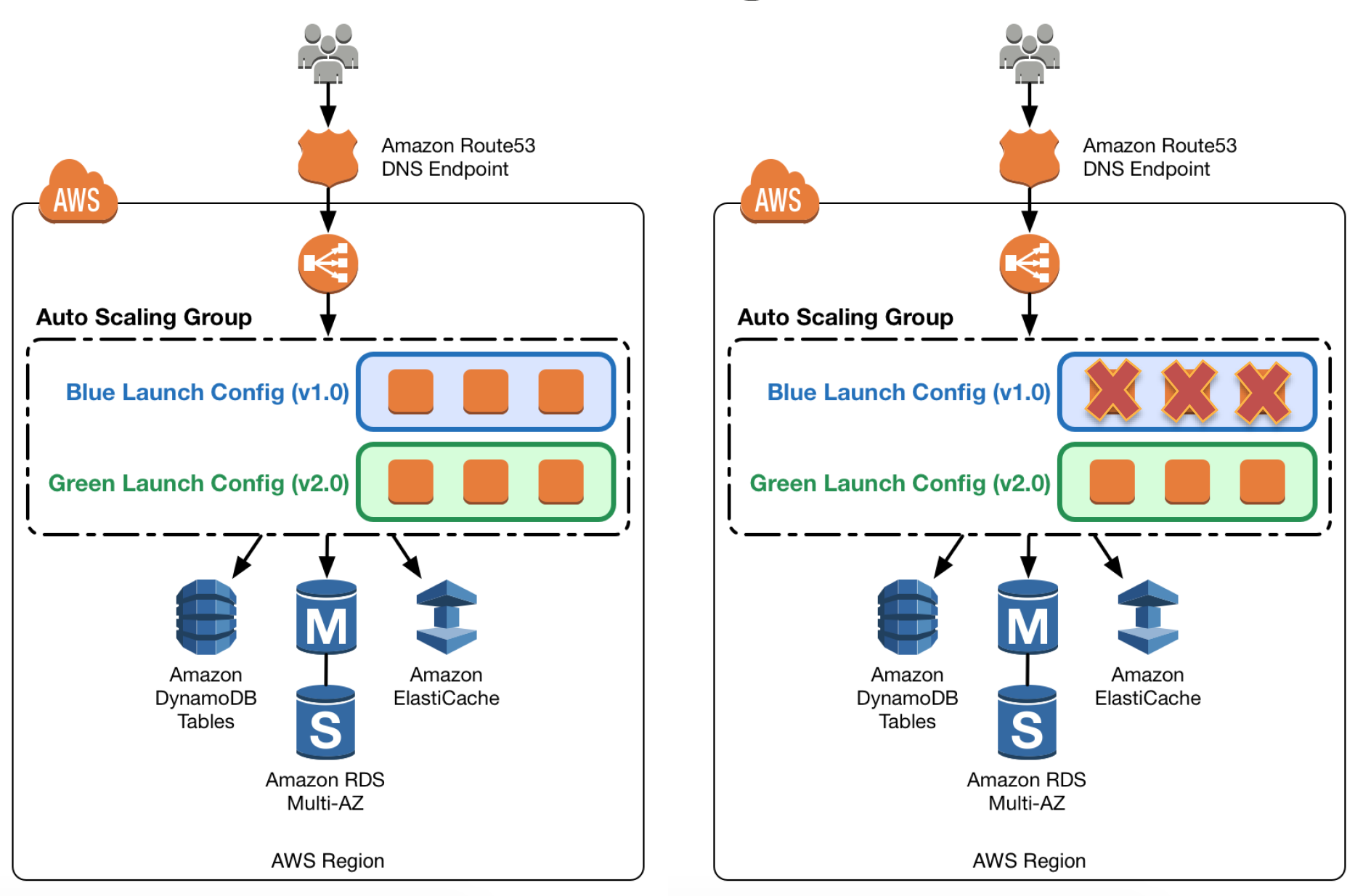
- Auto Scaling groups have their own launch configurations which define template for EC2 instances to be launched
- Auto Scaling group can have only one launch configuration at a time, and it can’t be modified. If needs modification, a new launch configuration can be created and attached to the existing Auto Scaling Group
- After a new launch configuration is in place, any new instances that are launched use the new launch configuration parameters, but existing instances are not affected.
- When Auto Scaling removes instances (referred to as scaling in) from the group, the default termination policy is to remove instances with the oldest launch configuration
- To deploy the new version of the application in the green environment, update the Auto Scaling group with the new launch configuration, and then scale the Auto Scaling group to twice its original size.
- Then, shrink the Auto Scaling group back to the original size
- To perform a rollback, update the Auto Scaling group with the old launch configuration. Then, do the preceding steps in reverse
Elastic Beanstalk Application Environment Swap
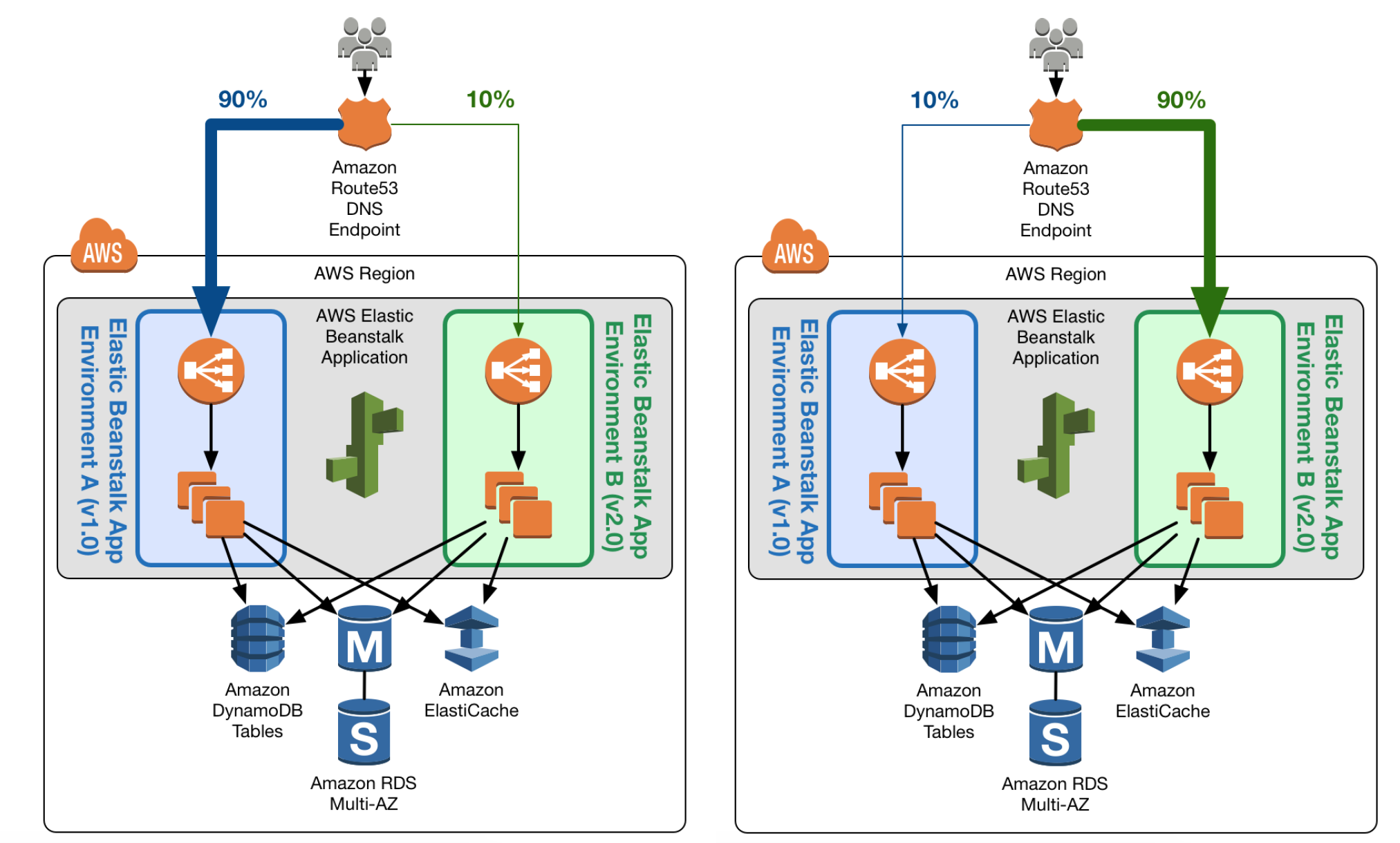
- Elastic Beanstalk multiple environment and environment url swap feature helps enable Blue Green deployment
- Elastic Beanstalk can be used to host the blue environment exposed via URL to access the environment
- Elastic Beanstalk provides several deployment policies, ranging from policies that perform an in-place update on existing instances, to immutable deployment using a set of new instances.
- Elastic Beanstalk performs an in-place update when the application versions are updated, however application may become unavailable to users for a short period of time.
- To avoid the downtime, a new version can be deployed to a separate Green environment with its own URL, launched with the existing environment’s configuration
- Elastic Beanstalk’s Swap Environment URLs feature can be used to promote the green environment to serve production traffic
- Elastic Beanstalk performs a DNS switch, which typically takes a few minutes
- To perform a rollback, invoke Swap Environment URL again.
Clone a Stack in AWS OpsWorks and Update DNS
- OpsWorks can be used to create
- Blue environment stack with the current version of the application and serving production traffic
- Green environment stack with the newer version of the application and is not receiving any traffic
- To promote to the green environment/stack into production, update DNS records to point to the green environment/stack’s load balancer
Labs
- Qwiklabs free labs
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- What is server immutability?
- Not updating a server after creation. (During the new release, a new set of EC2 instances are rolled out by terminating older instances and are disposable. EC2 instance usage is considered temporary or ephemeral in nature for the period of deployment until the current release is active)
- The ability to change server counts.
- Updating a server after creation.
- The inability to change server counts.
- You need to deploy a new application version to production. Because the deployment is high-risk, you need to roll the new version out to users over a number of hours, to make sure everything is working correctly. You need to be able to control the proportion of users seeing the new version of the application down to the percentage point. You use ELB and EC2 with Auto Scaling Groups and custom AMIs with your code pre-installed assigned to Launch Configurations. There are no database-level changes during your deployment. You have been told you cannot spend too much money, so you must not increase the number of EC2 instances much at all during the deployment, but you also need to be able to switch back to the original version of code quickly if something goes wrong. What is the best way to meet these requirements?
- Create a second ELB, Auto Scaling Launch Configuration, and Auto Scaling Group using the Launch Configuration. Create AMIs with all code pre-installed. Assign the new AMI to the second Auto Scaling Launch Configuration. Use Route53 Weighted Round Robin Records to adjust the proportion of traffic hitting the two ELBs. (Use Weighted Round Robin DNS Records and reverse proxies allow such fine-grained tuning of traffic splits. Blue-Green option does not meet the requirement that we mitigate costs and keep overall EC2 fleet size consistent, so we must select the 2 ELB and ASG option with WRR DNS tuning)
- Use the Blue-Green deployment method to enable the fastest possible rollback if needed. Create a full second stack of instances and cut the DNS over to the new stack of instances, and change the DNS back if a rollback is needed. (Full second stack is expensive)
- Create AMIs with all code pre-installed. Assign the new AMI to the Auto Scaling Launch Configuration, to replace the old one. Gradually terminate instances running the old code (launched with the old Launch Configuration) and allow the new AMIs to boot to adjust the traffic balance to the new code. On rollback, reverse the process by doing the same thing, but changing the AMI on the Launch Config back to the original code. (Cannot modify the existing launch config)
- Migrate to use AWS Elastic Beanstalk. Use the established and well-tested Rolling Deployment setting AWS provides on the new Application Environment, publishing a zip bundle of the new code and adjusting the wait period to spread the deployment over time. Re-deploy the old code bundle to rollback if needed.
- When thinking of AWS Elastic Beanstalk, the ‘Swap Environment URLs’ feature most directly aids in what?
- Immutable Rolling Deployments
- Mutable Rolling Deployments
- Canary Deployments
- Blue-Green Deployments (Complete switch from one environment to other)
- You were just hired as a DevOps Engineer for a startup. Your startup uses AWS for 100% of their infrastructure. They currently have no automation at all for deployment, and they have had many failures while trying to deploy to production. The company has told you deployment process risk mitigation is the most important thing now, and you have a lot of budget for tools and AWS resources. Their stack: 2-tier API Data stored in DynamoDB or S3, depending on type, Compute layer is EC2 in Auto Scaling Groups, They use Route53 for DNS pointing to an ELB, An ELB balances load across the EC2 instances. The scaling group properly varies between 4 and 12 EC2 servers. Which of the following approaches, given this company’s stack and their priorities, best meets the company’s needs?
- Model the stack in AWS Elastic Beanstalk as a single Application with multiple Environments. Use Elastic Beanstalk’s Rolling Deploy option to progressively roll out application code changes when promoting across environments. (Does not support DynamoDB also need Blue Green deployment for zero downtime deployment as cost is not a constraint)
- Model the stack in 3 CloudFormation templates: Data layer, compute layer, and networking layer. Write stack deployment and integration testing automation following Blue-Green methodologies.
- Model the stack in AWS OpsWorks as a single Stack, with 1 compute layer and its associated ELB. Use Chef and App Deployments to automate Rolling Deployment. (Does not support DynamoDB also need Blue Green deployment for zero downtime deployment as cost is not a constraint)
- Model the stack in 1 CloudFormation template, to ensure consistency and dependency graph resolution. Write deployment and integration testing automation following Rolling Deployment methodologies. (Need Blue Green deployment for zero downtime deployment as cost is not a constraint)
- You are building out a layer in a software stack on AWS that needs to be able to scale out to react to increased demand as fast as possible. You are running the code on EC2 instances in an Auto Scaling Group behind an ELB. Which application code deployment method should you use?
- SSH into new instances those come online, and deploy new code onto the system by pulling it from an S3 bucket, which is populated by code that you refresh from source control on new pushes. (is slow and manual)
- Bake an AMI when deploying new versions of code, and use that AMI for the Auto Scaling Launch Configuration. (Pre baked AMIs can help to get started quickly)
- Create a Dockerfile when preparing to deploy a new version to production and publish it to S3. Use UserData in the Auto Scaling Launch configuration to pull down the Dockerfile from S3 and run it when new instances launch. (is slow)
- Create a new Auto Scaling Launch Configuration with UserData scripts configured to pull the latest code at all times. (is slow)
- You company runs a complex customer relations management system that consists of around 10 different software components all backed by the same Amazon Relational Database (RDS) database. You adopted AWS OpsWorks to simplify management and deployment of that application and created an AWS OpsWorks stack with layers for each of the individual components. An internal security policy requires that all instances should run on the latest Amazon Linux AMI and that instances must be replaced within one month after the latest Amazon Linux AMI has been released. AMI replacements should be done without incurring application downtime or capacity problems. You decide to write a script to be run as soon as a new Amazon Linux AMI is released. Which solutions support the security policy and meet your requirements? Choose 2 answers
- Assign a custom recipe to each layer, which replaces the underlying AMI. Use AWS OpsWorks life-cycle events to incrementally execute this custom recipe and update the instances with the new AMI.
- Create a new stack and layers with identical configuration, add instances with the latest Amazon Linux AMI specified as a custom AMI to the new layer, switch DNS to the new stack, and tear down the old stack. (Blue-Green Deployment)
- Identify all Amazon Elastic Compute Cloud (EC2) instances of your AWS OpsWorks stack, stop each instance, replace the AMI ID property with the ID of the latest Amazon Linux AMI ID, and restart the instance. To avoid downtime, make sure not more than one instance is stopped at the same time.
- Specify the latest Amazon Linux AMI as a custom AMI at the stack level, terminate instances of the stack and let AWS OpsWorks launch new instances with the new AMI.
- Add new instances with the latest Amazon Linux AMI specified as a custom AMI to all AWS OpsWorks layers of your stack, and terminate the old ones.
- Your company runs an event management SaaS application that uses Amazon EC2, Auto Scaling, Elastic Load Balancing, and Amazon RDS. Your software is installed on instances at first boot, using a tool such as Puppet or Chef, which you also use to deploy small software updates multiple times per week. After a major overhaul of your software, you roll out version 2.0 new, much larger version of the software of your running instances. Some of the instances are terminated during the update process. What actions could you take to prevent instances from being terminated in the future? (Choose two)
- Use the zero downtime feature of Elastic Beanstalk to deploy new software releases to your existing instances. (No such feature, you can perform environment url swap)
- Use AWS CodeDeploy. Create an application and a deployment targeting the Auto Scaling group. Use CodeDeploy to deploy and update the application in the future. (Refer link)
- Run “aws autoscaling suspend-processes” before updating your application. (Refer link)
- Use the AWS Console to enable termination protection for the current instances. (Termination protection does not work with Auto Scaling)
- Run “aws autoscaling detach-load-balancers” before updating your application. (Does not prevent Auto Scaling to terminate the instances)