AWS Pricing Whitepaper Overview
AWS pricing features include
- Pay as you go
- No minimum contracts/commitments or long-term contracts required
- Pay only for services you use that can be stopped when not needed
- Each service is charged independently, providing flexibility to choose services as needed
- Pay less when you reserve
- some services like EC2 provide reserved capacity, which provide significantly discounted rate and increase in overall savings
- Pay even less by using more
- some services like storage and data services, the more the usage the less you pay per gigabyte
- consolidated billing to consolidate multiple accounts and get tiering benefits
- Pay even less as AWS grows
- AWS works continuously to reduce costs by reducing data center hardware costs, improving operational efficiencies, lowering power consumption, and generally lowering the cost of doing business
- Free services
- AWS offers lot of services free like AWS VPC, Elastic Beanstalk, CloudFormation, IAM, Auto Scaling, OpsWorks, Consolidated Billing
- Other features
- AWS Free Tier for new customers, which offer free usage of services within permissible limits
AWS Pricing Resources
- AWS Simple Monthly Calculator tool to effectively estimate the costs, which provides per service cost breakdown, as well as an aggregate monthly estimate.
- AWS Economic Center provides access to information, tools, and resources to compare the costs of AWS services with IT infrastructure alternatives.
- AWS Account Activity to view current charges and account activity, itemized by service and by usage type. Previous months’ billing statements are also available.
- AWS Usage Reports provides usage reports, specifying usage types, timeframe, service operations, and more can customize reports.
AWS Pricing Fundamental Characteristics
- AWS basically charges for
- Compute,
- Storage and
- Data Transfer Out – aggregated across EC2, S3, RDS, SimpleDB, SQS, SNS, and VPC and then charged at the outbound data transfer rate
- AWS does not charge
- Inbound data transfer across all AWS Services in all regions
- Outbound data transfer charges between AWS Services within the same region
AWS Elastic Cloud Compute – EC2
EC2 provides resizable compute capacity in cloud and the cost depends on –
- Clock Hours of Server Time
- Resources are charged for the time they are running
- AWS updated the EC2 billing from hourly basis to Per Second Billing (Circa Oct. 2017). It takes cost of unused minutes and seconds in an hour off of the bill, so the focus is on improving the applications instead of maximizing usage to the hour
- Machine Configuration
- Depends on the physical capacity and Instance pricing varies with the AWS region, OS, number of cores, and memory
- Machine Purchase Type
- On Demand instances – pay for compute capacity with no required minimum commitments
- Reserved Instances – option to make a low one-time payment – or no payment at all – for each reserved instance and in turn receive a significant discount on the usage
- Spot Instances – bid for unused EC2 capacity
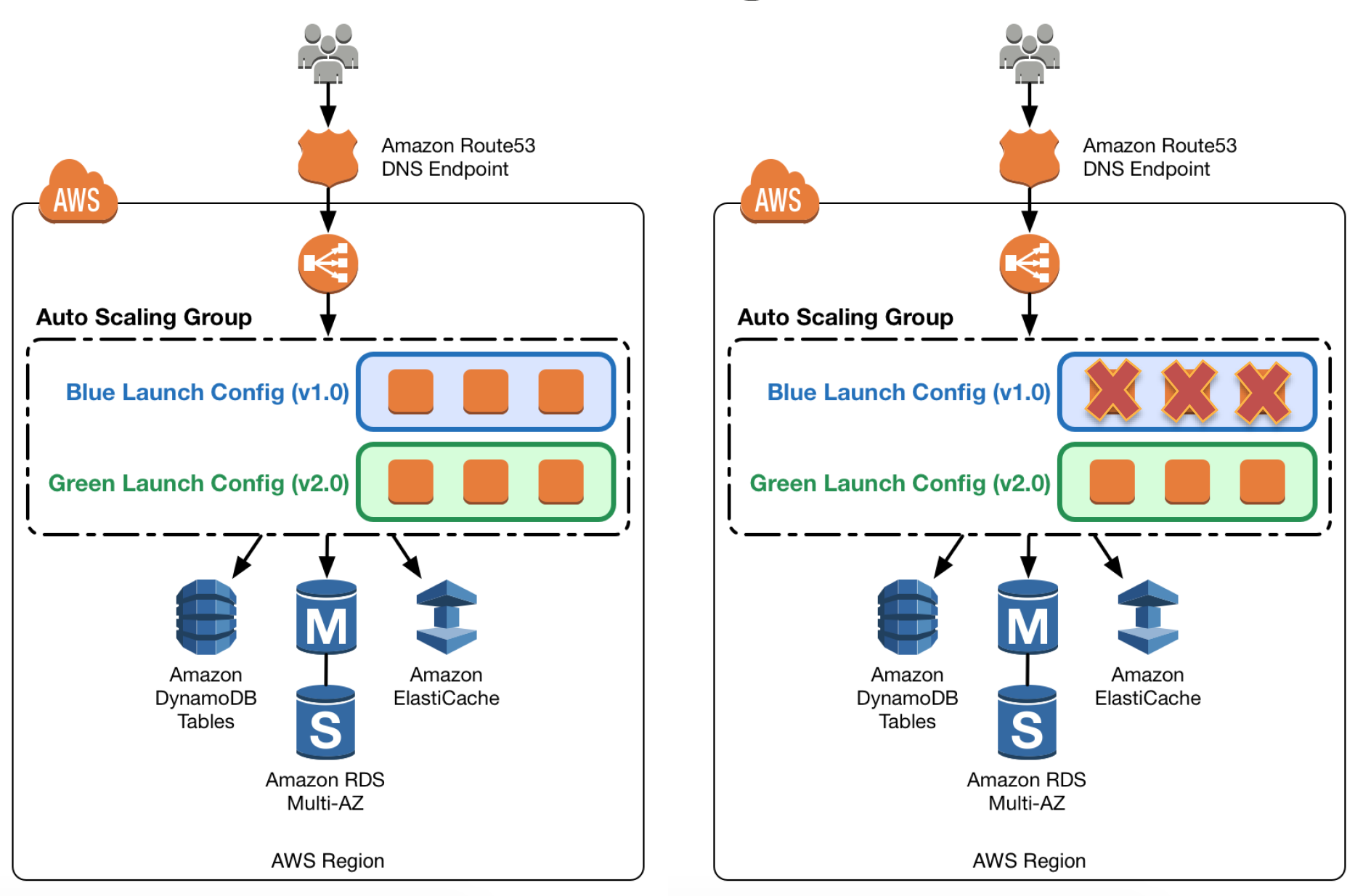
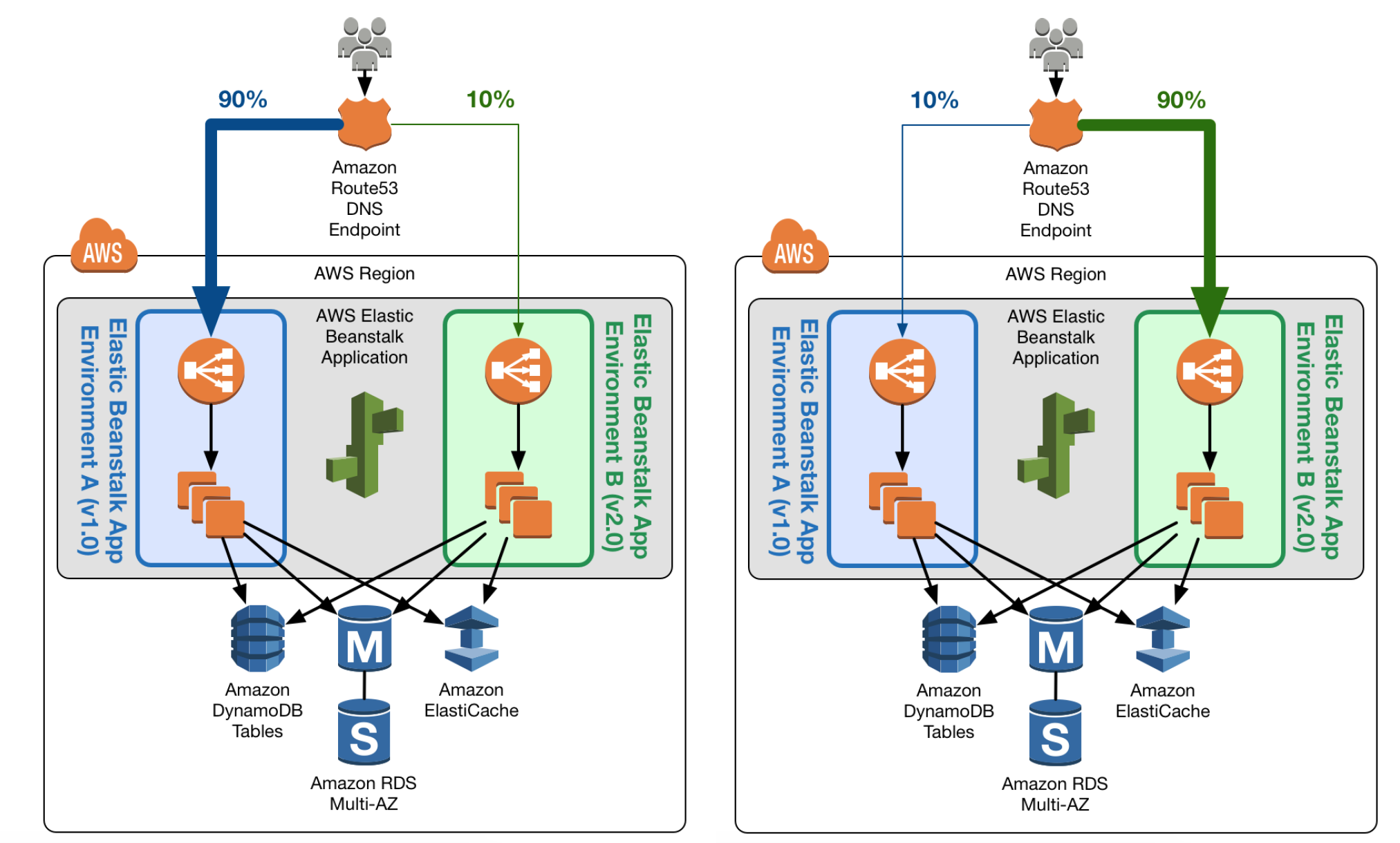
- Auto Scaling & Number of Instances
- Auto Scaling automatically adjusts the number of EC2 instances
- Load Balancing
- ELB can be used to distribute traffic among EC2 instances.
- Number of hours the ELB runs and the amount of data it processes contribute to the monthly cost.
- CloudWatch Detailed Monitoring
- Basic monitoring is enabled and available at no additional cost
- Detailed monitoring, which includes seven preselected metrics recorded once a minute, can be availed for a fixed monthly rate
- Partial months are charged on an hourly pro rata basis, at a per instance-hour rate
- Elastic IP Addresses
- Elastic IP addresses are charged only when are not associated with an instance
- Operating Systems and Software Packages
- OS prices are included in the instance prices. There are no additional licensing costs to run the following commercial OS: RHEL, SUSE Enterprise Linux, Windows Server and Oracle Enterprise Linux
- For unsupported commercial software packages, license needs to be obtained
AWS Lambda
AWS Lambda lets running code without provisioning or managing servers and the cost depends on
- Number of requests for the functions and the time for the code to execute
- Lambda registers a request each time it starts executing in response to an event notification or invoke call, including test invokes from the console.
- Charges are for the total number of requests across all the functions.
- Duration is calculated from the time the code begins executing until it returns or otherwise terminates, rounded up to the nearest 100 milliseconds.
- Price depends on the amount of memory allocated to the function.
AWS Simple Storage Service – S3
S3 provides object storage and the cost depends on
- Storage Class
- Each storage class has different rates and provide different capabilities
- Standard Storage is designed to provide 99.999999999% durability and 99.99% availability.
- Standard – Infrequent Access (SIA) is a storage option within S3 that you can use to reduce your costs by storing than Amazon S3’s standard storage.
- Standard – Infrequent Access for storing less frequently accessed data at slightly lower levels of redundancy, is designed to provide the same 99.999999999% durability as S3 with 99.9% availability in a given year.
- Storage
- Number and size of objects stored in the S3 buckets as well as type of storage.
- Requests
- Number and type of requests. GET requests incur charges at different rates than other requests, such as PUT and COPY requests.
- Data Transfer Out
- Amount of data transferred out of the S3 region.
AWS Elastic Block Store – EBS
EBS provides block level storage volumes and the cost depends on
- Volumes
- EBS provides three volume types: General Purpose (SSD), Provisioned IOPS (SSD), and Magnetic, charged by the amount provisioned in GB per month, until its released
- Input Output Operations per Second (IOPS)
- With General Purpose (SSD) volumes, I/O is included in the price
- With EBS Magnetic volumes, I/O is charged by the number of requests made to the volume
- With Provisioned IOPS (SSD) volumes, I/O is charged by the amount of provisioned, multiplied by the % of days provisioned for the month
- Data Transfer Out
- Amount of data transferred out of the application and outbound data transfer charges are tiered.
- Snapshot
- Snapshots of data to S3 are created for durable recovery. If opted for EBS snapshots, the added cost is per GB-month of data stored.
AWS Relational Database Service – RDS
RDS provides an easy to set up, operate, and scale a relational database in the cloud and the cost depends on
- Clock Hours of Server Time
- Resources are charged for the time they are running, from the time a DB instance is launched until terminated
- Database Characteristics
- Depends on the physical capacity and Instance pricing varies with the database engine, size, and memory class.
- Database Purchase Type
- On Demand instances – pay for compute capacity for each hour the DB Instance runs with no required minimum commitments
- Reserved Instances – option to make a low, one-time, up-front payment for each DB Instance to reserve for a 1-year or 3-year term and in turn receive a significant discount on the usage
- Number of Database Instances
- multiple DB instances can be provisioned to handle peak loads
- Provisioned Storage
- Backup storage of up to 100% of a provisioned database storage for an active DB Instance is not charged
- After the DB Instance is terminated, backup storage is billed per gigabyte per month.
- Additional Storage
- Amount of backup storage in addition to the provisioned storage amount is billed per gigabyte per month.
- Requests
- Number of input and output requests to the database.
- Deployment Type
- Storage and I/O charges vary, depending on the number of AZs the RDS is deployed – Single AZ or Multi-AZ
- Data Transfer Out
- Outbound data transfer costs are tiered.
- Inbound data transfer is free
AWS CloudFront
CloudFront is a web service for content delivery and an easy way to distribute content to end users with low latency, high data transfer speeds, and no required minimum commitments.
- Traffic Distribution
- Data transfer and request pricing vary across geographic regions, and pricing is based on edge location through which the content is served
- Requests
- Number and type of requests (HTTP or HTTPS) made and the geographic region in which the requests are made.
- Data Transfer Out
- Amount of data transferred out of the CloudFront edge locations
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- How does AWS charge for AWS Lambda?
- Users bid on the maximum price they are willing to pay per hour.
- Users choose a 1-, 3- or 5-year upfront payment term.
- Users pay for the required permanent storage on a file system or in a database.
- Users pay based on the number of requests and consumed compute resources.
References