AWS Certification Catalog
AWS Certification catalog for easy navigation to all the topics and resources
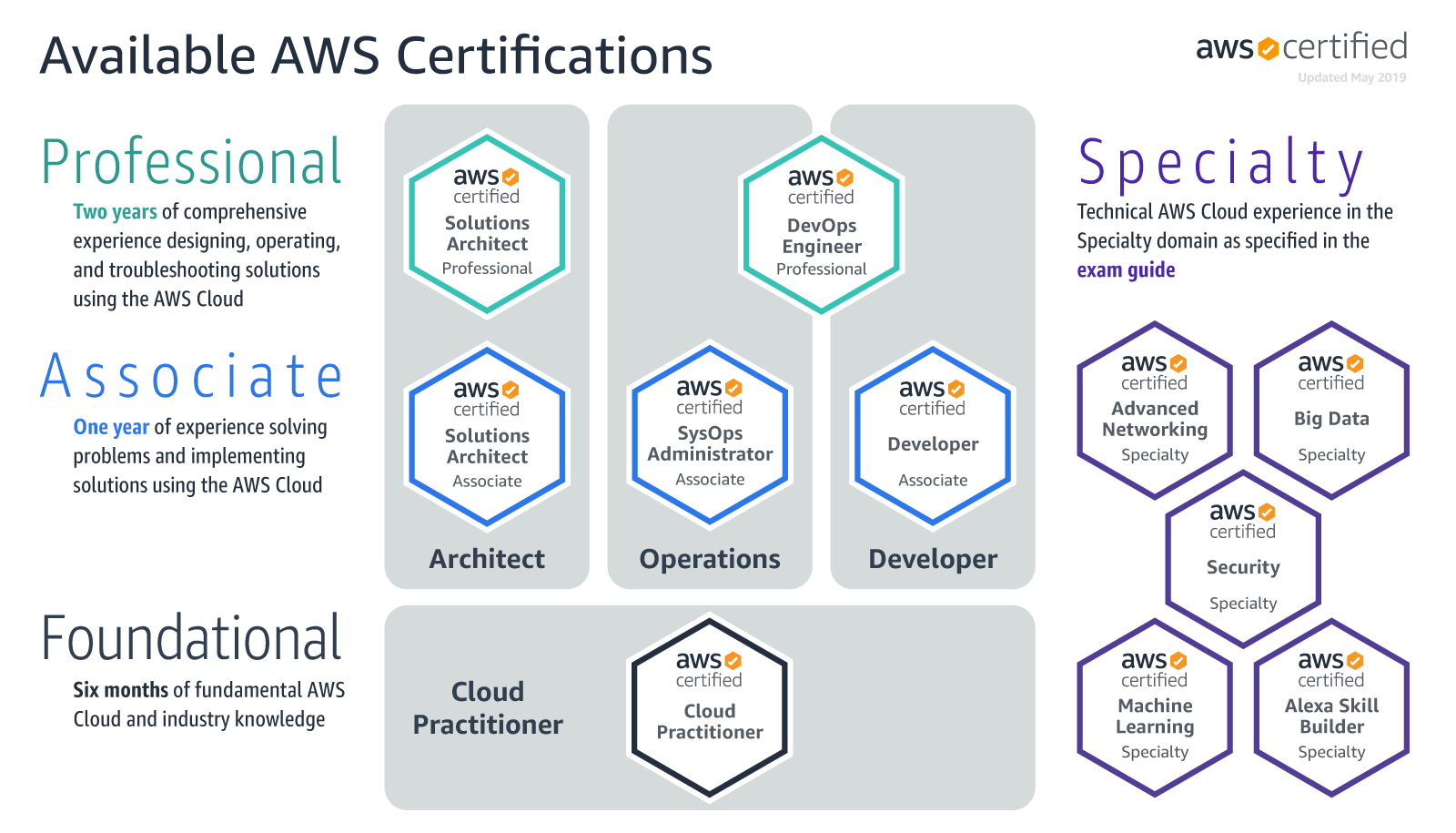
AWS Certification Exams Learning Path
- AWS Certified Cloud Practitioner – Learning path
- AWS Certified Solutions Architect – Associate (SAA-C03) learning path
- AWS Certified SysOps Administrator – Associate (SOA-C02) learning path
- AWS Certified Developer – Associate (DVA-C02) learning path
- AWS Certified Solution Architect – Professional (SAP-C02) learning path
- AWS Certified DevOps Engineer – Professional (DOP-C02 )learning path
- AWS Certified Advanced Networking – Specialty ANS-C01 learning path
- AWS Certified Security – Specialty (SCS-C02) learning path
- AWS Certified Data Analytics – Specialty (DAS-C01) learning path
- AWS Certified Machine Learning – Specialty (MLS-C01) learning path
- AWS Certified Database – Specialty (DBS-C01) Exam learning Path
- AWS Certified Alexa Skill Builder – Specialty (AXS-C01) Exam Learning Path
- AWS Certification Exam Resources, Courses, Quizzes
AWS Certification Courses & Practice Exams Coupons
AWS Services Cheat Sheet
- AWS Services Cheat Sheet
- AWS Identity Service Cheat Sheet
- AWS Security Services Cheat Sheet
- AWS Networking & Content Delivery Services Cheat Sheet
- AWS Compute Services Cheat Sheet
- AWS Storage Services Cheat Sheet
- AWS Database Services Cheat Sheet
- AWS Analytics Services Cheat Sheet
- AWS Application Services Cheat Sheet
- AWS Machine Learning Services Cheat Sheet
- AWS Management Tools Cheat Sheet
- AWS Alexa Cheat Sheet
AWS Whitepapers
- AWS Services Overview
- Architecting for the Cloud – Best Practices
- AWS Storage Options
- AWS High Availability & Fault Tolerance Architecture
- AWS Encrypting Data at Rest
- AWS Security
- AWS DDoS Resiliency – Best Practices
- AWS Disaster Recovery
- AWS Blue Green Deployment
- AWS Risk and Compliance
- AWS Cloud Migration
- AWS Cloud Migration Services
- AWS Network Connectivity Options
AWS Services
AWS Security, Identity & Compliance
- AWS IAM
- AWS Key Management Service – KMS
- AWS CloudHSM
- AWS Directory Services
- AWS Web Application Firewall – WAF
- AWS Intrusion Detection & Prevention System IDS/IPS
- Amazon Cognito
- Amazon GuardDuty
- Amazon Inspector
- Amazon Macie
- AWS Artifact
- AWS Shield
AWS Networking & Content Delivery
- AWS Virtual Private Cloud
- AWS Elastic Load Balancing – ELB
- AWS Route 53 Overview
- AWS API Gateway
- AWS CloudFront
- AWS Direct Connect – DX
- AWS Transit VPC
- AWS Transit Gateway
- AWS Global Accelerator
- AWS PrivateLink
AWS Compute Services
- AWS Elastic Cloud Compute – EC2
- AWS EC2 Amazon Machine Image
- AWS EC2 Instance Types
- AWS EC2 Instance Purchase Options
- AWS EC2 Instance Lifecycle
- AWS EC2 Instance Metadata – Userdata
- AWS EC2 – Placement Groups
- AWS EC2 VM Import/Export
- AWS EC2 Network – Enhanced Networking
- AWS EC2 Network
- AWS EC2 Security
- AWS EC2 Best Practices
- AWS EC2 Monitoring
- AWS EC2 Troubleshooting
- AWS Auto Scaling & ELB
- AWS EC2 Auto Scaling
- AWS Lambda
- AWS Elastic Beanstalk
- Amazon Elastic Container Service
- Amazon Elastic Kubernetes Service
- Amazon Lightsail
- AWS Fargate
AWS Storage Services
- AWS Simple Storage Service – S3
- AWS EC2 Storage
- AWS Storage Gateway
- AWS S3 Glacier
- AWS Snow Family
- AWS Elastic File System
AWS Database Services
AWS Application Integration Services
- AWS Step Functions
- AWS SQS
- AWS Simple Notification Service – SNS
- AWS Simple Email Service – SES
AWS Management & Governance
- AWS CloudWatch
- AWS CloudTrail
- AWS CloudFormation
- AWS Trusted Advisor
- AWS Config
- AWS OpsWorks
- AWS Service Catalog
- AWS Organizations
- AWS Systems Manager
- AWS Billing and Cost Management
- AWS Interaction Tools
- AWS Elastic Beanstalk vs OpsWorks vs CloudFormation
- AWS Personal Health Dashboard
- AWS Well-Architected Tool
AWS Migration & Transfer Services
AWS Analytics Services
- AWS Kinesis
- AWS Elasticsearch
- AWS CloudSearch
- AWS Data Pipeline
- AWS Elastic Map Reduce – EMR
- AWS SWF – Simple Workflow Overview
- Amazon Athena
- Amazon QuickSight
- AWS Glue
AWS Machine Learning Services
AWS Developer Tools
AWS Media Services
- AWS Elastic Transcoder
- Amazon Kinesis Video Streams
AWS End User Computing Services
- AWS WorkSpace
- Amazon AppStream 2.0
AWS Other Features
- AWS Regions, Availability Zones and Edge Locations
- AWS Services with Root Privileges
- AWS Tags – Resource Groups – Tag Editor
- AWS Automated Backups
- AWS Support Tiers
Google Cloud Certification Catalog
Google Certification Exams Learning Path
- Google Cloud Certification Catalog
- Google Cloud Certified – Associate Cloud Engineer learning path
- Google Cloud Certified – Professional Cloud Architect learning path
- Google Cloud Certified – Professional Data Engineer learning path
- Google Cloud Certified – Professional Cloud Network Engineer learning path
- Google Cloud Certified – Professional Cloud Security Engineer learning path
- Google Cloud Certified – Professional Cloud Developer learning path
- Google Cloud Certified – Professional Cloud DevOps Engineer learning path
- Google Cloud Services Cheat Sheet
Kubernetes Certification Catalog
CCNF Kubernetes Exams Learning Path
- Certified Kubernetes Application Developer CKAD learning path
- Certified Kubernetes Administrator CKA learning path
- Certified Kubernetes Security Specialist learning path