Table of Contents
hide
AWS S3 Storage Classes
- AWS S3 offers a range of S3 Storage Classes to match the use case scenario and performance access requirements.
- S3 storage classes are designed to sustain the concurrent loss of data in one or two facilities.
- S3 storage classes allow lifecycle management for automatic transition of objects for cost savings.
- All S3 storage classes provide the same durability, first-byte latency, and support SSL encryption of data in transit, and data encryption at rest.
- S3 also regularly verifies the integrity of the data using checksums and provides the auto-healing capability.
S3 Storage Classes Comparison
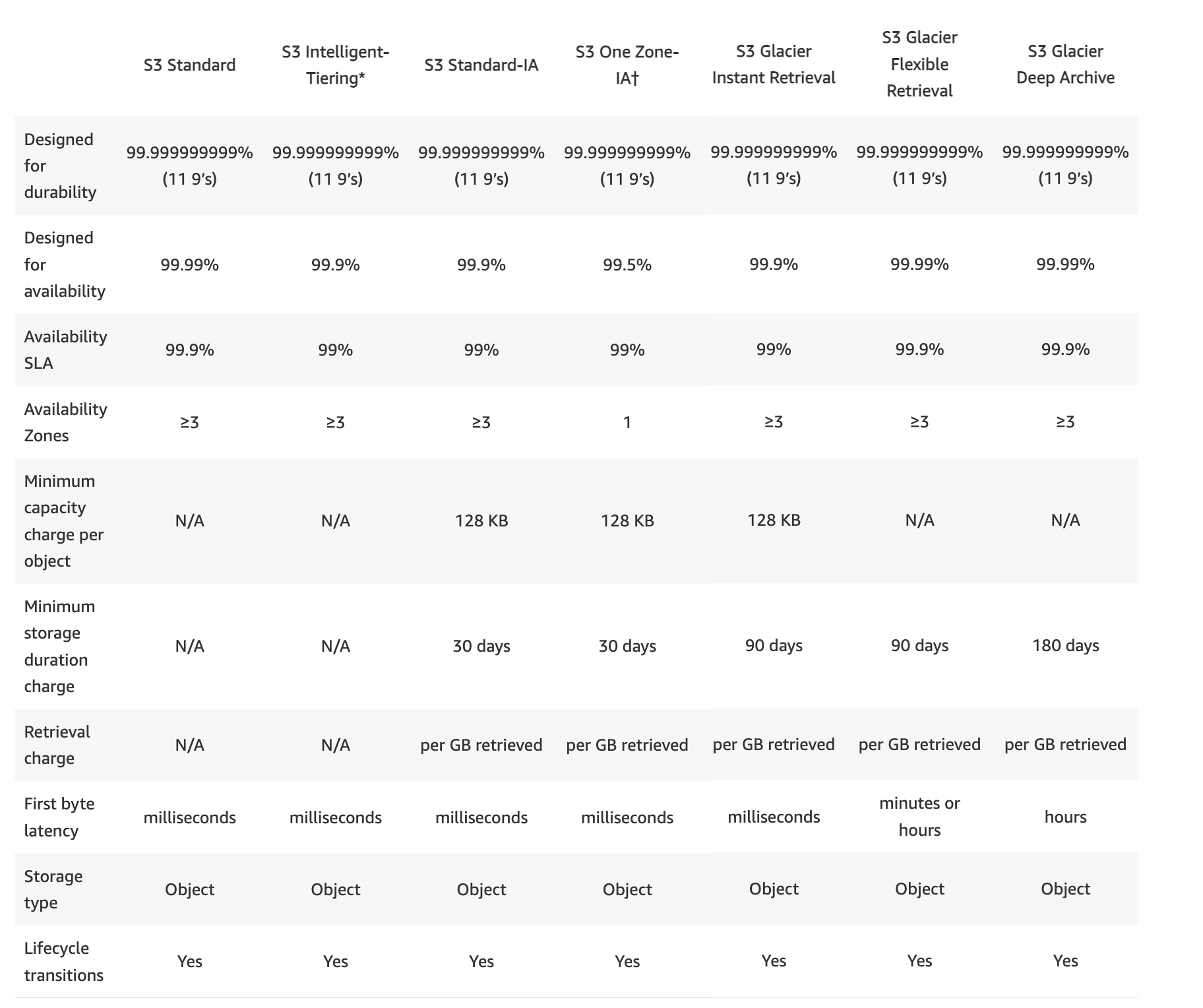
S3 Standard
- STANDARD is the default storage class, if none specified during upload
- Low latency and high throughput performance
- Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
- Designed for 99.99% availability over a given year
- Resilient against events that impact an entire Availability Zone and is designed to sustain the loss of data in a two facilities
- Ideal for performance-sensitive use cases and frequently accessed data
- S3 Standard is appropriate for a wide variety of use cases, including cloud applications, dynamic websites, content distribution, mobile and gaming applications, and big data analytics.
S3 Intelligent Tiering (S3 Intelligent-Tiering)
- S3 Intelligent Tiering storage class is designed to optimize storage costs by automatically moving data to the most cost-effective storage access tier, without performance impact or operational overhead.
- Delivers automatic cost savings by moving data on a granular object-level between two access tiers
- one tier that is optimized for frequent access and
- another lower-cost tier that is optimized for infrequently accessed data.
- a frequent access tier and a lower-cost infrequent access tier, when access patterns change.
- Ideal to optimize storage costs automatically for long-lived data when access patterns are unknown or unpredictable.
- For a small monthly monitoring and automation fee per object, S3 monitors access patterns of the objects and moves objects that have not been accessed for 30 consecutive days to the infrequent access tier.
- There are no separate retrieval fees when using the Intelligent Tiering storage class. If an object in the infrequent access tier is accessed, it is automatically moved back to the frequent access tier.
- No additional fees apply when objects are moved between access tiers
- Suitable for objects greater than 128 KB (smaller objects are charged for 128 KB only) kept for at least 30 days (charged for a minimum of 30 days)
- Same low latency and high throughput performance of S3 Standard
- Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
- Designed for 99.9% availability over a given year
S3 Standard-Infrequent Access (S3 Standard-IA)
- S3 Standard-Infrequent Access storage class is optimized for long-lived and less frequently accessed data. for e.g. for backups and older data where access is limited, but the use case still demands high performance
- Ideal for use for the primary or only copy of data that can’t be recreated.
- Data stored redundantly across multiple geographically separated AZs and are resilient to the loss of an Availability Zone.
- offers greater availability and resiliency than the ONEZONE_IA class.
- Objects are available for real-time access.
- Suitable for larger objects greater than 128 KB (smaller objects are charged for 128 KB only) kept for at least 30 days (charged for minimum 30 days)
- Same low latency and high throughput performance of Standard
- Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
- Designed for 99.9% availability over a given year
- S3 charges a retrieval fee for these objects, so they are most suitable for infrequently accessed data.
S3 One Zone-Infrequent Access (S3 One Zone-IA)
- S3 One Zone-Infrequent Access storage classes are designed for long-lived and infrequently accessed data, but available for millisecond access (similar to the STANDARD and STANDARD_IA storage class).
- Ideal when the data can be recreated if the AZ fails, and for object replicas when setting cross-region replication (CRR).
- Objects are available for real-time access.
- Suitable for objects greater than 128 KB (smaller objects are charged for 128 KB only) kept for at least 30 days (charged for a minimum of 30 days)
- Stores the object data in only one AZ, which makes it less expensive than Standard-Infrequent Access
- Data is not resilient to the physical loss of the AZ resulting from disasters, such as earthquakes and floods.
- One Zone-Infrequent Access storage class is as durable as Standard-Infrequent Access, but it is less available and less resilient.
- Designed for 99.999999999% i.e. 11 9’s Durability of objects in a single AZ
- Designed for 99.5% availability over a given year
- S3 charges a retrieval fee for these objects, so they are most suitable for infrequently accessed data.
Reduced Redundancy Storage – RRS
- NOTE – AWS recommends not to use this storage class. The STANDARD storage class is more cost-effective now.
- Reduced Redundancy Storage (RRS) storage class is designed for non-critical, reproducible data stored at lower levels of redundancy than the STANDARD storage class, which reduces storage costs
- Designed for durability of 99.99% of objects
- Designed for 99.99% availability over a given year
- Lower level of redundancy results in less durability and availability
- RRS stores object on multiple devices across multiple facilities, providing 400 times the durability of a typical disk drive,
- RRS does not replicate objects as many times as S3 standard storage and is designed to sustain the loss of data in a single facility.
- If an RRS object is lost, S3 returns a 405 error on requests made to that object
- S3 can send an event notification, configured on the bucket, to alert a user or start a workflow when it detects that an RRS object is lost which can be used to replace the lost object
S3 Glacier Instant Retrieval
- Use for archiving data that is rarely accessed and requires milliseconds retrieval.
- Storage class has a minimum storage duration period of 90 days
- Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
- Designed for 99.99% availability
S3 Glacier Flexible Retrieval – S3 Glacier
- S3 GLACIER storage class is suitable for low-cost data archiving where data access is infrequent and retrieval time of minutes to hours is acceptable.
- Storage class has a minimum storage duration period of 90 days
- Provides configurable retrieval times, from minutes to hours
- Expedited retrieval: 1-5 mins
- Standard retrieval: 3-5 hours
- Bulk retrieval: 5-12 hours
- GLACIER storage class uses the very low-cost Glacier storage service, but the objects in this storage class are still managed through S3
- For accessing GLACIER objects,
- the object must be restored which can take anywhere between minutes to hours
- objects are only available for the time period (the number of days) specified during the restoration request
- object’s storage class remains GLACIER
- charges are levied for both the archive (GLACIER rate) and the copy restored temporarily
- Vault Lock feature enforces compliance via a lockable policy.
- Offers the same durability and resiliency as the STANDARD storage class
- Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
- Designed for 99.99% availability
S3 Glacier Deep Archive
- Glacier Deep Archive storage class provides the lowest-cost data archiving where data access is infrequent and retrieval time of hours is acceptable.
- Has a minimum storage duration period of 180 days and can be accessed at a default retrieval time of 12 hours.
- Supports long-term retention and digital preservation for data that may be accessed once or twice a year
- Designed for 99.999999999% i.e. 11 9’s Durability of objects across AZs
- Designed for 99.9% availability over a given year
- DEEP_ARCHIVE retrieval costs can be reduced by using bulk retrieval, which returns data within 48 hours.
- Ideal alternative to magnetic tape libraries
S3 Analytics – S3 Storage Classes Analysis
- S3 Analytics – Storage Class Analysis helps analyze storage access patterns to decide when to transition the right data to the right storage class.
- S3 Analytics feature observes data access patterns to help determine when to transition less frequently accessed STANDARD storage to the STANDARD_IA (IA, for infrequent access) storage class.
- Storage Class Analysis can be configured to analyze all the objects in a bucket or filters to group objects.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- What does RRS stand for when talking about S3?
- Redundancy Removal System
- Relational Rights Storage
- Regional Rights Standard
- Reduced Redundancy Storage
- What is the durability of S3 RRS?
- 99.99%
- 99.95%
- 99.995%
- 99.999999999%
- What is the Reduced Redundancy option in Amazon S3?
- Less redundancy for a lower cost
- It doesn’t exist in Amazon S3, but in Amazon EBS.
- It allows you to destroy any copy of your files outside a specific jurisdiction.
- It doesn’t exist at all
- An application is generating a log file every 5 minutes. The log file is not critical but may be required only for verification in case of some major issue. The file should be accessible over the internet whenever required. Which of the below mentioned options is a best possible storage solution for it?
- AWS S3
- AWS Glacier
- AWS RDS
- AWS S3 RRS (Reduced Redundancy Storage (RRS) is an Amazon S3 storage option that enables customers to store noncritical, reproducible data at lower levels of redundancy than Amazon S3’s standard storage. RRS is designed to sustain the loss of data in a single facility.)
- A user has moved an object to Glacier using the life cycle rules. The user requests to restore the archive after 6 months. When the restore request is completed the user accesses that archive. Which of the below mentioned statements is not true in this condition?
- The archive will be available as an object for the duration specified by the user during the restoration request
- The restored object’s storage class will be RRS (After the object is restored the storage class still remains GLACIER. Read more)
- The user can modify the restoration period only by issuing a new restore request with the updated period
- The user needs to pay storage for both RRS (restored) and Glacier (Archive) Rates
- Your department creates regular analytics reports from your company’s log files. All log data is collected in Amazon S3 and processed by daily Amazon Elastic Map Reduce (EMR) jobs that generate daily PDF reports and aggregated tables in CSV format for an Amazon Redshift data warehouse. Your CFO requests that you optimize the cost structure for this system. Which of the following alternatives will lower costs without compromising average performance of the system or data integrity for the raw data? [PROFESSIONAL]
- Use reduced redundancy storage (RRS) for PDF and CSV data in Amazon S3. Add Spot instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift. (Spot instances impacts performance)
- Use reduced redundancy storage (RRS) for all data in S3. Use a combination of Spot instances and Reserved Instances for Amazon EMR jobs. Use Reserved instances for Amazon Redshift (Combination of the Spot and reserved with guarantee performance and help reduce cost. Also, RRS would reduce cost and guarantee data integrity, which is different from data durability )
- Use reduced redundancy storage (RRS) for all data in Amazon S3. Add Spot Instances to Amazon EMR jobs. Use Reserved Instances for Amazon Redshift (Spot instances impacts performance)
- Use reduced redundancy storage (RRS) for PDF and CSV data in S3. Add Spot Instances to EMR jobs. Use Spot Instances for Amazon Redshift. (Spot instances impacts performance)
- Which of the below mentioned options can be a good use case for storing content in AWS RRS?
- Storing mission critical data Files
- Storing infrequently used log files
- Storing a video file which is not reproducible
- Storing image thumbnails
- A newspaper organization has an on-premises application which allows the public to search its back catalogue and retrieve individual newspaper pages via a website written in Java. They have scanned the old newspapers into JPEGs (approx. 17TB) and used Optical Character Recognition (OCR) to populate a commercial search product. The hosting platform and software is now end of life and the organization wants to migrate its archive to AWS and produce a cost efficient architecture and still be designed for availability and durability. Which is the most appropriate? [PROFESSIONAL]
- Use S3 with reduced redundancy to store and serve the scanned files, install the commercial search application on EC2 Instances and configure with auto-scaling and an Elastic Load Balancer. (RRS impacts durability and commercial search would add to cost)
- Model the environment using CloudFormation. Use an EC2 instance running Apache webserver and an open source search application, stripe multiple standard EBS volumes together to store the JPEGs and search index. (Using EBS is not cost effective for storing files)
- Use S3 with standard redundancy to store and serve the scanned files, use CloudSearch for query processing, and use Elastic Beanstalk to host the website across multiple availability zones. (Standard S3 and Elastic Beanstalk provides availability and durability, Standard S3 and CloudSearch provides cost effective storage and search)
- Use a single-AZ RDS MySQL instance to store the search index and the JPEG images use an EC2 instance to serve the website and translate user queries into SQL. (RDS is not ideal and cost effective to store files, Single AZ impacts availability)
- Use a CloudFront download distribution to serve the JPEGs to the end users and Install the current commercial search product, along with a Java Container for the website on EC2 instances and use Route53 with DNS round-robin. (CloudFront needs a source and using commercial search product is not cost effective)
- A research scientist is planning for the one-time launch of an Elastic MapReduce cluster and is encouraged by her manager to minimize the costs. The cluster is designed to ingest 200TB of genomics data with a total of 100 Amazon EC2 instances and is expected to run for around four hours. The resulting data set must be stored temporarily until archived into an Amazon RDS Oracle instance. Which option will help save the most money while meeting requirements? [PROFESSIONAL]
- Store ingest and output files in Amazon S3. Deploy on-demand for the master and core nodes and spot for the task nodes.
- Optimize by deploying a combination of on-demand, RI and spot-pricing models for the master, core and task nodes. Store ingest and output files in Amazon S3 with a lifecycle policy that archives them to Amazon Glacier. (Master and Core must be RI or On Demand. Cannot be Spot)
- Store the ingest files in Amazon S3 RRS and store the output files in S3. Deploy Reserved Instances for the master and core nodes and on-demand for the task nodes. (Need better durability for ingest file. Spot instances can be used for task nodes for cost saving.)
- Deploy on-demand master, core and task nodes and store ingest and output files in Amazon S3 RRS (Input must be in S3 standard)
Question(2) answer is missing and it should be 99.99 since it’s RRS
https://aws.amazon.com/s3/reduced-redundancy/
Thanks, added the answer
An application is generating a log file every 5 minutes. The log file is not critical but may be required only for verification in case of some major issue. The file should be accessible over the internet whenever required. Which of the below mentioned options is a best possible storage solution for it?
I think Answer should be AWS S3 though the log file is not critical but it is required for verification and it should be accessible from internet(ussing RRS can delete the file)
RRS is used for files that are usually no critical or reproducible. In this case the file is not critical. Also with RRS, the file is still stored in 2 facilities and RRS is designed to sustain the loss of data in a single facility.
RRS is recommended for reproducible data. So, it’s OK for CVS and PDF, but not OK for the original logs. It may lead to data loss, which is part of data integrity concept. I agree with Raj that the correct answer is A.
Integrity is more to check data corruption which is verified using checksums. Durability is the loss of data. RRS provided the same integrity as as other storage classes.
6. Your department creates regular analytics reports from your company’s log files. All log data is collected in Amazon S3 and processed by daily Amazon Elastic Map Reduce (EMR) jobs that generate daily PDF reports and aggregated tables in CSV format for an Amazon Redshift data warehouse. Your CFO requests that you optimize the cost structure for this system. Which of the following alternatives will lower costs without compromising average performance of the system or data integrity for the raw data?
Question 6 : Answer should be A as we cannot store all data files in RRS as log files cannot be reproduced.
Question targets data integrity and not durability, RRS provides the same data integrity checks as Standard. Only Spot instances would not work for EMR and it would be impact average performance as it is not guaranteed.
Please include s3 Zone IA storage class concepts
will include the same ..
Hi Jayendra,
First of all, many thanks for sharing your knowledge through this brilliant blog, it is very helpful and enjoyable to read.
would like to hear your thoughts on Q5 above,
What exactly they referring to by the “restored object” in choice-b ? It is bit confusing though, whether it is the “temporary copy” restored to RRS, or the original object in Glacier. To me, it feels like it is the restored temporary copy in RRS, and this may not be the correct answer in that case. The choice-c looks to be the correct answer to this question.
It can be a bit confusing but the restored object is the actual object. Once restored they refer it as a temporary copy of the object.
Thank you very much for the clarification, Jayendra.
Is choice-C also a correct answer to this question,no?
I agree with the answer, but your explanation for 9e is tripping me up:
“RI will not provide cost saving in this case”
How won’t RI on the master and core nodes provide cost savings?
Thanks
Thanks Philip, agreed the comment does not apply for the answer. Edited the same.
Hi Jayendra, Q7 how about b – Infrequently accessed log files. This would also be a good candidate for RRS right?
RRS is not for infrequent but for non-critical, reproducible objects. It would be if it is non-critical and fine if is lost which is not clear. However, thumbnails is reproducible and you can reproduce it even if you lose it.
Looks like now you can directly upload a file to Glacier. Just did it via console.
Yup its allowed now with the latest enhancements. Even the retrievals have undergone quite a lot of changes.