S3 Object lifecycle can be managed by using a lifecycle configuration, which defines how S3 manages objects during their lifetime.
Lifecycle configuration enables simplification of object lifecycle management, for e.g. moving of less frequently access objects, backup or archival of data for several years, or permanent deletion of objects,
S3 controls all transitions automatically
Lifecycle Management rules applied to a bucket are applicable to all the existing objects in the bucket as well as the ones that will be added anew
S3 Object lifecycle management allows 2 types of behavior
Transition in which the storage class for the objects changes
Expiration where the objects expire and are permanently deleted
Lifecycle Management can be configured with Versioning, which allows storage of one current object version and zero or more non-current object versions
Object’s lifecycle management applies to both Non Versioning and Versioning enabled buckets
For Non Versioned buckets
Transitioning period is considered from the object’s creation date
For Versioned buckets,
Transitioning period for the current object is calculated for the object creation date
Transitioning period for a non-current object is calculated for the date when the object became a noncurrent versioned object
S3 uses the number of days since its successor was created as the number of days an object is noncurrent.
S3 calculates the time by adding the number of days specified in the rule to the object creation time and rounding the resulting time to the next day midnight UTC for e.g. if an object was created at 15/1/2016 10:30 AM UTC and you specify 3 days in a transition rule, which results in 18/1/2016 10:30 AM UTC and rounded of to next day midnight time 19/1/2016 00:00 UTC.
Lifecycle configuration on MFA-enabled buckets is not supported.
1000 lifecycle rules can be configured per bucket
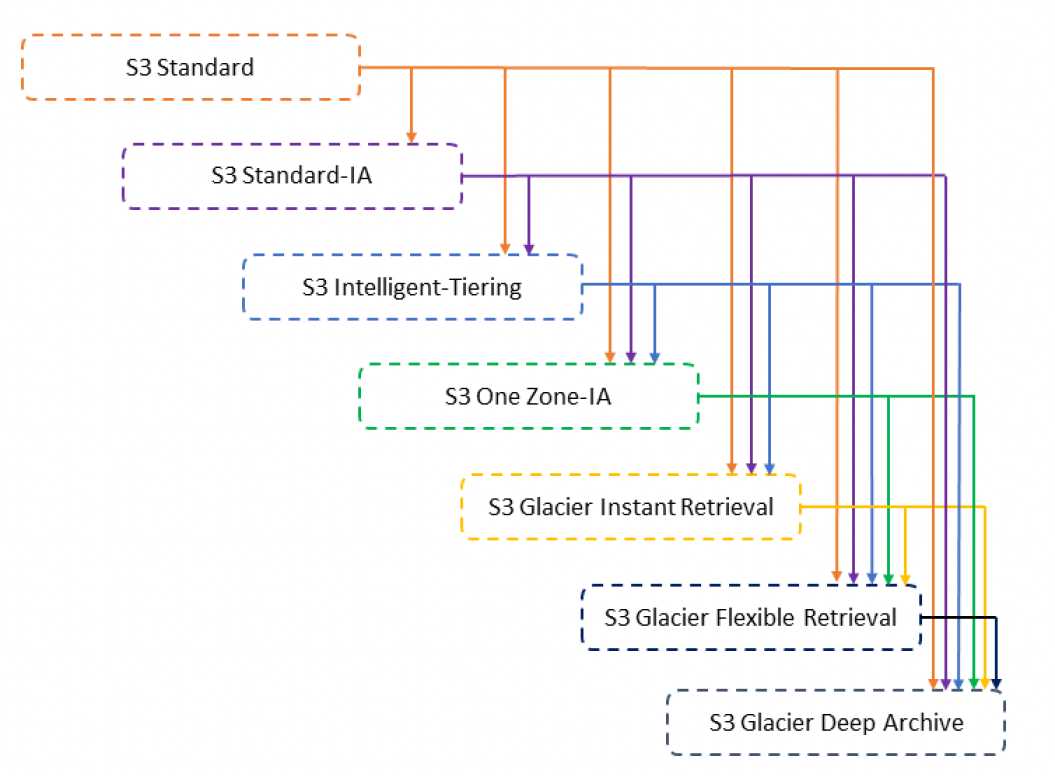
S3 Object Lifecycle Management Rules
Lifecycle Transitions Constraints
STANDARD -> (128 KB & 30 days) -> STANDARD-IA or One Zone-IA or S3 Intelligent-Tiering
Larger Objects – Only objects with a size more than 128 KB can be transitioned, as cost benefits for transitioning to STANDARD-IA or One Zone-IA can be realized only for larger objects
Smaller Objects < 128 KB – S3 does not transition objects that are smaller than 128 KB
Minimum 30 days – Objects must be stored for at least 30 days in the current storage class before being transitioned to the STANDARD-IA or One Zone-IA, as younger objects are accessed more frequently or deleted sooner than is suitable for STANDARD-IA or One Zone-IA
GLACIER -> (90 days) -> Permanent Deletion OR GLACIER Deep Archive -> (180 days) -> Permanent Deletion
Deleting data that is archived to Glacier is free if the objects deleted are archived for three months or longer.
S3 charges a prorated early deletion fee if the object is deleted or overwritten within three months of archiving it.
Archival of objects to Glacier by using object lifecycle management is performed asynchronously and there may be a delay between the transition date in the lifecycle configuration rule and the date of the physical transition. However, AWS charges Glacier prices based on the transition date specified in the rule
For a versioning-enabled bucket
Transition and Expiration actions apply to current versions.
NoncurrentVersionTransition and NoncurrentVersionExpiration actions apply to noncurrent versions and work similarly to the non-versioned objects except the time period is from the time the objects became noncurrent
Expiration Rules
For Non Versioned bucket
Object is permanently deleted
For Versioned bucket
Expiration is applicable to the Current object only and does not impact any of the non-current objects
S3 will insert a Delete Marker object with a unique id and the previous current object becomes a non-current version
S3 will not take any action if the Current object is a Delete Marker
If the bucket has a single object which is the Delete Marker (referred to as expired object delete marker), S3 removes the Delete Marker
For Versioned Suspended bucket
S3 will insert a Delete Marker object with version ID null and overwrite any object with version ID null
When an object reaches the end of its lifetime, S3 queues it for removal and removes it asynchronously. There may be a delay between the expiration date and the date at which S3 removes an object. Charged for storage time associated with an object that has expired are not incurred.
Cost is incurred if objects are expired in STANDARD-IA before 30 days, GLACIER before 90 days, and GLACIER_DEEP_ARCHIVE before 180 days.
AWS Certification Exam Practice Questions
Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
Open to further feedback, discussion and correction.
If an object is stored in the Standard S3 storage class and you want to move it to Glacier, what must you do in order to properly migrate it?
Change the storage class directly on the object.
Delete the object and re-upload it, selecting Glacier as the storage class.
None of the above.
Create a lifecycle policy that will migrate it after a minimum of 30 days. (Any object uploaded to S3 must first be placed into either the Standard, Reduced Redundancy, or Infrequent Access storage class. Once in S3 the only way to move the object to glacier is through a lifecycle policy)
A company wants to store their documents in AWS. Initially, these documents will be used frequently, and after a duration of 6 months, they would not be needed anymore. How would you architect this requirement?
Store the files in Amazon EBS and create a Lifecycle Policy to remove the files after 6 months.
Store the files in Amazon S3 and create a Lifecycle Policy to remove the files after 6 months.
Store the files in Amazon Glacier and create a Lifecycle Policy to remove the files after 6 months.
Store the files in Amazon EFS and create a Lifecycle Policy to remove the files after 6 months.
Your firm has uploaded a large amount of aerial image data to S3. In the past, in your on-premises environment, you used a dedicated group of servers to oaten process this data and used Rabbit MQ, an open source messaging system, to get job information to the servers. Once processed the data would go to tape and be shipped offsite. Your manager told you to stay with the current design, and leverage AWS archival storage and messaging services to minimize cost. Which is correct?
Use SQS for passing job messages, use Cloud Watch alarms to terminate EC2 worker instances when they become idle. Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage (Need to replace On-Premises Tape functionality)
Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS. Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage (Need to replace On-Premises Tape functionality)
Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS. Once data is processed, change the storage class of the S3 objects to Glacier (Glacier suitable for Tape backup)
Use SNS to pass job messages use Cloud Watch alarms to terminate spot worker instances when they become idle. Once data is processed, change the storage class of the S3 object to Glacier.
You have a proprietary data store on-premises that must be backed up daily by dumping the data store contents to a single compressed 50GB file and sending the file to AWS. Your SLAs state that any dump file backed up within the past 7 days can be retrieved within 2 hours. Your compliance department has stated that all data must be held indefinitely. The time required to restore the data store from a backup is approximately 1 hour. Your on-premise network connection is capable of sustaining 1gbps to AWS. Which backup methods to AWS would be most cost-effective while still meeting all of your requirements?
Send the daily backup files to Glacier immediately after being generated (will not meet the RTO)
Transfer the daily backup files to an EBS volume in AWS and take daily snapshots of the volume (Not cost effective)
Transfer the daily backup files to S3 and use appropriate bucket lifecycle policies to send to Glacier (Store in S3 for seven days and then archive to Glacier)
Host the backup files on a Storage Gateway with Gateway-Cached Volumes and take daily snapshots (Not Cost-effective as local storage as well as S3 storage)
20 thoughts on “AWS S3 Object Lifecycle Management”
Your firm has uploaded a large amount of aerial image data to S3. In the past, in your on-premises environment, you used a dedicated group of servers to oaten process this data and used Rabbit MQ, an open source messaging system, to get job information to the servers. Once processed the data would go to tape and be shipped offsite. Your manager told you to stay with the current design, and leverage AWS archival storage and messaging services to minimize cost. Which is correct?
Use SQS for passing job messages, use Cloud Watch alarms to terminate EC2 worker instances when they become idle. Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage (Need to replace On-Premises Tape functionality)
Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS. Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage (Need to replace On-Premises Tape functionality)
Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS. Once data is processed, change the storage class of the S3 objects to Glacier (Glacier suitable for Tape backup)
Use SNS to pass job messages use Cloud Watch alarms to terminate spot worker instances when they become idle. Once data is processed, change the storage class of the S3 object to Glacier.
Please explain why last option is not suitable.
Key point is to stay with the current design, so using SQS for Rabbit MQ makes sense. Also the last option has missing pieces, it wouldn’t work as mentioned.
Question: 2 Says “The time required to restore the data store from a backup is approximately 1 hour. ”
The selected answer (C) says “Transfer the daily backup files to S3 and use appropriate bucket lifecycle policies to send to Glacier”
It is not possible to restore the file from Glacier in 1 hour after it has been moved from S3 to Glacier after 7 days. How is it the correct answer?
Store in S3 for seven days and then archive to Glacier, as it is needed within the past 7 days.
you said you cannot transition from GLACIER-> X -> STANDARD or REDUCED_REDUNDANCY or STANDARD_IA
so when you RESTORE and Object from Glacier, which Class of S3 Storage does it go to?
you can’t change the class. When you restore the object in glacier does not change. A temporary copy is created with RRS class.
On Q4, your comment for option ‘C’: The minimum time that an object needs to stay in one class is 30 days I believe. I think the answer still stays the same but I do not believe you can set a lifecycle policy for less than 30 days from Standard to Glacier and/or IA to Glacier.
You can have Standard or RRS to Glacier within a Day. But IA needed 30 days.
Hi Jay,
How does it fulfill the requirement for:
“The time required to restore the data store from a backup is approximately 1 hour”
you can’t restore the data from Glacier in an hour. it takes hours to do so. (expedited one needs to be less than 250 MB.)
Would you clarify?
Thanks,
Farzin
Data is initially in S3 for immediate access and then moved to Glacier for archival.
Hi jay,
thanks again for your incredible job here.
in Q1. I tried to change the class of an obj directly to glacier and it was ok. is it recently changed?
thanks
lifecycle policies and sS3 storage classes have undergone quite a lot of changes. So it might be possible.
It IS possible now. Not sure what it means for the correct answer in the actual exam.
This questions was in the old exams and were not updated for sure.
However, with the new exam the services and enhancements are taken into account.
Using AWS S3 Object Lifecycle, how can I delete old objects which are created before appliying lifecycle rule ?
S3 Lifecycle policies apply to both existing and new S3 objects.
Bit confused on Standard -> Glacier.
One comment above says we can do it in 1 day while in Q1, its mentioned that this can be done after min of 30 days.
Glacier can be immediate.
In S3, Can you move data from the deep archive to Glacier?
Your firm has uploaded a large amount of aerial image data to S3. In the past, in your on-premises environment, you used a dedicated group of servers to oaten process this data and used Rabbit MQ, an open source messaging system, to get job information to the servers. Once processed the data would go to tape and be shipped offsite. Your manager told you to stay with the current design, and leverage AWS archival storage and messaging services to minimize cost. Which is correct?
Use SQS for passing job messages, use Cloud Watch alarms to terminate EC2 worker instances when they become idle. Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage (Need to replace On-Premises Tape functionality)
Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS. Once data is processed, change the storage class of the S3 objects to Reduced Redundancy Storage (Need to replace On-Premises Tape functionality)
Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS. Once data is processed, change the storage class of the S3 objects to Glacier (Glacier suitable for Tape backup)
Use SNS to pass job messages use Cloud Watch alarms to terminate spot worker instances when they become idle. Once data is processed, change the storage class of the S3 object to Glacier.
Please explain why last option is not suitable.
Key point is to stay with the current design, so using SQS for Rabbit MQ makes sense. Also the last option has missing pieces, it wouldn’t work as mentioned.
Question: 2 Says “The time required to restore the data store from a backup is approximately 1 hour. ”
The selected answer (C) says “Transfer the daily backup files to S3 and use appropriate bucket lifecycle policies to send to Glacier”
It is not possible to restore the file from Glacier in 1 hour after it has been moved from S3 to Glacier after 7 days. How is it the correct answer?
Store in S3 for seven days and then archive to Glacier, as it is needed within the past 7 days.
you said you cannot transition from GLACIER-> X -> STANDARD or REDUCED_REDUNDANCY or STANDARD_IA
so when you RESTORE and Object from Glacier, which Class of S3 Storage does it go to?
you can’t change the class. When you restore the object in glacier does not change. A temporary copy is created with RRS class.
On Q4, your comment for option ‘C’: The minimum time that an object needs to stay in one class is 30 days I believe. I think the answer still stays the same but I do not believe you can set a lifecycle policy for less than 30 days from Standard to Glacier and/or IA to Glacier.
You can have Standard or RRS to Glacier within a Day. But IA needed 30 days.
Hi Jay,
How does it fulfill the requirement for:
“The time required to restore the data store from a backup is approximately 1 hour”
you can’t restore the data from Glacier in an hour. it takes hours to do so. (expedited one needs to be less than 250 MB.)
Would you clarify?
Thanks,
Farzin
Data is initially in S3 for immediate access and then moved to Glacier for archival.
Hi jay,
thanks again for your incredible job here.
in Q1. I tried to change the class of an obj directly to glacier and it was ok. is it recently changed?
thanks
lifecycle policies and sS3 storage classes have undergone quite a lot of changes. So it might be possible.
It IS possible now. Not sure what it means for the correct answer in the actual exam.
This questions was in the old exams and were not updated for sure.
However, with the new exam the services and enhancements are taken into account.
Using AWS S3 Object Lifecycle, how can I delete old objects which are created before appliying lifecycle rule ?
S3 Lifecycle policies apply to both existing and new S3 objects.
Bit confused on Standard -> Glacier.
One comment above says we can do it in 1 day while in Q1, its mentioned that this can be done after min of 30 days.
Glacier can be immediate.
In S3, Can you move data from the deep archive to Glacier?
nope, you cannot change deep archive to any other storage class. refer documentation @ https://docs.aws.amazon.com/AmazonS3/latest/dev/lifecycle-transition-general-considerations.html