Table of Contents
hide
AWS Lambda
- AWS Lambda offers Serverless computing that allows applications and services to be built and run without thinking about servers.
- With serverless computing, the application still runs on servers, but all the server management is done by AWS.
- helps run code without provisioning or managing servers, where you pay only for the compute time when the code is running.
- is priced on a pay-per-use basis and there are no charges when the code is not running.
- allows the running of code for any type of application or backend service with zero administration.
- performs all the operational and administrative activities on your behalf, including capacity provisioning, monitoring fleet health, applying security patches to the underlying compute resources, deploying code, running a web service front end, and monitoring and logging the code.
- does not provide access to the underlying compute infrastructure.
- handles scalability and availability as it
- provides easy scaling and high availability to the code without additional effort on your part.
- is designed to process events within milliseconds.
- is designed to run many instances of the functions in parallel.
- is designed to use replication and redundancy to provide high availability for both the service and the functions it operates.
- has no maintenance windows or scheduled downtimes for either.
- has a default safety throttle for the number of concurrent executions per account per region.
- has a higher latency immediately after a function is created, or updated, or if it has not been used recently.
- for any function updates, there is a brief window of time, less than a minute, when requests would be served by both versions
- Security
- stores code in S3 and encrypts it at rest and performs additional integrity checks while the code is in use.
- each function runs in its own isolated environment, with its own resources and file system view
- supports Code Signing using AWS Signer, which offers trust and integrity controls that enable you to verify that only unaltered code from approved developers is deployed in the functions.
- Functions must complete execution within 900 seconds. The default timeout is 3 seconds. The timeout can be set the timeout to any value between 1 and 900 seconds.
- AWS Step Functions can help coordinate a series of Lambda functions in a specific order. Multiple functions can be invoked sequentially, passing the output of one to the other, and/or in parallel, while the state is being maintained by Step Functions.
- AWS X-Ray helps to trace functions, which provides insights such as service overhead, function init time, and function execution time.
- Lambda Provisioned Concurrency provides greater control over the performance of serverless applications.
- Lambda@Edge allows you to run code across AWS locations globally without provisioning or managing servers, responding to end-users at the lowest network latency.
- Lambda Extensions allow integration of Lambda with other third-party tools for monitoring, observability, security, and governance.
- Compute Savings Plan can help save money for Lambda executions.
- CodePipeline and CodeDeploy can be used to automate the serverless application release process.
- RDS Proxy provides a highly available database proxy that manages thousands of concurrent connections to relational databases.
- Supports Elastic File Store , to provide a shared, external, persistent, scalable volume using a fully managed elastic NFS file system without the need for provisioning or capacity management.
- supports Function URLs, a built-in HTTPS endpoint that can be invoked using the browser, curl, and any HTTP client.
Functions & Event Sources
- Core components of Lambda are functions and event sources.
- Event source – an AWS service or custom application that publishes events.
- Function – a custom code that processes the events.
Lambda Functions
- Each function has associated configuration information, such as its name, description, runtime, entry point, and resource requirements
- Lambda functions should be designed as stateless
- Lambda Execution role can be assigned to the function to grant permission to access other resources.
- Functions have the following restrictions
- Inbound network connections are blocked
- Outbound connections only TCP/IP sockets are supported
ptrace(debugging) system calls are blocked- TCP port 25 traffic is also blocked as an anti-spam measure.
- Lambda may choose to retain an instance of the function and reuse it to serve a subsequent request, rather than creating a new copy.
- Lambda Layers provide a convenient way to package libraries and other dependencies that you can use with your Lambda functions.
- Function versions can be used to manage the deployment of the functions.
- Function Alias supports creating aliases, which are mutable, for each function version.
- Functions are automatically monitored, and real-time metrics are reported through CloudWatch, including total requests, latency, error rates, etc.
- Lambda automatically integrates with CloudWatch logs, creating a log group for each function and providing basic application lifecycle event log entries, including logging the resources consumed for each use of that function.
- Functions support code written in
- Node.js (JavaScript)
- Python
- Ruby
- Java (Java 8 compatible)
- C# (.NET Core)
- Go
- Custom runtime
- Container images are also supported.
- Failure Handling
- For S3 bucket notifications and custom events, Lambda will attempt execution of the function three times in the event of an error condition in the code or if a service or resource limit is exceeded.
- For ordered event sources that Lambda polls, e.g. DynamoDB Streams and Kinesis streams, it will continue attempting execution in the event of a developer code error until the data expires.
- Kinesis and DynamoDB Streams retain data for a minimum of 24 hours
- Dead Letter Queues (SNS or SQS) can be configured for events to be placed, once the retry policy for asynchronous invocations is exceeded
Read in-depth @ Lambda Functions
Lambda Event Sources
- Event Source is an AWS service or developer-created application that produces events that trigger an AWS Lambda function to run
- Event source mapping refers to the configuration which maps an event source to a Lambda function.
- Event sources can be both push and pull sources
- Services like S3, and SNS publish events to Lambda by invoking the cloud function directly.
- Lambda can also poll resources in services like Kafka, and Kinesis streams that do not publish events to Lambda.
Read in-depth @ Event Sources
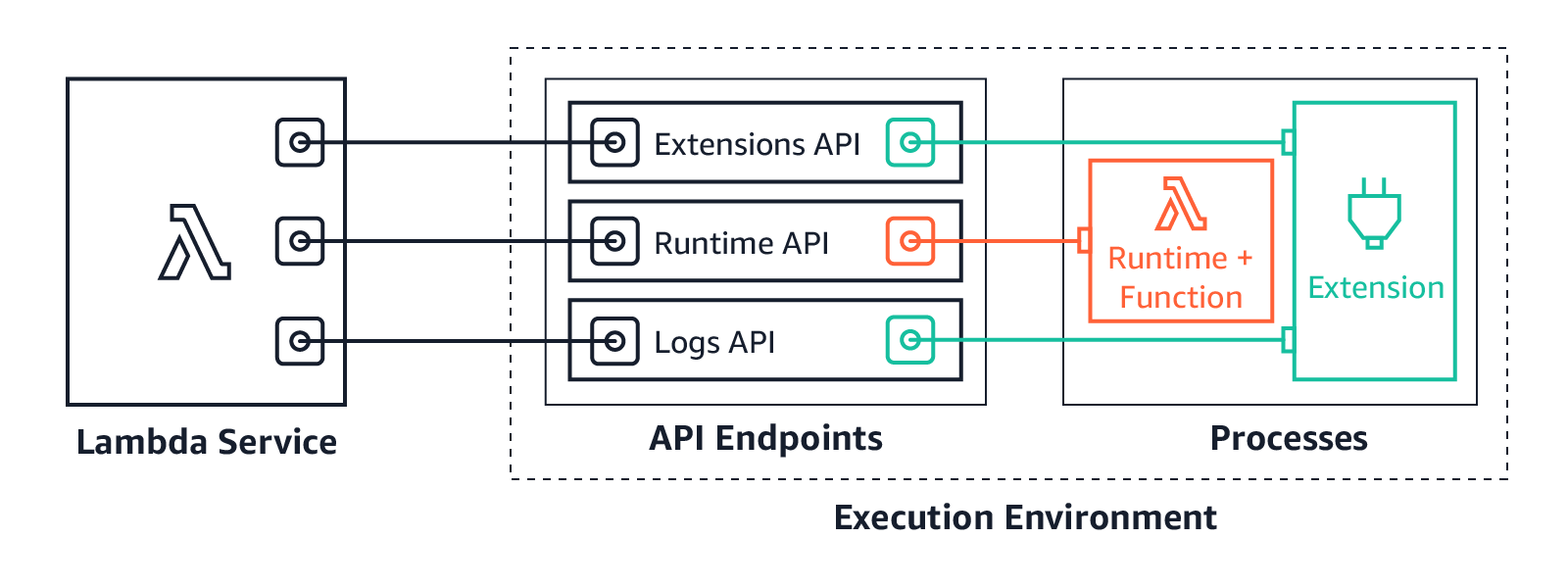
Lambda Execution Environment
- Lambda invokes the function in an execution environment, which provides a secure and isolated runtime environment.
- Execution Context is a temporary runtime environment that initializes any external dependencies of the Lambda function code, e.g. database connections or HTTP endpoints.
- When a function is invoked, the Execution environment is launched based on the provided configuration settings i.e. memory and execution time.
- After a Lambda function is executed, Lambda maintains the execution environment for some time in anticipation of another function invocation which allows it to reuse the
/tmpdirectory and objects declared outside of the function’s handler method e.g. database connection. - When a Lambda function is invoked for the first time or after it has been updated there is latency for bootstrapping as Lambda tries to reuse the Execution Context for subsequent invocations of the Lambda function
- Subsequent invocations perform better performance as there is no need to “cold-start” or initialize those external dependencies
- Execution environment
- takes care of provisioning and managing the resources needed to run the function.
- provides lifecycle support for the function’s runtime and any external extensions associated with the function.
- Function’s runtime communicates with Lambda using the Runtime API.
- Extensions communicate with Lambda using the Extensions API.
- Extensions can also receive log messages from the function by subscribing to logs using the Logs API.
- Lambda manages Execution Environment creations and deletion, there is no AWS Lambda API to manage Execution Environment.
Lambda in VPC
- Lambda function always runs inside a VPC owned by the Lambda service which isn’t connected to your account’s default VPC
- Lambda applies network access and security rules to this VPC and maintains and monitors the VPC automatically.
- A function can be configured to be launched in private subnets in a VPC in your AWS account.
- Function connected to VPC can access private resources databases, cache instances, or internal services during the execution.
- To enable the function to access resources inside the private VPC, additional VPC-specific configuration information that includes private subnet IDs and security group IDs must be provided.
- Lambda uses this information to set up ENIs that enables the function to connect securely to other resources within your private VPC.
- Functions connected to VPC can’t access the Internet and need a NAT Gateway to access any external resources outside of AWS.
- Functions cannot connect directly to a VPC with dedicated instance tenancy, instead, peer it to a second VPC with default tenancy.
Lambda Security
- All data stored in ephemeral storage is encrypted at rest with a key managed by AWS.
- Lambda functions provide access only to a single VPC. If multiple subnets are specified, they must all be in the same VPC. Other VPCs can be connected using VPC Peering.
- Supports Code Signing using AWS Signer, which offers trust and integrity controls that enable you to verify that only unaltered code from approved developers is deployed in the functions.
-
AWS Lambda can perform the following signature checks at deployment:
-
Corrupt signature – This occurs if the code artifact has been altered since signing.
-
Mismatched signature – This occurs if the code artifact is signed by a signing profile that is not approved.
-
Expired signature – This occurs if the signature is past the configured expiry date.
-
Revoked signature – This occurs if the signing profile owner revokes the signing jobs.
-
- For sensitive information, for e.g. passwords, AWS recommends using client-side encryption using AWS Key Management Service – KMS and store the resulting values as ciphertext in your environment variable.
- Function code should include the logic to decrypt these values.
Lambda Permissions
- IAM – Use IAM to manage access to the Lambda API and resources like functions and layers.
- Execution Role – A Lambda function can be provided with an Execution Role, that grants it permission to access AWS services and resources e.g. send logs to CloudWatch and upload trace data to AWS X-Ray.
- Function Policy – Resource-based Policies
- Use resource-based policies to give other accounts and AWS services permission to use the Lambda resources.
- Resource-based permissions policies are supported for functions and layers.
Invoking Lambda Functions
- Lambda functions can be invoked
- directly using the Lambda console or API, a function URL HTTP(S) endpoint, an AWS SDK, the AWS CLI, and AWS toolkits.
- other AWS services like S3 and SNS invoke the function.
- to read from a stream or queue and invoke the function.
- Functions can be invoked
- Synchronously
- You wait for the function to process the event and return a response.
- Error handling and retries need to be handled by the Client.
- Invocation includes API, and SDK for calls from API Gateway.
- Asynchronously
- queues the event for processing and returns a response immediately.
- handles retries and can send invocation records to a destination for successful and failed events.
- Invocation includes S3, SNS, and CloudWatch Events
- can define DLQ for handling failed events. AWS recommends using destination instead of DLQ.
- Synchronously
Lambda Provisioned Concurrency
- Lambda Provisioned Concurrency provides greater control over the performance of serverless applications.
- When enabled, Provisioned Concurrency keeps functions initialized and hyper-ready to respond in double-digit milliseconds.
- Provisioned Concurrency is ideal for building latency-sensitive applications, such as web or mobile backends, synchronously invoked APIs, and interactive microservices.
- The amount of concurrency can be increased during times of high demand and lowered or turn it off completely when demand decreases.
- If the concurrency of a function reaches the configured level, subsequent invocations of the function have the latency and scale characteristics of regular functions.
Lambda@Edge
Read in-depth @ Lambda@Edge
Lambda Extensions
- Lambda Extensions allow integration of Lambda with other third-party tools for monitoring, observability, security, and governance.
Lambda Best Practices
- Lambda function code should be stateless and ensure there is no affinity between the code and the underlying compute infrastructure.
- Instantiate AWS clients outside the scope of the handler to take advantage of connection re-use.
- Make sure you have set +rx permissions on your files in the uploaded ZIP to ensure Lambda can execute code on your behalf.
- Lower costs and improve performance by minimizing the use of startup code not directly related to processing the current event.
- Use the built-in CloudWatch monitoring of the Lambda functions to view and optimize request latencies.
- Delete old Lambda functions that you are no longer using.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- Your serverless architecture using AWS API Gateway, AWS Lambda, and AWS DynamoDB experienced a large increase in traffic to a sustained 400 requests per second, and dramatically increased in failure rates. Your requests, during normal operation, last 500 milliseconds on average. Your DynamoDB table did not exceed 50% of provisioned throughput, and Table primary keys are designed correctly. What is the most likely issue?
- Your API Gateway deployment is throttling your requests.
- Your AWS API Gateway Deployment is bottlenecking on request (de)serialization.
- You did not request a limit increase on concurrent Lambda function executions. (Refer link – AWS API Gateway by default throttles at 500 requests per second steady-state, and 1000 requests per second at spike. Lambda, by default, throttles at 100 concurrent requests for safety. At 500 milliseconds (half of a second) per request, you can expect to support 200 requests per second at 100 concurrency. This is less than the 400 requests per second your system now requires. Make a limit increase request via the AWS Support Console.)
- You used Consistent Read requests on DynamoDB and are experiencing semaphore lock.
Hello Jayendra,
‘There is no versioning’ in the below statement seems incorrect.
‘Each AWS Lambda function has a single, current version of the code and there is no versioning’
http://docs.aws.amazon.com/lambda/latest/dg/versioning-aliases.html
–Manisha
Thanks Manisha, the statement is ambiguous as the functions once defined are immutable and do not have versions. But you can have versioning using Alias. Update the same.
Yes, that is a little conflicting. Thanks for adding more information regarding that.
Thanks Jayendra, your blogs area really nice and helping me to prepare for exam. I scheduled my exam on 7th sept and was going thr’ above question.
As per the refer link the all numbers are in within limit. so none of the option can be selected as answer. pl correct me if I am wrong.
AWS Lambda Limits for Concurrent executions is 1000 . So
AWS API gateway throttle rate per account per sec is 10000 .
Thanks Nandkishor, the limits has been enhanced. Will update the same.
Hi, for async events, Lambda will retry 2 times, not 3.
Correct me if I am wrong.
“Asynchronous events are queued before being used to invoke the Lambda function. If AWS Lambda is unable to fully process the event, it will automatically retry the invocation twice, with delays between retries”
http://docs.aws.amazon.com/lambda/latest/dg/retries-on-errors.html
Thanks Nick, will correct the same.
Please correct it as soon as possible.
https://aws.amazon.com/lambda/faqs/
On failure, Lambda functions being invoked synchronously will respond with an exception. Lambda functions being invoked asynchronously are retried at least 3 times.
Thanks Kumar and Nick, there seems to be some discrepancy in the FAQs and the actual documentation. Need to verify the same.
https://aws.amazon.com/lambda/faqs/
From Point : “Lambda allows you to run code for any time of application or backend service with zero administration”
From AWS: With Lambda, you can run code for virtually any type of application or backend service – all with zero administration.
Is this is should be “any type or any time is correct ”
Thanks,
Thanks Uday, corrected the same.
Guess it’s not yet updated. Please check.
The post has not been updated yet.
Guess this is yet to be updated in the above post.
unfortunately not 🙂 Quite some changes in lambda, need to revisit the post …
post has been updated and corrected.
Hi Jai,
Thanks for the blog with huge info on one location.
Hope the timeout limit of lambda has been increased from 300 to 900 sec.
Please cross check with AWS Documentation and help us with updated info.
Thanks.
thanks Vamsi, AWS upgrades its services much faster. I have updated the same.