AWS ElastiCache
- AWS ElastiCache is a managed web service that helps deploy and run Memcached or Redis protocol-compliant cache clusters in the cloud easily.
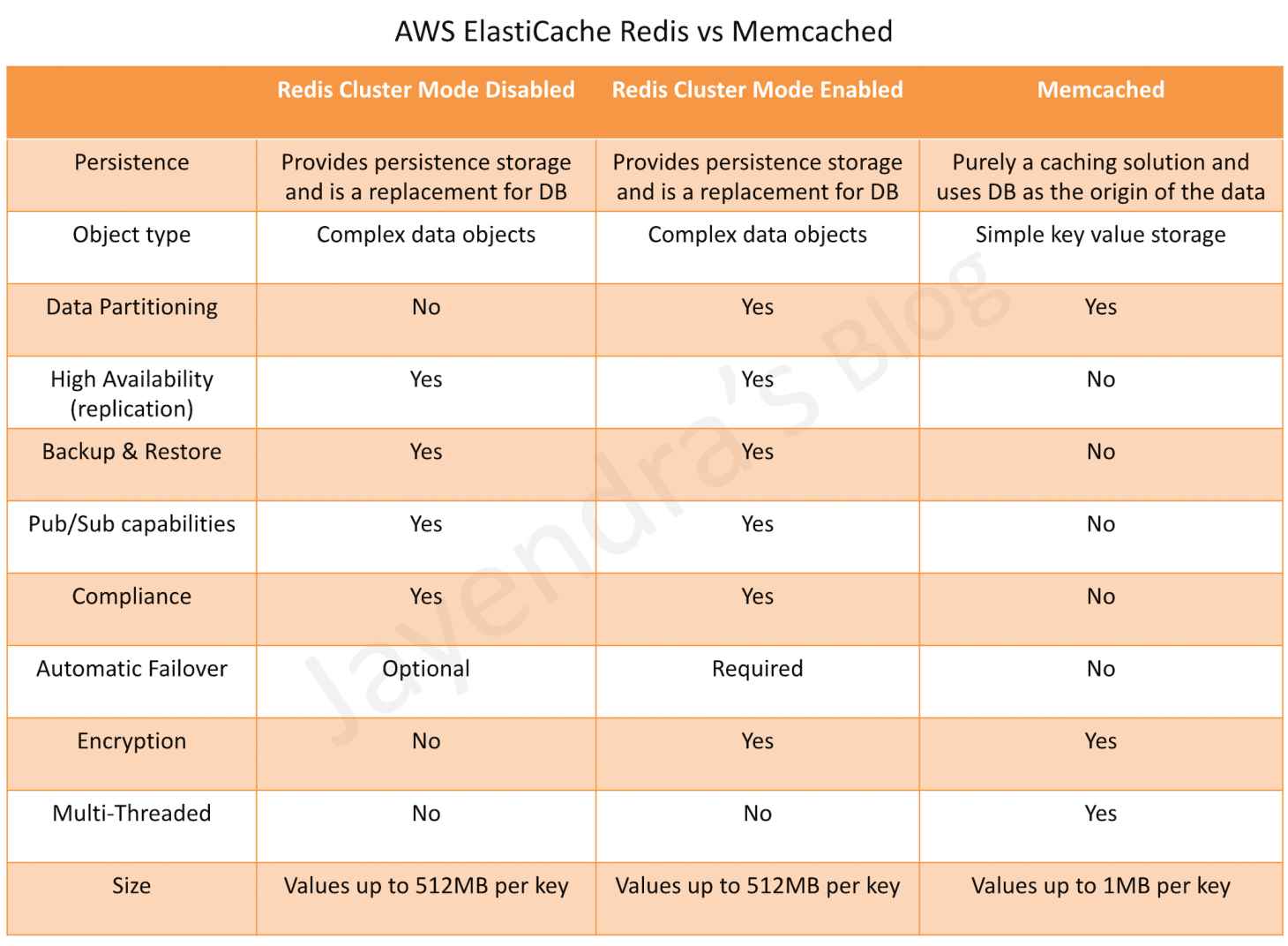
- ElastiCache is available in two flavours: Memcached and Redis
- ElastiCache helps
- simplify and offload the management, monitoring, and operation of in-memory cache environments, enabling the engineering resources to focus on developing applications.
- automate common administrative tasks required to operate a distributed cache environment.
- improves the performance of web applications by allowing retrieval of information from a fast, managed, in-memory caching system, instead of relying entirely on slower disk-based databases.
- helps improve load & response times to user actions and queries, but also reduces the cost associated with scaling web applications.
- helps automatically detect and replace failed cache nodes, providing a resilient system that mitigates the risk of overloaded databases, which can slow website and application load times.
- provides enhanced visibility into key performance metrics associated with the cache nodes through integration with CloudWatch.
- code, applications, and popular tools already using Memcached or Redis environments work seamlessly, with being protocol-compliant with Memcached and Redis environments
- ElastiCache provides in-memory caching which can
- significantly lower latency and improve throughput for many
- read-heavy application workloads e.g. social networking, gaming, media sharing, and Q&A portals.
- compute-intensive workloads such as a recommendation engine.
- improve application performance by storing critical pieces of data in memory for low-latency access.
- be used to cache the results of I/O-intensive database queries or the results of computationally-intensive calculations.
- significantly lower latency and improve throughput for many
- ElastiCache currently allows access only from the EC2 network and cannot be accessed from outside networks like on-premises servers.
ElastiCache Redis vs Memcached
Redis
- Redis is an open source, BSD licensed, advanced key-value cache & store.
- ElastiCache enables the management, monitoring, and operation of a Redis node; creation, deletion, and modification of the node.
- ElastiCache for Redis can be used as a primary in-memory key-value data store, providing fast, sub-millisecond data performance, high availability and scalability up to 16 nodes plus up to 5 read replicas, each of up to 3.55 TiB of in-memory data.
- ElastiCache for Redis supports (similar to RDS features)
- Redis Master/Slave replication.
- Multi-AZ operation by creating read replicas in another AZ
- Backup and Restore feature for persistence using snapshots
- ElastiCache for Redis can be vertically scaled upwards by selecting a larger node type or by adding shards (with cluster mode enabled).
- Parameter group can be specified for Redis during installation, which acts as a “container” for Redis configuration values that can be applied to one or more Redis primary clusters.
- Append Only File – AOF
- provides persistence and can be enabled for recovery scenarios.
- if a node restarts or service crashes, Redis will replay the updates from an AOF file, thereby recovering the data lost due to the restart or crash.
- cannot protect against all failure scenarios, cause if the underlying hardware fails, a new server would be provisioned and the AOF file will no longer be available to recover the data.
- ElastiCache for Redis doesn’t support the AOF feature but you can achieve persistence by snapshotting the Redis data using the Backup and Restore feature.
- Enabling Redis Multi-AZ is a Better Approach to Fault Tolerance, as failing over to a read replica is much faster than rebuilding the primary from an AOF file.
Redis Features
- High Availability, Fault Tolerance & Auto Recovery
- Multi-AZ for a failed primary cluster to a read replica, in Redis clusters that support replication.
- Fault Tolerance – Flexible AZ placement of nodes and clusters
- High Availability – Primary instance and a synchronous secondary instance to fail over when problems occur. You can also use read replicas to increase read scaling.
- Auto-Recovery – Automatic detection of and recovery from cache node failures.
- Backup & Restore – Automated backups or manual snapshots can be performed. Redis restore process works reliably and efficiently.
- Performance
- Data Partitioning – Redis (cluster mode enabled) supports partitioning the data across up to 500 shards.
- Data Tiering – Provides a price-performance option for Redis workloads by utilizing lower-cost solid state drives (SSDs) in each cluster node in addition to storing data in memory. It is ideal for workloads that access up to 20% of their overall dataset regularly, and for applications that can tolerate additional latency when accessing data on SSD.
- Security
- Encryption – Supports encryption in transit and encryption at rest encryption with authentication. This support helps you build HIPAA-compliant applications.
- Access Control – Control access to the ElastiCache for Redis clusters by using AWS IAM to define users and permissions.
- Supports Redis AUTH or Managed Role-Based Access Control (RBAC).
- Administration
- Low Administration – ElastiCache for Redis manages backups, software patching, automatic failure detection, and recovery.
- Integration with other AWS services such as EC2, CloudWatch, CloudTrail, and SNS.
- Global Datastore for Redis feature provides a fully managed, fast, reliable, and secure replication across AWS Regions. Cross-Region read replica clusters for ElastiCache for Redis can be created to enable low-latency reads and disaster recovery across AWS Regions.
Redis Read Replica
- Read Replicas help provide Read scaling and handling failures
- Read Replicas are kept in sync with the Primary node using Redis’s asynchronous replication technology
- Redis Read Replicas provides
- Horizontal scaling beyond the compute or I/O capacity of a single primary node for read-heavy workloads.
- Serving read traffic while the primary is unavailable either being down due to failure or maintenance
- Data protection scenarios to promote a Read Replica as the primary node, in case the primary node or the AZ of the primary node fails.
- ElastiCache supports initiated or forced failover where it flips the DNS record for the primary node to point at the read replica, which is in turn promoted to become the new primary.
- Read replica cannot span across regions and may only be provisioned in the same or different AZ of the same Region as the cache node primary.
Redis Multi-AZ
- ElastiCache for Redis shard consists of a primary and up to 5 read replicas
- Redis asynchronously replicates the data from the primary node to the read replicas
- ElastiCache for Redis Multi-AZ mode
- provides enhanced availability and a smaller need for administration as the node failover is automatic.
- impact on the ability to read/write to the primary is limited to the time it takes for automatic failover to complete.
- no longer needs monitoring of Redis nodes and manually initiating a recovery in the event of a primary node disruption.
- During certain types of planned maintenance, or in the unlikely event of ElastiCache node failure or AZ failure,
- it automatically detects the failure,
- selects a replica, depending upon the read replica with the smallest asynchronous replication lag to the primary, and promotes it to become the new primary node
- it will also propagate the DNS changes so that the primary endpoint remains the same
- If Multi-AZ is not enabled,
- ElastiCache monitors the primary node.
- in case the node becomes unavailable or unresponsive, it will repair the node by acquiring new service resources.
- it propagates the DNS endpoint changes to redirect the node’s existing DNS name to point to the new service resources.
- If the primary node cannot be healed and you will have the choice to promote one of the read replicas to be the new primary.
Redis Backup & Restore
- Backup and Restore allow users to create snapshots of the Redis clusters.
- Snapshots can be used for recovery, restoration, archiving purposes, or warm start an ElastiCache for Redis cluster with preloaded data
- Snapshots can be created on a cluster basis and use Redis’ native mechanism to create and store an RDB file as the snapshot.
- Increased latencies for a brief period at the node might be encountered while taking a snapshot and is recommended to be taken from a Read Replica minimizing performance impact
- Snapshots can be created either automatically (if configured) or manually
- ElastiCache for Redis cluster when deleted removes the automatic snapshots. However, manual snapshots are retained.
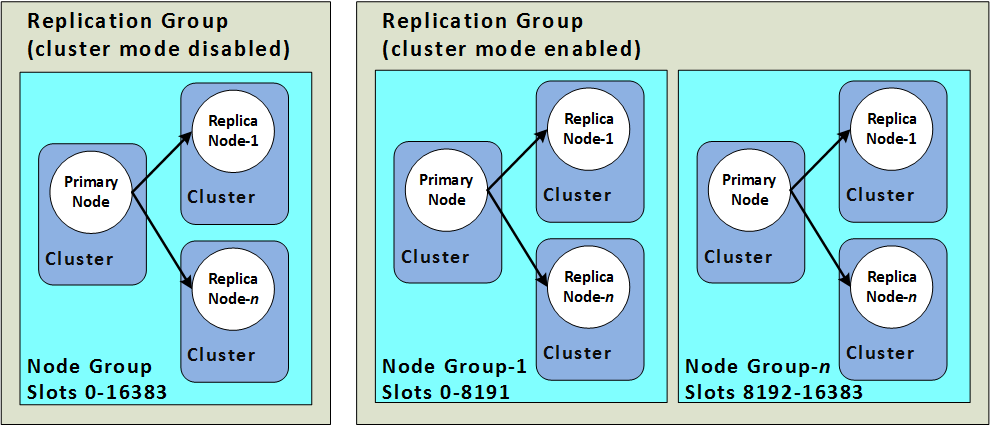
Redis Cluster Mode
ElastiCache Redis provides the ability to create distinct types of Redis clusters
- A Redis (cluster mode disabled) cluster
- always has a single shard with up to 5 read replica nodes.
- A Redis (cluster mode enabled) cluster
- has up to 500 shards with 1 to 5 read replica nodes in each.
- Scaling vs Partitioning
- Redis (cluster mode disabled) supports Horizontal scaling for read capacity by adding or deleting replica nodes, or vertical scaling by scaling up to a larger node type.
- Redis (cluster mode enabled) supports partitioning the data across up to 500 node groups. The number of shards can be changed dynamically as the demand changes. It also helps spread the load over a greater number of endpoints, which reduces access bottlenecks during peak demand.
- Node Size vs Number of Nodes
- Redis (cluster mode disabled) cluster has only one shard and the node type must be large enough to accommodate all the cluster’s data plus necessary overhead.
- Redis (cluster mode enabled) cluster can have smaller node types as the data can be spread across partitions.
- Reads vs Writes
- Redis (cluster mode disabled) cluster can be scaled for reads by adding more read replicas (5 max)
- Redis (cluster mode disabled) cluster can be scaled for both reads and writes by adding read replicas and multiple shards.
Memcached
- Memcached is an in-memory key-value store for small chunks of arbitrary data.
- ElastiCache for Memcached can be used to cache a variety of objects
- ElastiCache for Memcached
- can be scaled Vertically by increasing the node type size
- can be scaled Horizontally by adding and removing nodes
- does not support the persistence of data
- ElastiCache for Memcached cluster can have
- nodes that can span across multiple AZs within the same region
- maximum of 20 nodes per cluster with a maximum of 100 nodes per region (soft limit and can be extended).
- ElastiCache for Memcached supports auto-discovery, which enables the automatic discovery of cache nodes by clients when they are added to or removed from an ElastiCache cluster.
ElastiCache Mitigating Failures
- ElastiCache should be designed to plan so that failures have a minimal impact on the application and data.
- Mitigating Failures when Running Memcached
- Mitigating Node Failures
- spread the cached data over more nodes
- as Memcached does not support replication, a node failure will always result in some data loss from the cluster
- having more nodes will reduce the proportion of cache data lost
- Mitigating Availability Zone Failures
- locate the nodes in as many availability zones as possible, only the data cached in that AZ is lost, not the data cached in the other AZs
- Mitigating Node Failures
- Mitigating Failures when Running Redis
- Mitigating Cluster Failures
- Redis Append Only Files (AOF)
- enable AOF so whenever data is written to the Redis cluster, a corresponding transaction record is written to a Redis AOF.
- when Redis process restarts, ElastiCache creates a replacement cluster and provisions it and repopulates it with data from AOF.
- It is time-consuming
- AOF can get big.
- Using AOF cannot protect you from all failure scenarios.
- Redis Replication Groups
- A Redis replication group is comprised of a single primary cluster which the application can both read from and write to, and from 1 to 5 read-only replica clusters.
- Data written to the primary cluster is also asynchronously updated on the read replica clusters.
- When a Read Replica fails, ElastiCache detects the failure, replaces the instance in the same AZ, and synchronizes with the Primary Cluster.
- Redis Multi-AZ with Automatic Failover, ElastiCache detects Primary cluster failure and promotes a read replica with the least replication lag to primary.
- Multi-AZ with Auto Failover is disabled, ElastiCache detects Primary cluster failure, creates a new one and syncs the new Primary with one of the existing replicas.
- Redis Append Only Files (AOF)
- Mitigating Availability Zone Failures
- locate the clusters in as many availability zones as possible
- Mitigating Cluster Failures
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- What does Amazon ElastiCache provide?
- A service by this name doesn’t exist. Perhaps you mean Amazon CloudCache.
- A virtual server with a huge amount of memory.
- A managed In-memory cache service
- An Amazon EC2 instance with the Memcached software already pre-installed.
- You are developing a highly available web application using stateless web servers. Which services are suitable for storing session state data? Choose 3 answers.
- Elastic Load Balancing
- Amazon Relational Database Service (RDS)
- Amazon CloudWatch
- Amazon ElastiCache
- Amazon DynamoDB
- AWS Storage Gateway
- Which statement best describes ElastiCache?
- Reduces the latency by splitting the workload across multiple AZs
- A simple web services interface to create and store multiple data sets, query your data easily, and return the results
- Offload the read traffic from your database in order to reduce latency caused by read-heavy workload
- Managed service that makes it easy to set up, operate and scale a relational database in the cloud
- Our company is getting ready to do a major public announcement of a social media site on AWS. The website is running on EC2 instances deployed across multiple Availability Zones with a Multi-AZ RDS MySQL Extra Large DB Instance. The site performs a high number of small reads and writes per second and relies on an eventual consistency model. After comprehensive tests you discover that there is read contention on RDS MySQL. Which are the best approaches to meet these requirements? (Choose 2 answers)
- Deploy ElastiCache in-memory cache running in each availability zone
- Implement sharding to distribute load to multiple RDS MySQL instances
- Increase the RDS MySQL Instance size and Implement provisioned IOPS
- Add an RDS MySQL read replica in each availability zone
- You are using ElastiCache Memcached to store session state and cache database queries in your infrastructure. You notice in CloudWatch that Evictions and Get Misses are both very high. What two actions could you take to rectify this? Choose 2 answers
- Increase the number of nodes in your cluster
- Tweak the max_item_size parameter
- Shrink the number of nodes in your cluster
- Increase the size of the nodes in the cluster
- You have been tasked with moving an ecommerce web application from a customer’s datacenter into a VPC. The application must be fault tolerant and well as highly scalable. Moreover, the customer is adamant that service interruptions not affect the user experience. As you near launch, you discover that the application currently uses multicast to share session state between web servers, In order to handle session state within the VPC, you choose to:
- Store session state in Amazon ElastiCache for Redis (scalable and makes the web applications stateless)
- Create a mesh VPN between instances and allow multicast on it
- Store session state in Amazon Relational Database Service (RDS solution not highly scalable)
- Enable session stickiness via Elastic Load Balancing (affects user experience if the instance goes down)
- When you are designing to support a 24-hour flash sale, which one of the following methods best describes a strategy to lower the latency while keeping up with unusually heavy traffic?
- Launch enhanced networking instances in a placement group to support the heavy traffic (only improves internal communication)
- Apply Service Oriented Architecture (SOA) principles instead of a 3-tier architecture (just simplifies architecture)
- Use Elastic Beanstalk to enable blue-green deployment (only minimizes download for applications and ease of rollback)
- Use ElastiCache as in-memory storage on top of DynamoDB to store user sessions (scalable, faster read/writes and in memory storage)
- You are configuring your company’s application to use Auto Scaling and need to move user state information. Which of the following AWS services provides a shared data store with durability and low latency?
- AWS ElastiCache Memcached (does not provide durability as if the node is gone the data is gone)
- Amazon Simple Storage Service
- Amazon EC2 instance storage
- Amazon DynamoDB
- Your application is using an ELB in front of an Auto Scaling group of web/application servers deployed across two AZs and a Multi-AZ RDS Instance for data persistence. The database CPU is often above 80% usage and 90% of I/O operations on the database are reads. To improve performance you recently added a single-node Memcached ElastiCache Cluster to cache frequent DB query results. In the next weeks the overall workload is expected to grow by 30%. Do you need to change anything in the architecture to maintain the high availability for the application with the anticipated additional load and Why?
- You should deploy two Memcached ElastiCache Clusters in different AZs because the RDS Instance will not be able to handle the load if the cache node fails.
- If the cache node fails the automated ElastiCache node recovery feature will prevent any availability impact. (does not provide high availability, as data is lost if the node is lost)
- Yes you should deploy the Memcached ElastiCache Cluster with two nodes in the same AZ as the RDS DB master instance to handle the load if one cache node fails. (Single AZ affects availability as DB is Multi AZ and would be overloaded is the AZ goes down)
- No if the cache node fails you can always get the same data from the DB without having any availability impact. (Will overload the database affecting availability)
- A read only news reporting site with a combined web and application tier and a database tier that receives large and unpredictable traffic demands must be able to respond to these traffic fluctuations automatically. What AWS services should be used meet these requirements?
- Stateless instances for the web and application tier synchronized using ElastiCache Memcached in an autoscaling group monitored with CloudWatch and RDS with read replicas.
- Stateful instances for the web and application tier in an autoscaling group monitored with CloudWatch and RDS with read replicas (Stateful instances will not allow for scaling)
- Stateful instances for the web and application tier in an autoscaling group monitored with CloudWatch and multi-AZ RDS (Stateful instances will allow not for scaling & multi-AZ is for high availability and not scaling)
- Stateless instances for the web and application tier synchronized using ElastiCache Memcached in an autoscaling group monitored with CloudWatch and multi-AZ RDS (multi-AZ is for high availability and not scaling)
- You have written an application that uses the Elastic Load Balancing service to spread traffic to several web servers. Your users complain that they are sometimes forced to login again in the middle of using your application, after they have already logged in. This is not behavior you have designed. What is a possible solution to prevent this happening?
- Use instance memory to save session state.
- Use instance storage to save session state.
- Use EBS to save session state.
- Use ElastiCache to save session state.
- Use Glacier to save session slate.
Hi Jay
You are using ElastiCache Memcached to store session state and cache database queries in your infrastructure. You notice in CloudWatch that Evictions and Get Misses are both very high. What two actions could you take to rectify this? Choose 2 answers
Increase the number of nodes in your cluster
Tweak the max_item_size parameter
Shrink the number of nodes in your cluster
Increase the size of the nodes in the cluster
Answer should be A and D.
Explanation
=========
Evictions
This is a cache engine metric, published for both Memcached and Redis cache clusters. We recommend that you determine your own alarm threshold for this metric based on your application needs.
Memcached: If you exceed your chosen threshold, scale you cache cluster up by using a larger node type, or scale out by adding more nodes.
Redis: If you exceed your chosen threshold, scale your cluster up by using a larger node type.
Thanks
K.Senthilkumar
Thanks Senthil, my bad marked that incorrectly. Corrected the answer now.
Thank you very much for this blog, passed my AWS Certified SA Associate with flying colors after going through everything on your blog for the last 3 days (took a cloud guru course before, while nice it is not sufficient to clear the test).
This is the best resources on the Internet for AWS test preparation – keep up the great work !
Thanks a lot, Mike 🙂
Let me know if any suggestions to improve it further.
Hi Jayan
I have completed another certification AWS Sys-Ops with 89% after gone through your blog. Earlier I completed AWS SA with 89%.
Thanks a lot for keeping up the site for us !!!
Now I am targeting AWS SA Professional. Could you please share your suggestions/guidance for AWS SA certification ?
Cloudguru course costs $89 for AWS SA professional? is it worth to buy?
Thanks
K.Senthilkumar
Congrats Senthil,
I had got Cloud Guru course on sale for $49 some time back. But Personally I liked Linux Academy course as it covers a lot. You can try a free trial for 7 days and check as well.
please explain for q#6 why answer is not b. a lot of people are saying b.
https://acloud.guru/forums/aws-certified-solutions-architect-professional/discussion/-KWjrMz_FMZryQuUrY9o/aws-prof-practice-exam-q-youve-been-tasked-with-moving-an-ecommerce
Its debatable as am not sure if the VPN mesh between instances is really scalable even though time is a constraint. Just my gut.
Hello Jayendra
Please can you explain why for Q 10 answer (a) is correct.
Please can you explain what is Stateless instances and Stateful instances.
Hi Hemal,
The basic idea here to not allow the user to be associated with an instance which cause issues with scaling as the user requests are always redirected to the same instance even though the system has scaled. So the recommendation is to go for Stateless architecture and use Redis or other data stores for fast access to user information.
Stateless just means maintaining the state for e.g. using ELB session stickiness.
Hi Jay,
We are planning to opt for AWS ElastiCache service for our websites which are running in AWS ECS but we have few queries related to cache service as below :
1. suitable specs given that we have little load currently i.e. a few users accessing the web apps with limited functionality.
2. Ability to support multiple environments: development, uat, sandbox, staging & production
3.Ability to support multiple web apps; staff ui and merchant ui, maybe others later
Since it is pay as you go, seems like we can create one per Web App per Environment.
Could you please suggest these are possible or not?
Redis supports both horizontal and vertical scaling –
https://aws.amazon.com/about-aws/whats-new/2019/08/amazon-elasticache-announces-online-vertical-scaling-for-redis-cluster-mode/#:~:text=You%20can%20now%20scale%20up,sharded%20Redis%20Cluster%20on%20demand.&text=With%20this%20release%2C%20you%20can,while%20keeping%20the%20cluster%20online.
Please update.
Thanks
Thats right Parool, with Cluster Mode Enabled Vertical scaling is possible.