AWS Elastic Beanstalk
- AWS Elastic Beanstalk helps to quickly deploy and manage applications in the AWS Cloud without having to worry about the infrastructure that runs those applications.
- reduces management complexity without restricting choice or control.
- enables automated infrastructure management and code deployment, by simply uploading, for applications and includes
- Application platform management
- Capacity provisioning
- Load Balancing
- Auto Scaling
- Code deployment
- Health Monitoring
- Elastic Beanstalk automatically launches an environment once an application is uploaded, and creates and configures the AWS resources needed to run the code. After the environment is launched, it can be managed and used to deploy new application versions.
- AWS resources launched by Elastic Beanstalk are fully accessible i.e. EC2 instances can be SSHed into.
- provides developers and systems administrators with an easy, fast way to deploy and manage the applications without having to worry about AWS infrastructure.
- CloudFormation, using templates, is a better option than Elastic Beanstalk if the internal AWS resources to be used are known and fine-grained control is needed.
Elastic Beanstalk Components
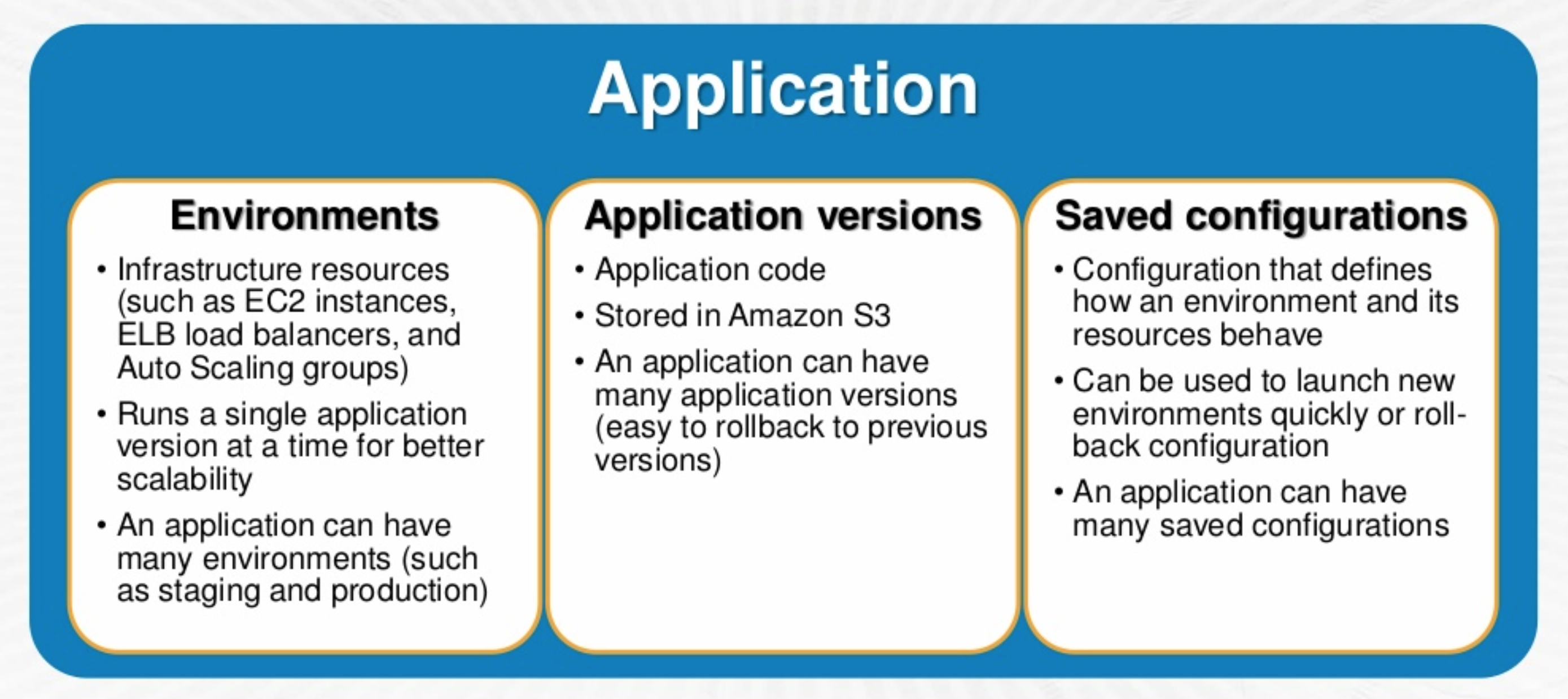
- Application
- An Application is a logical collection of components, including environments, versions, and environment configurations.
- Application Version
- An application version refers to a specific, labeled iteration of deployable code for a web application.
- Applications can have many versions and each application version is unique and points to an S3 object.
- Multiple versions of an Application can be deployed for testing differences and helps to roll back to any version in case of issues.
- Environment
- An environment is a version that is deployed onto AWS resources.
- An environment runs a single application version at a time, but same application version can be deployed across multiple environments.
- When an environment is created, EB provisions the resources needed to run the specified application version.
- Environment Configuration
- An environment configuration identifies a collection of parameters and settings that define how an environment and its associated resources behave
- When an environment’s configuration settings are updated, EB automatically applies the changes to existing resources or deletes and deploys new resources, depending upon the change
- Configuration Template
- A configuration template is a starting point for creating unique environment configurations
Elastic Beanstalk Architecture
- Elastic Beanstalk environment requires an environment tier, platform, and
environment type.
- Environment tier determines whether EB provisions resources to support
- Web tier – a web application that handles HTTP(S) requests
- Worker tier – an application that handles background-processing tasks.
- One environment cannot support two different environment tiers because each requires its own set of resources; a worker environment tier and a web server environment tier each require an Auto Scaling group, but Elastic Beanstalk supports only one Auto Scaling group per environment.
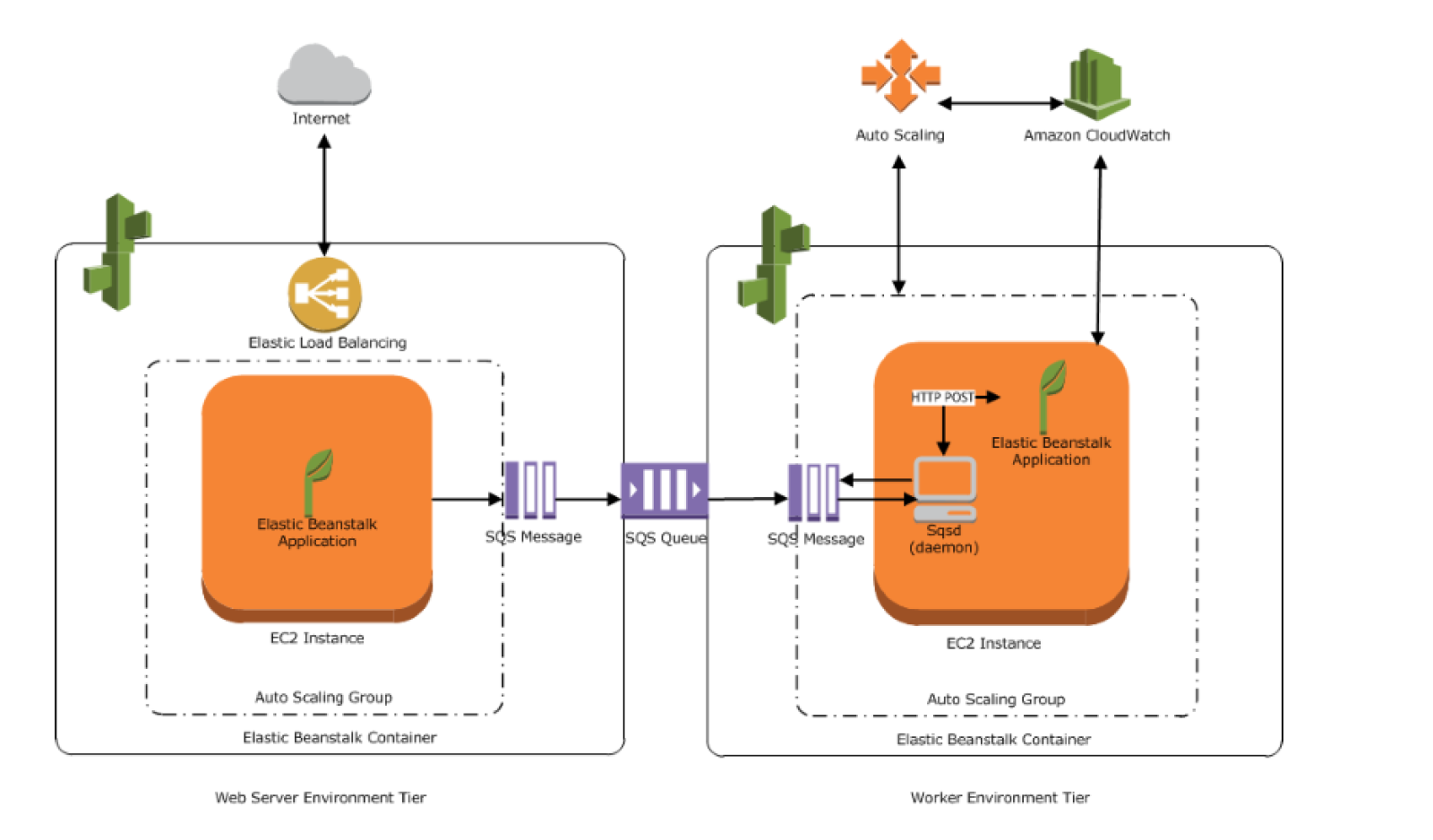
Web Environment Tier
- An environment tier whose web application processes web requests is known as a web server tier.
- AWS resources created for a web environment tier include an Elastic Load Balancer, an Auto Scaling group, one or more EC2 instances
- Every Environment has a CNAME URL pointing to the ELB, aliased in Route 53 to ELB URL.
- Each EC2 server instance that runs the application uses a container type, which defines the infrastructure topology and software stack.
- A software component called the host manager (HM) runs on each EC2 server instance and is responsible for
- Deploying the application
- Aggregating events and metrics for retrieval via the console, the API, or the command line
- Generating instance-level events
- Monitoring the application log files for critical errors
- Monitoring the application server
- Patching instance components
- Rotating your application’s log files and publishing them to S3
Worker Environment Tier
- An environment tier whose web application runs background jobs is known as a worker tier.
- AWS resources created for a worker environment tier include an Auto Scaling group, one or more EC2 instances, and an IAM role.
- For the worker environment tier, Elastic Beanstalk also creates and provisions an SQS queue, if one doesn’t exist.
- When a worker environment tier is launched, EB installs the necessary support files for the programming language of choice and a daemon on each EC2 instance in the Auto Scaling group reading from the same SQS queue.
- Daemon is responsible for pulling requests from an SQS queue and then sending the data to the web application running in the worker environment tier that will process those messages.
- Worker environments support SQS dead letter queues which can be used to store messages that could not be successfully processed. Dead letter queue provides the ability to sideline, isolate and analyze the unsuccessfully processed messages
Elastic Beanstalk with Other AWS Services
- Elastic Beanstalk supports VPC and launches AWS resources, such as instances, into the VPC
- Elastic Beanstalk supports IAM and helps you securely control access to your AWS resources.
- CloudFront can be used to distribute the content in S3 after an Elastic Beanstalk is created and deployed
- CloudTrail
- Elastic Beanstalk is integrated with CloudTrail, a service that captures all of the Elastic BeanstalkAPI calls and delivers the log files to a specified S3 bucket.
- CloudTrail captures API calls from the Elastic Beanstalk console or from your code to the Elastic Beanstalk APIs and helps to determine the request made to Elastic Beanstalk, the source IP address from which the request was made, who made the request, when it was made, etc.
- RDS
- EB provides support for running RDS instances in the environment which is ideal for development and testing but not for production.
- For a production environment, it is not recommended because it ties the lifecycle of the database instance to the lifecycle of the application’s environment. So if the environment is deleted, the RDS instance is deleted as well
- It is recommended to launch a database instance outside of the environment and configure the application to connect to it outside of the functionality provided by Elastic Beanstalk.
- Using a database instance external to the environment requires additional security group and connection string configuration, but it also lets the application connect to the database from multiple environments, use database types not supported with integrated databases, perform blue/green deployments, and tear down the environment without affecting the database instance.
- S3
- EB creates an S3 bucket named elasticbeanstalk-region-account-id for each region in which environments are created.
- EB uses the bucket to store application versions, logs, and other supporting files.
- It applies a bucket policy to buckets it creates to allow environments to write to the bucket and prevent accidental deletion
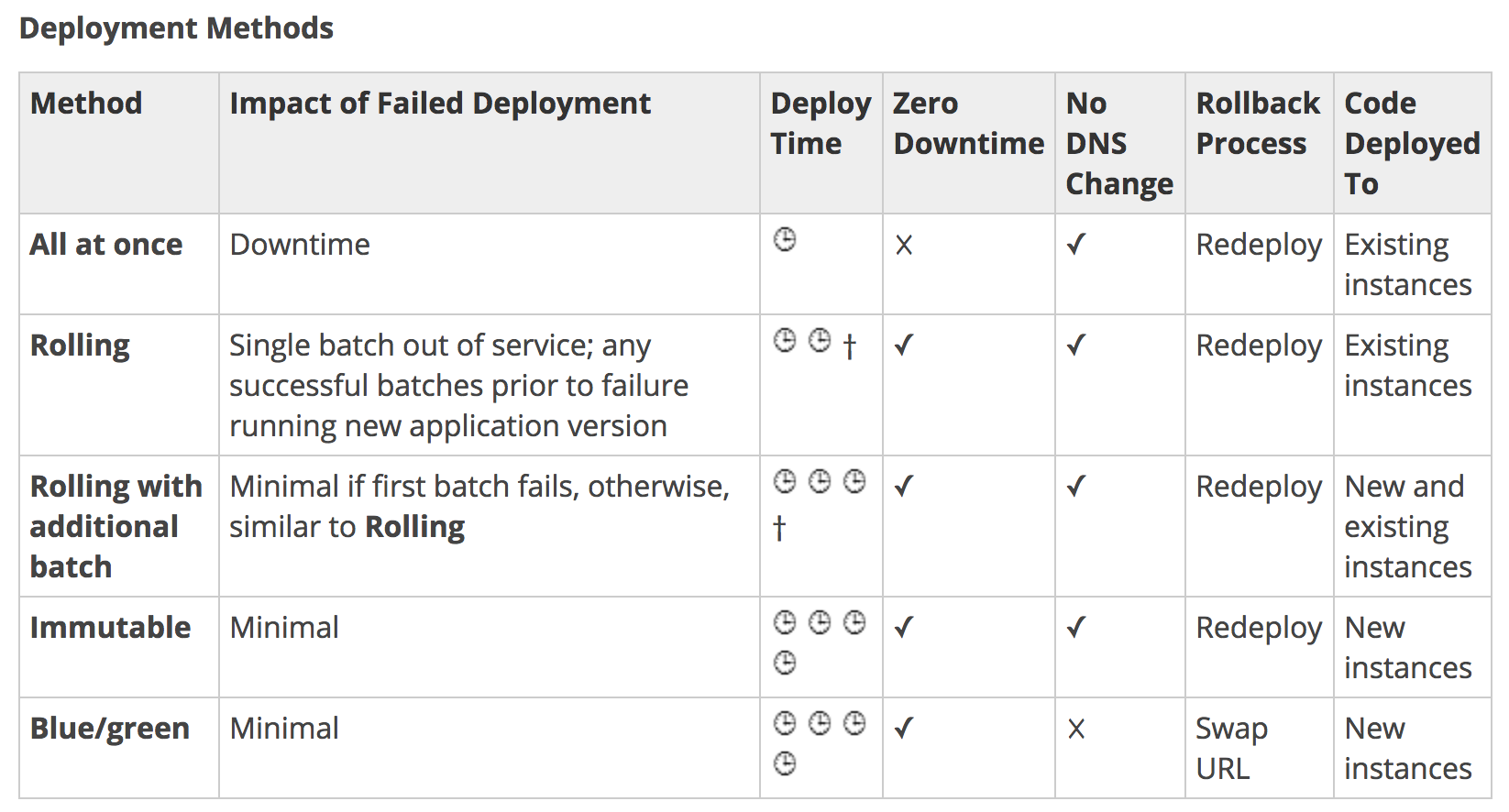
- All at Once
- performs an in-place deployment on all instances at the same time.
- is performed on existing instances and would lead to downtime as well as time to roll back changes.
- Rolling
- splits the environment instances into batches and deploys the application’s new version on the existing instance one batch at a time, leaving the rest of the environment instances running the old version.
- waits until all instances in a batch are healthy before moving on to the next batch.
- reduces downtime as all instances are not updated and if the health checks fail the deployment can be rollback.
- Rolling with an Additional batch
- similar to Rolling however it starts the deployment of the application’s new version on a new batch.
- does not impact the capacity and ensures full capacity during the deployment process.
- Immutable
- ensures the application source is always deployed to new instances.
- prevent issues caused by partially completed rolling deployments.
- provides minimal downtime and quick rollback.
- Blue Green
- suitable for deployments that depend on incompatible resource configuration changes or a new version that can’t run alongside the old version.
- implemented using the Swap Environment URLs feature that entails a DNS switchover.
AWS Certification Exam Practice Questions
- Questions are collected from Internet and the answers are marked as per my knowledge and understanding (which might differ with yours).
- AWS services are updated everyday and both the answers and questions might be outdated soon, so research accordingly.
- AWS exam questions are not updated to keep up the pace with AWS updates, so even if the underlying feature has changed the question might not be updated
- Open to further feedback, discussion and correction.
- An organization is planning to use AWS for their production roll out. The organization wants to implement automation for deployment such that it will automatically create a LAMP stack, download the latest PHP installable from S3 and setup the ELB. Which of the below mentioned AWS services meets the requirement for making an orderly deployment of the software?
- AWS Elastic Beanstalk
- AWS CloudFront
- AWS CloudFormation
- AWS DevOps
- What does Amazon Elastic Beanstalk provide?
- A scalable storage appliance on top of Amazon Web Services.
- An application container on top of Amazon Web Services
- A service by this name doesn’t exist.
- A scalable cluster of EC2 instances
- You want to have multiple versions of your application running at the same time, with all versions launched via AWS Elastic Beanstalk. Is this possible?
- However if you have 2 AWS accounts this can be done
- AWS Elastic Beanstalk is not designed to support multiple running environments
- AWS Elastic Beanstalk is designed to support a number of multiple running environments
- However AWS Elastic Beanstalk is designed to support only 2 multiple running environments
- A .NET application that you manage is running in Elastic Beanstalk. Your developers tell you they will need access to application log files to debug issues that arise. The infrastructure will scale up and down. How can you ensure the developers will be able to access only the log files?
- Access the log files directly from Elastic Beanstalk
- Enable log file rotation to S3 within the Elastic Beanstalk configuration
- Ask your developers to enable log file rotation in the applications web.config file
- Connect to each Instance launched by Elastic Beanstalk and create a Windows Scheduled task to rotate the log files to S3
- Your team has a tomcat-based Java application you need to deploy into development, test and production environments. After some research, you opt to use Elastic Beanstalk due to its tight integration with your developer tools and RDS due to its ease of management. Your QA team lead points out that you need to roll a sanitized set of production data into your environment on a nightly basis. Similarly, other software teams in your org want access to that same restored data via their EC2 instances in your VPC .The optimal setup for persistence and security that meets the above requirements would be the following. [PROFESSIONAL]
- Create your RDS instance as part of your Elastic Beanstalk definition and alter its security group to allow access to it from hosts in your application subnets. (Not optimal for persistence as the RDS is associated with the Elastic Beanstalk lifecycle and would not live independently)
- Create your RDS instance separately and add its IP address to your application’s DB connection strings in your code. Alter its security group to allow access to it from hosts within your VPC’s IP address block. (RDS is connected using DNS endpoint only)
- Create your RDS instance separately and pass its DNS name to your app’s DB connection string as an environment variable. Create a security group for client machines and add it as a valid source for DB traffic to the security group of the RDS instance itself. (Security group allows instances to access the RDS with new instances launched without any changes)
- Create your RDS instance separately and pass its DNS name to your DB connection string as an environment variable. Alter its security group to allow access to it from hosts in your application subnets. (Not optimal for security adding individual hosts)
- Your must architect the migration of a web application to AWS. The application consists of Linux web servers running a custom web server. You are required to save the logs generated from the application to a durable location. What options could you select to migrate the application to AWS? (Choose 2) [PROFESSIONAL]
- Create an AWS Elastic Beanstalk application using the custom web server platform. Specify the web server executable and the application project and source files. Enable log file rotation to Amazon Simple Storage Service (S3). (EB does not work with Custom server executable)
- Create Dockerfile for the application. Create an AWS OpsWorks stack consisting of a custom layer. Create custom recipes to install Docker and to deploy your Docker container using the Dockerfile. Create custom recipes to install and configure the application to publish the logs to Amazon CloudWatch Logs (although this is one of the option, the last sentence mentions configure the application to push the logs to S3, which would need changes to application as it needs to use SDK or CLI)
- Create Dockerfile for the application. Create an AWS OpsWorks stack consisting of a Docker layer that uses the Dockerfile. Create custom recipes to install and configure Amazon Kinesis to publish the logs into Amazon CloudWatch. (Kinesis not needed)
- Create a Dockerfile for the application. Create an AWS Elastic Beanstalk application using the Docker platform and the Dockerfile. Enable logging the Docker configuration to automatically publish the application logs. Enable log file rotation to Amazon S3. (Use Docker configuration with awslogs and EB with Docker)
- Use VM import/Export to import a virtual machine image of the server into AWS as an AMI. Create an Amazon Elastic Compute Cloud (EC2) instance from AMI, and install and configure the Amazon CloudWatch Logs agent. Create a new AMI from the instance. Create an AWS Elastic Beanstalk application using the AMI platform and the new AMI. (Use VM Import/Export to create AMI and CloudWatch logs agent to log)
- Which of the following groups is AWS Elastic Beanstalk best suited for?
- Those who want to deploy and manage their applications within minutes in the AWS cloud.
- Those who want to privately store and manage Git repositories in the AWS cloud.
- Those who want to automate the deployment of applications to instances and to update the applications as required.
- Those who want to model, visualize, and automate the steps required to release software.
- When thinking of AWS Elastic Beanstalk’s model, which is true?
- Applications have many deployments, deployments have many environments.
- Environments have many applications, applications have many deployments.
- Applications have many environments, environments have many deployments. (Applications group logical services. Environments belong to Applications, and typically represent different deployment levels (dev, stage, prod, forth). Deployments belong to environments, and are pushes of bundles of code for the environments to run.)
- Deployments have many environments, environments have many applications.
- If you’re trying to configure an AWS Elastic Beanstalk worker tier for easy debugging if there are problems finishing queue jobs, what should you configure?
- Configure Rolling Deployments.
- Configure Enhanced Health Reporting
- Configure Blue-Green Deployments.
- Configure a Dead Letter Queue (Elastic Beanstalk worker environments support SQS dead letter queues, where worker can send messages that for some reason could not be successfully processed. Dead letter queue provides the ability to sideline, isolate and analyze the unsuccessfully processed messages. Refer link)
- When thinking of AWS Elastic Beanstalk, which statement is true?
- Worker tiers pull jobs from SNS.
- Worker tiers pull jobs from HTTP.
- Worker tiers pull jobs from JSON.
- Worker tiers pull jobs from SQS. (Elastic Beanstalk installs a daemon on each EC2 instance in the Auto Scaling group to process SQS messages in the worker environment. Refer link)
- You are building a Ruby on Rails application for internal, non-production use, which uses MySQL as a database. You want developers without very much AWS experience to be able to deploy new code with a single command line push. You also want to set this up as simply as possible. Which tool is ideal for this setup?
- AWS CloudFormation
- AWS OpsWorks
- AWS ELB + EC2 with CLI Push
- AWS Elastic Beanstalk
- What AWS products and features can be deployed by Elastic Beanstalk? Choose 3 answers.
- Auto scaling groups
- Route 53 hosted zones
- Elastic Load Balancers
- RDS Instances
- Elastic IP addresses
- SQS Queues
- AWS Elastic Beanstalk stores your application files and optionally server log files in ____.
- Amazon Storage Gateway
- Amazon Glacier
- Amazon EC2
- Amazon S3
- When you use the AWS Elastic Beanstalk console to deploy a new application ____.
- Need to upload each file separately
- Need to create each file and path
- Need to upload a source bundle
- Need to create each file
References
AWS_Elastic_Beanstalk_Developer_Guide


Hi
For Q#1 , i thought that cloudformation would help to put template to create S3 , EC2 …etc ?
I am missing any ?
yup it helps define a templated approach for resource creation for AWS, which is option #2.
For Q#7.Which of the following groups is AWS Elastic Beanstalk best suited for?
My doubt: Why option “C” {Those who want to automate the deployment of applications to instances and to update the applications as required}…. is wrong?
Elastic Beanstalk doesn’t really automate your deployment. you still need CloudFormation to automated the process and make it repeatable. And Elastic Beanstalk can be used in CloudFormation.
Can you please explain for Question 6, how is the durability of logs handed with option g
Can’t see option g for Q#6, however both S3 and CloudWatch logs provide durable log storage.
Hi Jayendrapatil,
For Q.12, we can mention SQS queues also, as its been launched in worker tier environment.
Why RDS rather than SQS queue?
Please justify and correct me if I am wrong.
Thanks Rakesh, thats right. With Web tier you have the option for RDS as well which is linked to the Elastic Beanstalk lifecycle.
Hi Jayendrapatil,
I have two questions on Q.12 as following:
1, An EIP will be created when we create an web tier env. Here is a log from Elastic Beanstalk:
2019-01-17 13:30:30 UTC+1100 INFO Environment health has transitioned from Pending to Ok. Initialization completed 28 seconds ago and took 2 minutes.
2019-01-17 13:29:43 UTC+1100 INFO Successfully launched environment: Mytestebt-env-1
2019-01-17 13:29:42 UTC+1100 INFO Application available at Mytestebt-env-1.ktcqqu89dc.us-east-1.elasticbeanstalk.com.
2019-01-17 13:29:30 UTC+1100 INFO Added instance [i-053b7948c433c694e] to your environment.
2019-01-17 13:29:14 UTC+1100 INFO Waiting for EC2 instances to launch. This may take a few minutes.
2019-01-17 13:28:30 UTC+1100 INFO Environment health has transitioned to Pending. Initialization in progress (running for 15 seconds). There are no instances.
2019-01-17 13:28:09 UTC+1100 INFO Created EIP: 3.90.71.77
2019-01-17 13:27:53 UTC+1100 INFO Created security group named: awseb-e-38ppksfkbu-stack-AWSEBSecurityGroup-Y8HFFVEX456A
2019-01-17 13:27:32 UTC+1100 INFO Using elasticbeanstalk-us-east-1-126593132990 as Amazon S3 storage bucket for environment data.
2019-01-17 13:27:31 UTC+1100 INFO createEnvironment is starting.
2,Another questions is SQS: a worker tier env. will have a natice SQS Queue created with its own creation.
Could you please give me light on this question. thanks!
Elastic IP is internally used and not explicitly created. However, you are right for SQS queues which are created with Worker env.
I think it is a bad question because it doesn’t specify whether its a web or worker tier. It just says what products and features can can beanstalk deploy? Based on the current question, I would say RDS, SQS, Autoscaling, LoadBalancers. If they specified web tier, I’d say RDS. If they specified worker, I’d say SQS.
For Q6.
ElasticBeanstalk supports custom platforms with linux OS. ( option A is a correct statement )
Option E is correct only when it is specified that the onpremise environment is a AWS (VM import/export) supported virtualized enviroment. onpremise can also be a physical server.
Custom platform support for Elastic Beanstalk was enabled only in 2017, which is not surely taken into account by the exams. Thats why the answer option is E. However, with the new enhancement A does also make sense.
Hello Sir,
I’ve query regarding ‘adding user data to our application through elastic beanstalk’. I looked for various options on internet but unable to deploy those. Is there any ready application which is using user data, which I can refer and deploy it in my application. If yes please mail me on nikspalde@outlook.com. Could you please help me with this.
did you check .ebextensions ? that should help. let me know if not.